Title: Heterogeneous Graph Attention Networks for Semi-supervised Short Text Classification
Authors: Linmei Hu, Tianchi Yang, Chuan Shi, Houye Ji, Xiaoli Li.
Org.: BUPT, IIR(Singapore).
Published: EMNLP, 2019.
Motivation
Towards Shor Text Classification tasks, there are following Challenges:
- short text are semantically sparse and ambigous, lacking contexts [1];
- the labeled training data is limited, which leads to traditional and neural supervised methods ineffective;
- need to capture the importance of different information that is incoporated to address sparsity at multiple granularity levels, and reduce the weights of noisy information to achieve more accurate classification results;
This work
Propose a novel Heterogeneous GNN based method for semi-supervised short text classification:
- make full use of both limited labeled data and large unlabeled data by allowing information propagation through our automatically constructed graph;
- propose a flexible HIN framwork to model short texts;
- incorporate any additional information (e.g., entities and topics);
- capture the rich relations among the texts and the additional information;
- propose Heterogeneous Graph Attention networks (HGAT) to embed the HIN for the short text classifiaction;
- consider heterogeneity of different node types;
- a new dual-level attention mechanism;
- node-level: capture the importance of different neighboring nodes (reducing the weights of noisy information);
- type-level: capture the importance of different node (information) types to a current node;
Method
HIN for Short Texts
An example of HIN: 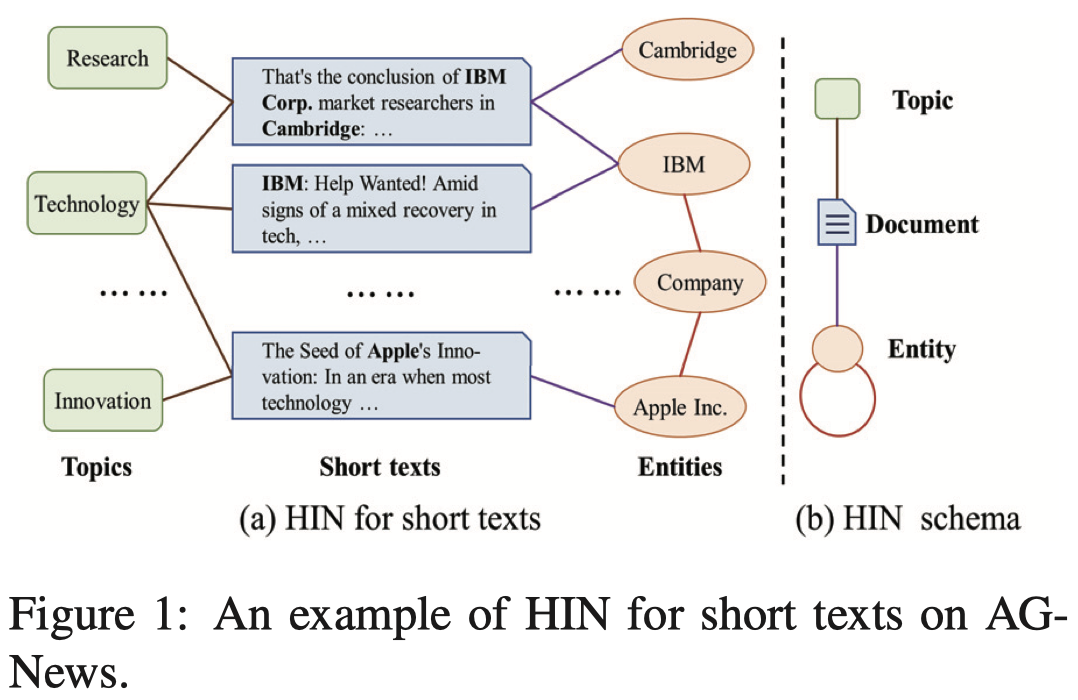
additional information:
- topics;
- entities;
Notation:
- HIN: $\mathcal{G} = (\mathcal{V},\mathcal{E})$
- $\mathcal{V} = D \cup T \cup E$
- Short Texts: $D = {d_1, …, d_m}$
- Topics: $T={t_1, …, t_K}$
- Entities: $E = {e_1,…,e_n}$
- $\mathcal{V} = D \cup T \cup E$
HIN constructing:
Topic: LDA
- each topic $t_i = (\theta_1,…,\theta_w)$
- w denotes the Vocabulary size
- is represented probability distribution over words
- Nodes: for each document, top-$P$ topics with the largest probabilities.
- Edges: the edge between a document and a topic is built if the document is assigned to the topic.
Entity:
- use TAGME[2] to recognize the entities in document and map them to wikipedia;
- entity representation:
- take an entity as a whole word and learn the entity embeddings using word2vec 2based on the Wikipedia corpus.
- Edge:
- edge between a document and an entity is built if the document contains the entity.
- relations between entities.
- to further enrich the semantics of short texts and advance the information propagation;
- if the similarity score (cosine similarity) between two entities is above a predefined threshold $\delta$, build an edge between them.
HGAT
HGAT model: 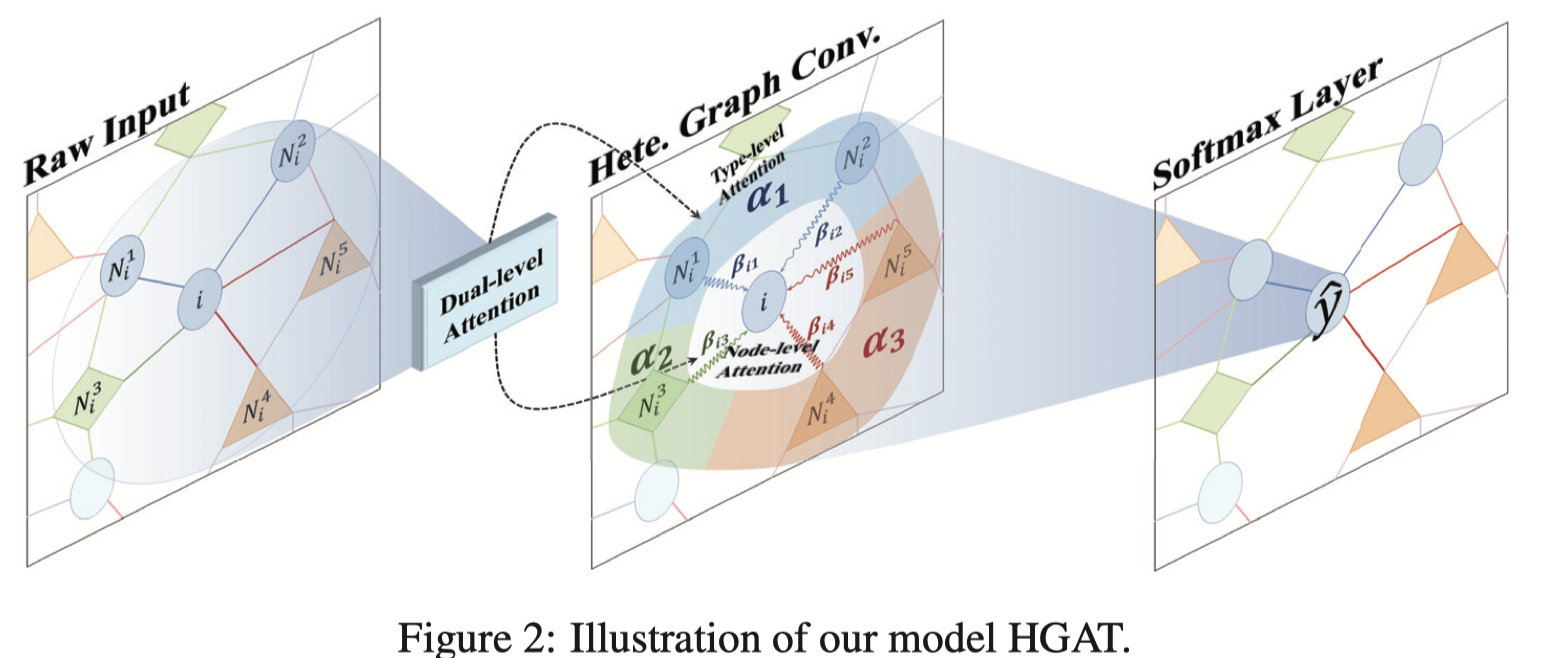
1.Heterogeneous Graph Convolution:
Node Features: $X\in \mathbb{R}^{|v| \times q}$, $x_v \in \mathbb{R}^q$
Adjacency Matrix: $A^{\prime} = A + I$ (add self-connections)
Degree Matrix: $M$, $M_{ii} = \sum_j A^{\prime}_{ij}$
GCN Layer-wise propagation rule:
- $H^{(l+1)} = \sigma (\tilde{A} \cdot H^{(l)} \cdot W^{(l)})$
- $\tilde{A} = M^{- \frac{1}{2}} A^{\prime} M^{- \frac{1}{2}}$ (symmetric normalized adjacency matrix)
- $\sigma$ = ReLU
- $H^{(l)} \in \mathbb{R}^{|v| \times q}$
Node Features:
- For document: use TF-IDF as features
- For topic: word distribution $s_t = \{\theta_i\}_{i=[1,w]}$
- For entity: concat its embedding and TF-IDF vector of its wikipedia description text;
GCN-HIN Layer-wise propagation rule:
- $H^{(l+1)} = \sigma (\sum_{\tau \in \Tau} \tilde{A}_{\tau} \cdot H^{(l)}_{\tau} \cdot W^{(l)}_{\tau})$
- $\Tau$: heterogeneous types
- $\tilde{A} \in \mathbb{R}^{|V| \times |V_{\tau}|}$ is the submatrix of $\tilde{A}$;
2.Dual-level Attention Mechanism
principle:
- the neighboring nodes of the same type may carry more useful information.
- different neighboring nodes of the same type could also have different importance.
Type-level: learns the weights of different types of neighboring nodes.
embedding of the type $\tau$: $h_{\tau} = \sum_{v\prime} \tilde{A}_{vv^{\prime}} h_{v^{\prime}} $
- sum of the neighboring node features $h_{v^{\prime}}$
- $v^{\prime} \in \mathcal{N}_v$ are with the type $\tau$;
type-level attention scores:
- $ a_{\tau} = \sigma( \mu^{T}_{\tau} \cdot [h_v || h_{\tau}] )$
- $h_v$ = current node embedding
- $||$ = concatenate
- $\sigma$ = Leaky ReLU
- $ a_{\tau} = \sigma( \mu^{T}_{\tau} \cdot [h_v || h_{\tau}] )$
- normalizing: $\alpha_{\tau} = \frac{ exp(a_{\tau}) }{ \sum_{\tau^{\prime} \in \Tau} exp(a_{\tau^{\prime}}) }$
Node-level: capture the importance of different neighboring nodes and reduce the weights of noisy nodes.
- a specific node $v$ with the type $\tau$ and its neighboring node $v^{\prime} \in \mathcal{N}_v$ with type $\tau^{\prime}$
- node-level attention scores:
- $b_{vv^{\prime}} = \sigma ( v^T \cdot \alpha_{\tau^{\prime}} [h_v || h_{v^{\prime}}] )$
- normalize: $\beta_{vv^{\prime}} = \frac{ exp(vv^{\prime}) }{ \sum_{i\in \mathcal{N}_v}exp(vi) }$
add Dual-level into GCN-HIN:
- $H^{(l+1)} = \sigma (\sum_{\tau \in \Tau} \mathcal{B}_{\tau} \cdot H^{(l)}_{\tau} \cdot W^{(l)}_{\tau})$
- $\mathcal{B}_{\tau}$: attention matrix from $\beta_{vv^{\prime}}$
Model Training
$Z = softmax(H^{(L)})$
- $H^{(L)}$ = short text embeddings
Objective:
- $L = - \sum_{i\in D_{train}} \sum_{j=1}^C Y_{ij}\cdot log Z_{ij} + \eta ||\Theta||_2 $
- $C$ = number of classes
- $\Theta$ = model parameters
- $\eta$ = regularization factor