Injecting Knowledge into Pre-trained Models through Adapter
什么是Adapter[0]
“Adapter” refers to a set of newly introduced weights, typically within the layers of a transformer model. Adapters provide an alternative to fully fine-tuning the model for each downstream task, while maintaining performance. They also have the added benefit of requiring as little as 1MB of storage space per task!
Adapter,适配器指一组新引入的参数权重,通常在transformer模型的层内/间。适配器为每个下游任务提供了一种完全微调模型的替代方法,同时保持了性能。它们还有一个额外的好处,就是每个任务(的网络)只需要少量的存储空间.
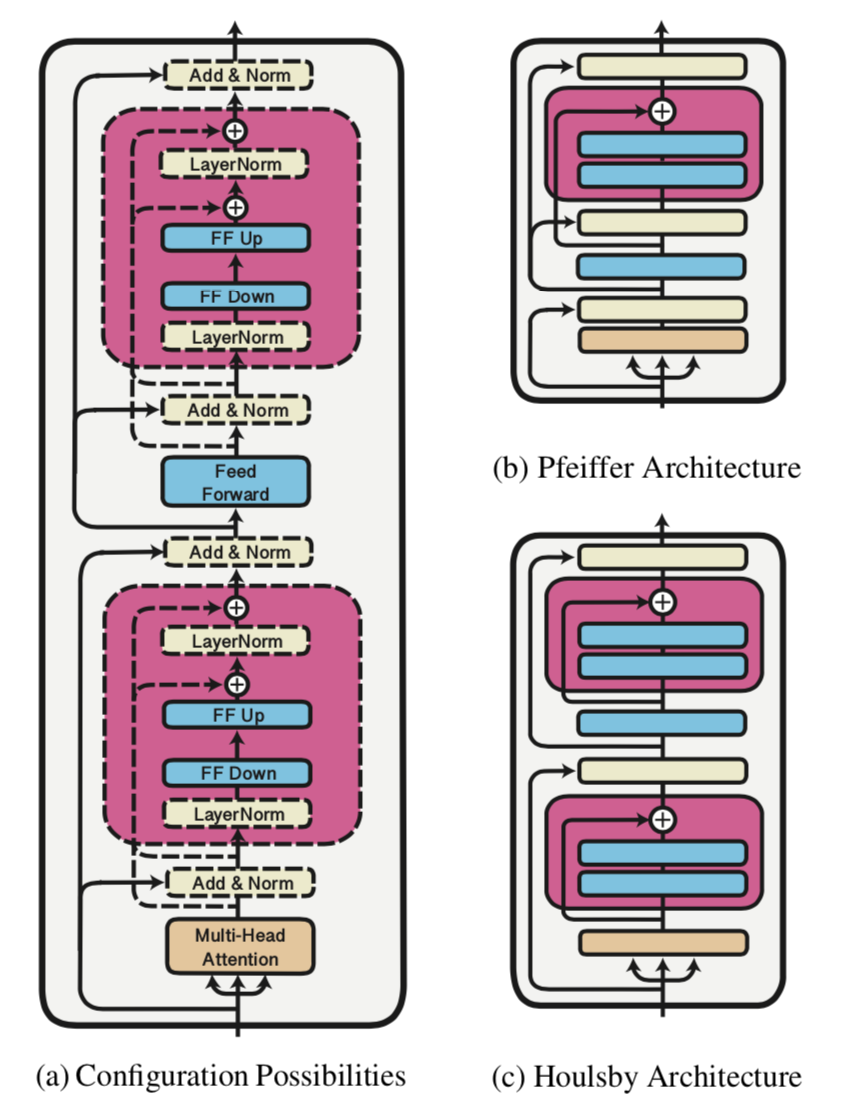
Adapter的结构(Architecture)
- A Two-layer feed-forward neural network with a bottleneck
- Down-Projection
- (may be a nonlinearity)
- Up-Projection
- Layer Norm
现有两种形式:Pfeiffer Architecture[2] 和 Houlsby Architecture[1]
Why Adapter【AdapterHub】
Adapters provide numerous benefits over fully fine- tuning a model such as scalability, modularity, and composition.
1\ Task-specific Layer-wise Representation Learning.
- 为了实现SotA的性能,大多数工作都对预训练模型进行整体微调;
- 而Adapter仅通过适应/调节每层的表示,就展示出了与整体模型微调相当的效果;
2\ Small, Scalable, Shareable
- 微调整体模型,需要将完整的结果模型存储,存储开销大;
- 可根据需要调整adapter内部的bottleneck size,极大地减少了需要存储的新的参数量;
3\ Modularity of Representations
- adapter学习编码任务相关信息,而不需要指定参数;
- adapter可作为模块化组建的原因:
- 由于适配器的封装布局(encapsulated placement),其中周围的参数是固定的,在每一层,适配器被迫学习与变压器模型的后续层兼容的输出表示。
- MAD-X的工作,成功将任务、语言独立训练的adapters进行了组合;
4\ Non-Interfering Composition of Information. (不冲突的信息组合)
- 跨任务共享信息
- 多任务学习的问题:
- 灾难性遗忘(catastrophic forgetting)[3]
- 序列迁移过程中,早期学习的知识被覆盖;
- 灾难性干扰(catastrophic interference)
- 增加新任务时,原有任务的性能下降;
- 灾难性遗忘(catastrophic forgetting)[3]
- Adapter封装的特性,不同的任务信息存储在了各自的参数中
引入Adapter的优势
- 减少了任务相关的(训练)参数量,不需要调整PLM参数;
- 不会在re-training整体模型时产生灾难性遗忘;
- 尽可能在减少参数量的同时,保持与MTL相同的性能;
- 可以序列化训练多任务;
- 增加新的任务时,不需要重新训练之前所有的子任务;
- 预训练/下游任务上学习到的知识可以以模块化的方式进行迁移;
Adapter Pre-train / Fine-tune 过程中的N个要点
- 与原始的PLM相比,需要调整的参数;
- PLM是否fixed,训练adapter;
- Adapter的预训练任务?
- PLM+Adapter组合之后,在下游任务上的使用,Task Specific Layer是什么?
- 在哪些阶段训练;
- 多任务训练?单任务训练?序列型训练?
NLP领域相关工作
- Parameter-Efficient Transfer Learning for NLP. ICML,2019.
- BERT and PALs: Projected Attention Layers for Efficient Adaptation in Multi-Task Learning. ICML,2019.
- K-ADAPTER: Infusing Knowledge into Pre-Trained Models with Adapters. 2020.
- Common Sense or World Knowledge? Investigating Adapter-Based Knowledge Injection into Pretrained Transformers. 2020.
- AdapterFusion: Non-Destructive Task Composition for Transfer Learning. 2020. (与MAD-X同一作)
- MAD-X: An Adapter-based Framework for Multi-task Cross-lingual Transfer. 2020. (与AdapterFuison同一作)
- Out-rageously Large Neural Networks: The Sparsely- Gated Mixture-of-Experts Layer. ICLR,2017.
- Simple, scalable adaptation for neural machine translation. EMNLP,2019.
- Intermediate-Task Transfer Learning with Pretrained Models for Natural Language Understanding: When and Why Does It Work? ACL,2020.
其他领域(CV)相关工作
- Learning multiple visual domains with residual adapters. NeurIPS,2017.
- On Self Modulation For Generative Adversarial Networks. ICLR,2019.