Content
- Alignment over Heterogeneous Embedding for Question Answering. NAACL,2019.
- Careful Selection of Knowledge to solve Open Book Question Answering. ACL,2019.
- Quick and (not so) Dirty: Unsupervised Selection of Justification Sentences for Multi-hop Question Answering. EMNLP,2019.
AHE
Title: Alignment over Heterogeneous Embedding for Question Answering
Authors: Vikas Yadav, Steven Bethard, Mihai Surdeanu
Orig.: University of Arizona
Published: NAACL,2019.
Code: https://github.com/vikas95/AHE
1.Motivation
- some methods have fallen out of focus (strong unsupervised benchmarks), when comparing with neural approaches;
- e.g.: alignment approaches
- previous work adapted alignment methods to operate over word representations
- rely on uncontextualized word representations (GloVe)
- —> alignment approaches are more meaningful today after the advent of contextualized word representations
2.This Work
Alignment over Heterogeneous Embeddings (AHE): a simple, fast, and mostly unsupervised approach for non-factoid question answering (QA)
- uses an off-the-shelf information retrieval (IR) component to retrieve likely supporting paragraphs from a knowledge base (KB) given a question and candidate answer.
- aligns each word in the question and candidate answer with the most similar word in the retrieved supporting paragraph;
- weighs each alignment score with the IDF of the corresponding question/answer term;
- AHE’s overall alignment score is the sum of the IDF weighted scores of each of the question/answer term.
- AHE’s similarity/alignment function operates over embeddings that model the underlying text at different levels of abstraction:
- character: FLAIR -> unsupervised
- word: BERT/GloVe -> unsupervised
- sentence: InferSent -> supervised
- capture substantially different semantic information;
- a simple meta-classifier: learns how much to trust the predictions over each representation, further improves the performance of unsupervised AHE;
- Target Dataset:
- ARC: multiple-choice QA;
- WikiQA: answer selection (select the sentences containing the correct answers);
3.Method
The core component of our approach computes the score of a candidate answer by aligning two texts.
Inputs:
- multiple-choice task:
- sent1: question concatenated with the candidate answer;
- sent2: supporting paragraph;
- answer selection task:
- sent1: question;
- sent2: candidate answer;
Overall architecture:
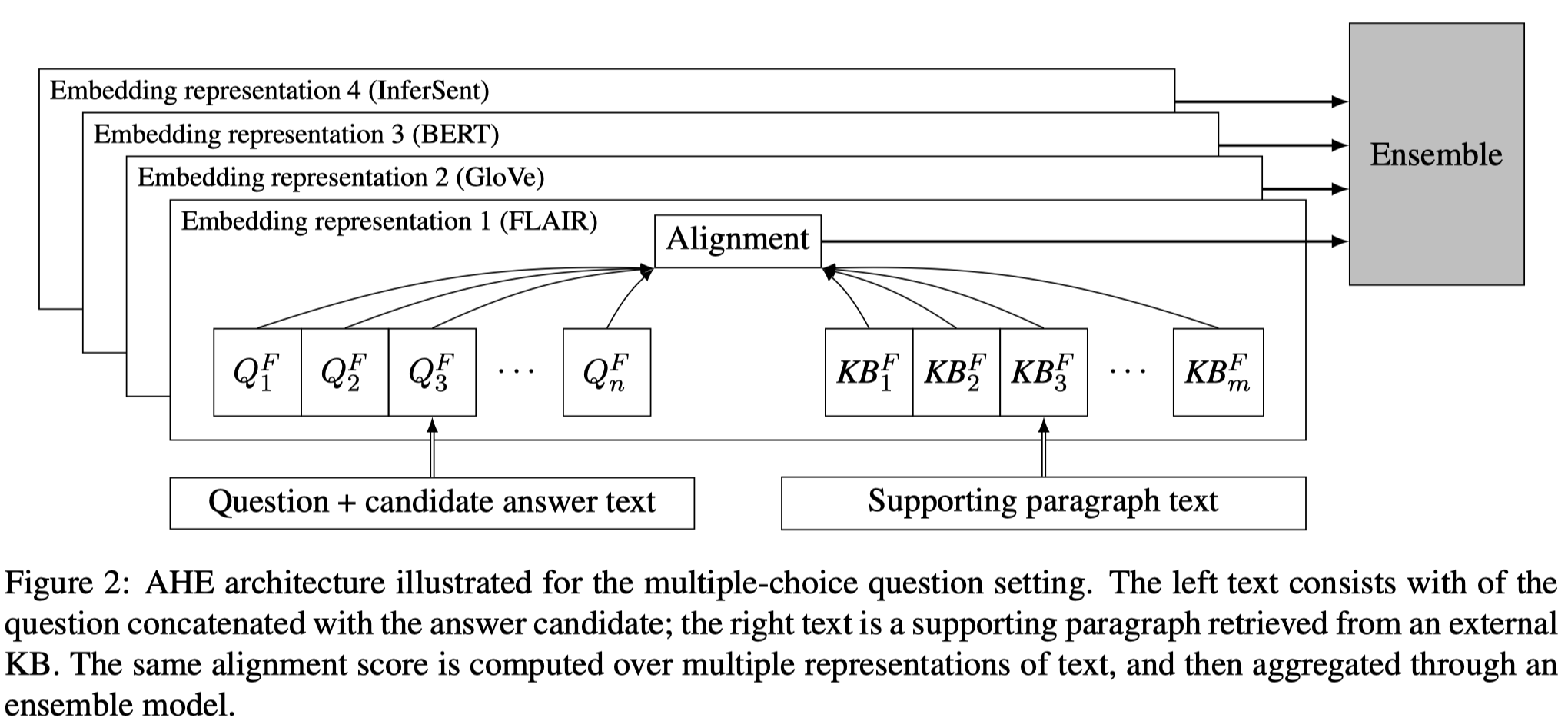
3.1 Retrieve Supporting Paragraphs
- retrieve supporting information from external KBs using Lucene, an off-the-shelf IR system
- query: question + answer candidate
- ranking function: BM25
- top C (C=20)
- retrieve corpus: ARC corpus
- IDF of each query term $q_i$:
- $idf(q_i) = log(\frac{N-docfreq(q_i) + 0.5}{docfreq(q_i) + 0.5})$
- $N$ is the number of documents;
- $docfreq(q_i)$ is the number of documents that contain $q_i$ ;
- $idf(q_i) = log(\frac{N-docfreq(q_i) + 0.5}{docfreq(q_i) + 0.5})$
3.2 Alignment Method
Alignment Algorithm: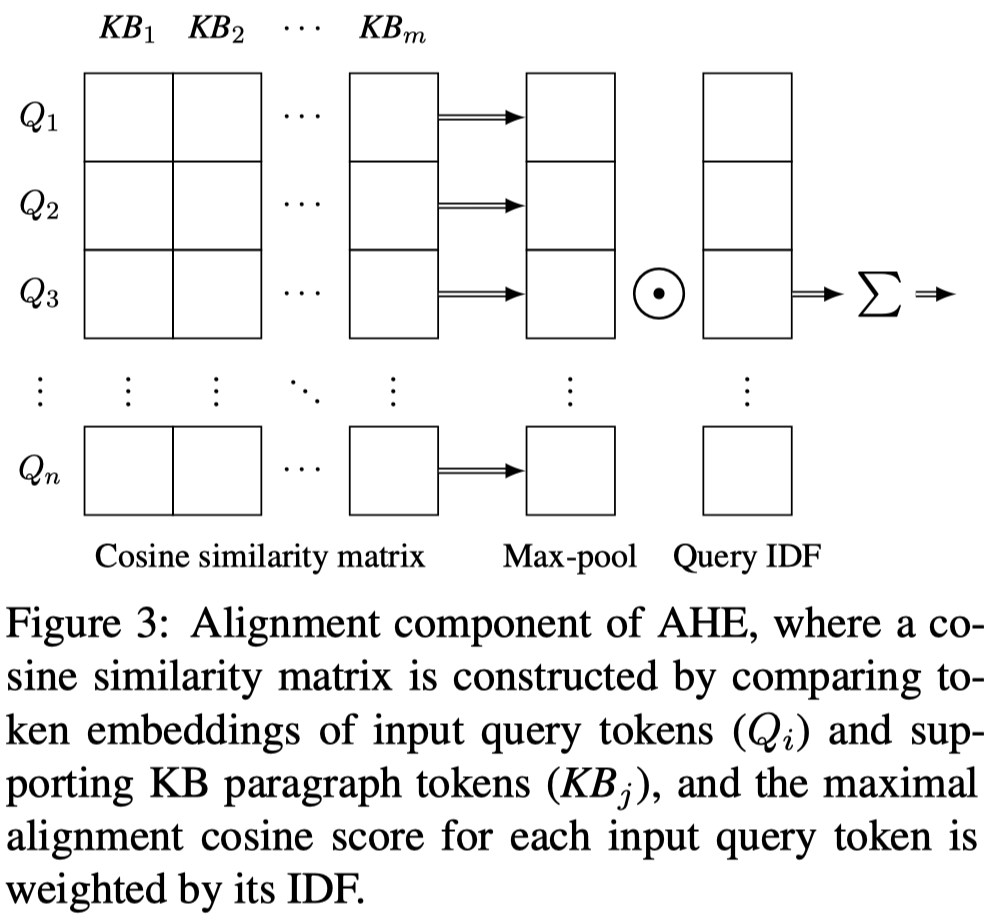
- compute each query token with every token in the given KB paragraph using cosine similarity of the two embedding vectors;
- $cosSim(q_i, p_k) = \frac{\overrightarrow{q_i} \cdot \overrightarrow{p_k}}{ ||\overrightarrow{q_i}|| \cdot ||\overrightarrow{p_k}|| }$
- max-pooling layer over cosine similarity matrix is used to retrieve the most similar token in the supporting passage for each query token;
- $align(q_i,P_j) = max_{k=1}^{|P_j|} cosSim(q_i,p_k)$
- max-pooled vector of similarity scores is multiplied with the vector containing the IDF values of the query tokens;
- the resultant vector is summed to produce the overall alignment score $s$ for the given query $Q_a$ and the supporting paragraph $P_j$;
- $s(Q_a, P_j) = \sum_{i=1}^{|Q_a|} idf(q_i) \cdot align(q_i, P_j)$
InferSent: $s(Q_a, P_j) = softmax(\overrightarrow{Q_a} \cdot \overrightarrow{P_j})$
Aggregate the retrieved paragraph:
- Max: $S(cand_a) = max_{j=1}^{C}( s(Q_a, P_j) )$
- Weighted Average: $S(cand_a) = \sum_{j=1}^{C} \frac{1}{j}( s(Q_a, P_j) )$
- On ARC:
- the max strategy is better for ARC Challenge;
- the weighted average is better for ARC Easy;
3.3 Multiple Representation of Text
Four different embedding representations that model the text at different levels of abstraction:
- character, word, and sentence
Character-based Embeddings:
- FLAIR contextual character language model [1]
- $w_i^{FLAIR} = [h_{t_i+1-1}^f; h_{t_i-1}^b] \in \mathbb{R}^{4096}$
- forward and backward of LSTM
- $t_i$ the character offset of the $i^{th}$ token;
Word-based Embeddings:
- BERT
- $w_i^{BERT} = [Layer_{-1},…,Layer_{-4}] \in \mathbb{R}^{4096}$
- the last four layers
- GloVE
- dimension = 300
Sentence-based:
- InferSent:
- trained InferSent on our data by maximizing the inference probability from the input query to the supporting paragraph.
- dimension:
- WikiQA: 128
- ARC: 384
3.4 Ensemble Strategies over Representations
Aggregate the scores of candidate answers over the four different embedding representations using an unsupervised variant of the NoisyOr formula to compute the overall score for answer candidate $i$:
- $M$, total number of representations
- $S_i^m$, score of answer candidate $i$ under representation $m$
- $\alpha^m$, a hyperparameter used to dampen peaky distributions of answer probabilities;
- =1
- infersent = 0.2
Supervised Meta Multi-classifier: aims to learn the aggregation function directly from data
- 2 fully connected dense layers of hidden size 16 and K, and a softmax layer;
- input vector size = $M \times K$
- K is the maximum number of candidate answers;
- activation function: tanh;
- for ARC, use an extra position in the input vector to indicate the grade of the corresponding exam question (provided in the dataset) with the intuition that the meta-classifier will learn to trust different representations for different grade levels.
4.Experiments
Reference to the Paper
Careful Selection
Title: Careful Selection of Knowledge to solve Open Book Question Answering
Authors: Pratyay Banerjee, Kuntal Kumar Pal, Arindam Mitra, Chitta Baral
Orig.: Arizona State University
Published: ACL,2019.
1.Motivation
Towards Open Book Question Answering task:
- questions are expected to be answered with respect to a given set of open book facts, and common knowledge about a topic;
- requires deeper reasoning involving linguistic understanding as well as reasoning with common knowledge;
Challenges in OpenBookQA (The open book part is much larger (than a small paragraph) and is not complete as additional common knowledge may be required.):
- finding the relevant facts in an open book is a challenge;
- finding the relevant common knowledge using the IR front end is bigger challenge;
- can be misled by distractions;
- reasoning involving both facts from open book and common knowledge leads to multi-hop reasoning with respect to natural language text, which is also a challenge.
2.This Work
Address the first two challenges:
- improve on knowledge extraction from the OpenBook present in the dataset.
- use semantic textual similarity models that are trained with different datasets for this task;
- propose natural language abduction to generate queries for retrieving missing knowledge;
- use Information Gain based Re-ranking to reduce distractions and remove redundant information;
- provide an analysis of the dataset and the limitations of BERT Large model for such a question answering task.
Key Approach:
- abductive information retrieval (IR);
- information gain based re-ranking;
- passage selection and weighted scoring;
A key aspect of this work’s approach is to accurately hunt the needed knowledge facts from the OpenBook knowledge corpus and hunt missing common knowledge using IR.
3.Method
Approach Overall:
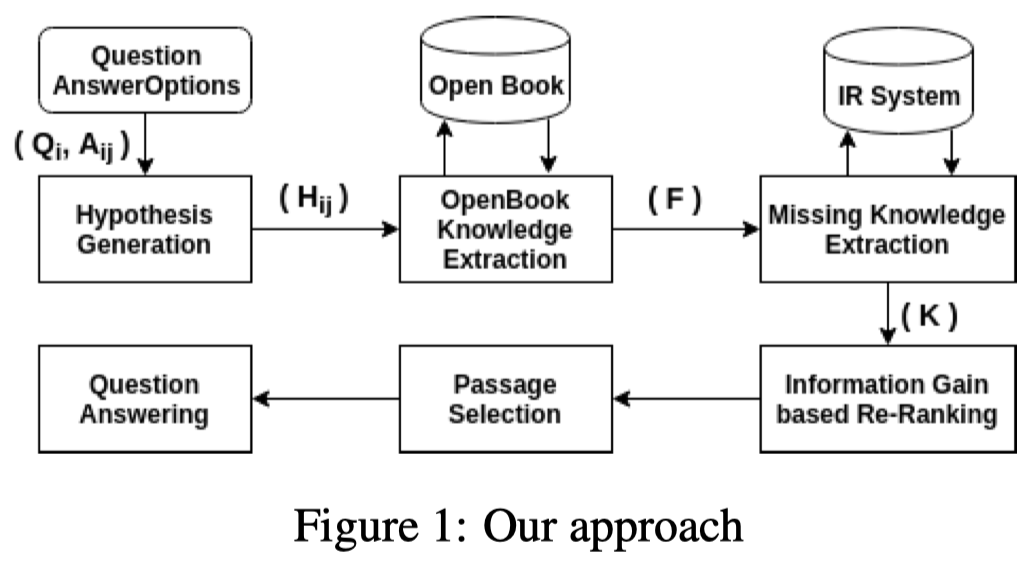
The proposed approach involves six main modules:
- Hypothesis Generation,
- OpenBook Knowledge Extraction,
- Abductive Information Retrieval,
- Information Gain based Re-ranking,
- Passage Selection,
- Question Answering.
Example of the proposed approach:

Hypothesis Generation:
- generate a hypothesis $H_{ij}$ for the $i$-th question and $j$-th answer option ($j\in \{1,2,3,4\}$);
OpenBook Knowledge Extraction:
- retrieve appropriate knowledge $F_{ij}$ for a given hypothesis using semantic textual similarity, from the OpenBook knowledge corpus $F$;
Abductive Information Retrieval:
- system abduces missing knowledge from $H_{ij}$ and $F_{ij}$;
- system formulates queries to perform IR to retrieve missing knowledge $K_{ij}$.
Information Gain based Re-ranking and Passage Selection:
- create a knowledge passage $P_{ij}$
Question Answering:
- system uses $P_{ij}$ to answer the questions using a BERT Large based MCQ model;
3.1 Hypothesis Generation
- for questions with wh words, use the rule-based model[5].
- for the rest of the questions, concatenate the questions with each of the answers to produce the four hypotheses.
3.2 OpenBook Knowledge Extraction
- a textual similarity model is trained in a supervised fashion on two datasets
- use large-cased BERT
- STS-B
- gold OpenBookQA facts
- first find the similarity of the OpenBook $F$ facts with respect to each other using the BERT model trained on STS-B dataset;
- assign a score of $5.0$ for the gold $\hat{F}_i$ fact for a hypothesis;
- then sample different facts from the OpenBook and assign the STS-B similarity scores between the sampled fact and the gold fact $\hat{F}_i$ as the target score for that fact $F_{ij}$ and $H_{ij}$.
3.3 Natural Language Abduction and IR
To search for the missing knowledge, need to know what we are missing.
- use abduction to figure that out;
- Abduction: both the observation (hypothesis) and the domain knowledge (known fact) is represented in a formal language from which a logical solver abduces possible explanations (missing knowledge)
- propose three models
Word Symmetric Difference Model
- $K_{ij} = (H_{ij} \cup F_{ij}) \backslash (H_{ij} \cap F_{ij}), \forall j \in \{1,2,3,4\}$
Supervised Bag of Words Model
- select words which satisfy: $P(w_n \in K_{ij}) > \theta$
- $w_n \in \{ H_{ij} \cup F_{ij} \}$
- To learn this probability, create a task:
- where the words similar (cosine similarity useing SpaCy)to the words in the gold missing knowledge $\hat{K}_i$ (provided in the dataset) are labelled as positive class;
- all the other words not present in $\hat{K}_i$ but in $H_{ij} \cup F_{ij}$ are labelled as negative class.
- train a binary classifier using BERT Large with one additional feed forward network for classification.
- $\theta = 0.4 $
CopyNet Seq2Seq Model
- to generate, instead of predict, the missing knowledge given, the hypothesis H and knowledge fact from the corpus F.
- choose from multiple generated knowledge which provided maximum overlap score:
- $overlap_score = \frac{\sum_i count((\hat{H}_{i} \cup F_{i}) \cap K_i )}{\sum_i count(\hat{K}_i)}$
Word Union Model:
- To see if abduction helps, compare the above models with a Word Union Model
- use the set of unique words from both the hypothesis and OpenBook knowledge as candidate keywords.
- $K_{ij} = (H_{ij} \cup F_{ij})$
3.4 Information Gain based Re-ranking
Observation: BERT QA model gives a higher score if similar sentences are repeated, leading to wrong classification.
- Thus: introduce Information Gain based Re-ranking to remove redundant information.
- use the same BERT Knowledge Extraction model (3.2) Trained on OpenBookQA data;
- to do an initial ranking of the retrieved missing knowledge $K$;
- the scores of this knowledge extraction model is used as relevancy score, $rel$.
To extract the top-10 missing knowledge $K$, define a redundancy score $red_{ij}$:
- as the maximum cosine similarity $sim$ between
- the previously selected missing knowledge, in the previous iterations till $i$,
- and the candidate missing knowledge ${K_j}$:
- $red_{ij}(K_j) = max(red_{i-1,j}(K_j), sim(K_i,K)j))$
- $randscore = (1- red_{ij}(K_j)) \ast rel(K_j) $
Missing Knowledge Selection:
- first take the missing knowledge with the highest $rel$ score.
- from the subsequent iteration, we compute the redundancy score with the last selected missing knowledge for each of the candidates and then rank them using the updated $rankscore$.
- select the top-10 missing knowledge for each $H_{ij}$;
3.5 Question Answering
3.5.1 Question-Answering Model
finetune BERT MCQA
To be within the restrictions of BERT max input length, create a passage for each of the answer options, and score for all answer options against each passage (Corpus $F$).
- for each answer option $A_j$ (?), create a passage $P_j$ and score against each of the answer options $A)i$
- To compute the final score for the answer, we sum up each individual scores.
- $Pr(Q,A_i) = \sum_{j=1}^4 score(P_j, Q, A_i)$
- $A = argmax_A Pr(Q, A_i)$
3.5.2 Passage Selection and Weighted Scoring:
- In the first round, score each of the answer options using a passage created from the selected knowledge facts from corpus F.
- For each question, ignore the passages of the answer options which are in the bottom two.
- In the second round, score for only those passages which are selected after adding the missing knowledge $K$.
- Weighted Scoring
- Assume that the correct answer has the highest score in each round;
- multiply the scores obtained after both rounds;
- Define the combined passage selected scores and weighted scores as follows:
- $Pr(F, Q, A_i) = \sum_{j=1}^4 score(P_j, Q, A_i)$
- $P_j$ from extracted OpenBook knowledge $F$
- the top-2 passages are selected based on the scores of $Pr(F, Q, A_i)$
- $Pr(F\cup K, Q, A_i) = \sum_{k=1}^4 \delta \ast score(P_k, Q, A_i)$
- $\delta=1$ for the top two scores;
- $\delta=0$ for the rest;
- $P_k$ is the passage created using both the facts and missing knowledge
- $Pr(F, Q, A_i) = \sum_{j=1}^4 score(P_j, Q, A_i)$
- Final weighted score:
- $wPR(Q,A_i) = Pr(F, Q, A_i) \ast Pr(F\cup K, Q, A_i)$
- $A = argmax_{A} wPr(Q,A_i)$
4.Experiments
Reference to the Paper
AutoROCC
Title: Quick and (not so) Dirty: Unsupervised Selection of Justification Sentences for Multi-hop Question Answering
Authors: Vikas Yadav, Steven Bethard, Mihai Surdeanu
Orig.: University of Arizona
Published: EMNLP,2019.
Code: https://github.com/vikas95/AutoROCC
1.Motivation
- For complex NLP task, such as QA, human readable explanations of the inference process have been proposed as a way to interpret QA models;
- The task of selecting justification sentences is complex for multi-hop QA, because of the additional knowledge aggregation requirement;
- more effort must be dedicated to explaining their inference process.
Related Work
The selection of justification sentences can be classified into roughly four categories:
- supervised approaches that require training data to learn how to select justification sentences;
- use entailment resources to train components for selecting sentences for QA [6];
- explicitly focused on training sentence selection components for QA models [7][8][9];
- when the gold justification sentences are not provided:
- retrieve justifications from structured KBs;
- IR systems coupled with denoising components [9];
- treat justification as latent variables and learn jointly how to answer questions and how to select justification from questions and answers alone;
- rely on reinforcement learning or PageRank to learn how to select justification sentences without explicit training data;
- use end-to-end (mostly RNNs with attention mechanisms) QA architectures for learning to pay more attention on better justification sentences;
- rely on information retrieval to select justification sentences;
- do not use justification sentences at all;
The detailed works please refer to the original paper.
2.This Work
Propose an unsupervised, non-parametric strategy (ROCC) for the selection of justification sentences from unstructured knowledge bases for Multi-Hop QA:
- maximizes the Relevance of the selected sentences;
- minimizes the Overlap between the selected facts;
- maximizes the Coverage of both question and answer;
- can be coupled with any supervised QA approach;
- account for more intentional knowledge aggregation;
Target Dataset: (a) ARC; (b) MultiRC;
Example:
Brief introduction of the ROCC:
- first creating $\left( \begin{array}{c} n \\ k \end{array} \right)$ justification sets from the top-$n$ sentences selected by BM25 IR model;
- $k$ ranges from $2$ to $n$;
- $n = 20$;
- then ranking them all by a formula that combines the three criteria above;
- the set with the top score becomes the set of justifications output by ROCC for a given question and candidate answer;
3.Method
ROCC, coupled with a QA system, operates in the following steps: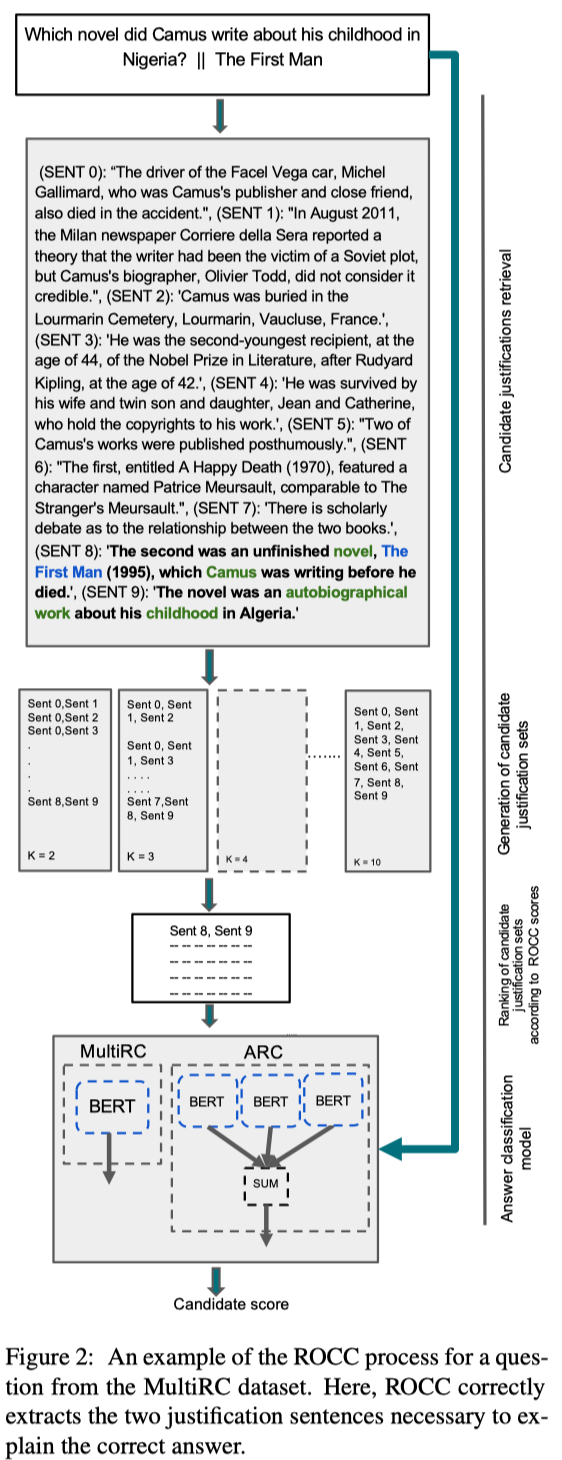
3.1 Retrieval of candidate justification sentences
The overall score for a given justification set $P_i$ is calculated as:
- $S(P_i) = \frac{R}{\epsilon + O(P_i) } \cdot (\epsilon + C(A)) \cdot (\epsilon + C(Q))$
- $\epsilon = 1$ to avoid zeros;
Relevance (R)
- use BM25 IR model to estimate the relevance of each justification sentence to a given question and candidate answer;
- IR query: concatenate the question and candidate answer;
- the arithmetic mean of BM25 scores over all sentences in a given justification set gives the value of R for the entire set;
Overlap (O)
- to ensure diversity and complementarity between justification sentences;
- overlap between all sentence pairs in a given group;
- minimizing this score reduces redundancy and encourages the aggregated sentences to address different parts of the question and answer:
- $O(S) = \frac{ \sum_{s_i \in S} \sum_{s_j \in S - s_i} \frac{ |t(s_i) \cap t(s_j)| }{ max(|t(s_i)|,|t(s_j)|) } }{ \left( \begin{array}{c} |S| \\ 2 \end{array} \right) }$
- $S$ is the given set of justification sentences;
- $s_i$ is the $i^{th}$ sentence in $S$;
- $t(s_i)$ is the set of unique terms in sentence $s_i$;
- divide by $\left( \begin{array}{c} n \\ k \end{array} \right)$ to normalize across different sizes of justification sets;
Coverage (C)
- complementing the overlap score, Coverage measures the lexical coverage of the question and the answer texts by the given set of justification $S$;
- $C$ is weighted by the IDF of questions and answer terms;
- maximizing this value encourages the justifications to address more of the meaningful content mentioned in the question ($X=Q$) and the answer ($X=A$);
- $C(X) = \frac{ \sum_{t=1}^{|C_t(X)|} IDF[C_t(X)[t]] }{ |t(X)| }$
- $C_t(X) = \bigcup_{s_i \in S} t(X) \cap t(s_i)$
- $t(X)$ is the unique terms in $X$;
- $C_t(X)$ is the set of all unique terms in $X$ that are present in any of the sentences of the given justification set.
3.2 Generation of candidate justification sets
ROCC ranks sets of justification sentences rather than individual sentences.
- create candidate justification sets by generating $\left( \begin{array}{c} n \\ k \end{array} \right)$ groups of sentences from the previous top-$n$ sentences, using multiple values of $k$;
3.3 Ranking of candidate justification sets
ROCC score estimates the likelihood that this group of justification explains the given answer.
- rank the justification sets in descending order of ROCC score;
- choose the top set as the group of justification that is the output of ROCC for the given question and answer.
- In MultiRC, rearrange the justification sentences according to their original indexes in the given passage to bring coherence in the selected sequence of sentences.
3.4 Answer Classification
ROCC can be coupled with any supervised QA component for answer classification (BERT in this work).
- Justification sentences in the reading comprehension (MultiRC) come from the same passage and their sequence is likely to be coherent;
- concatenate them into a single passage;
- use a single BERT instance for classification.
- Justification sentences retrieved from an external KB (ARC) may not form a coherent passage when aggregated;
- classify each justification sentence separately (together with the question and candidate answer);
- then average all these scores to produce a single score for the candidate answer;
- The first text consists of the concatenated question and answer, and the second text consists of the justification text.
4.Experiments
AutoROCC: $k$ is selected automatically.
Alignment ROCC
- to understand the dependence between ROCC and exact lexical match:
- compare the justification selection performance of ROCC when its score components are computed based on lexical match vs. semantic alignment match
Reference to the Paper
- 1.Alan Akbik, Duncan Blythe, and Roland Vollgraf. 2018. Contextual string embeddings for sequence labeling. In Proceedings of the 27th International Conference on Computational Linguistics, pages 1638–1649. ↩
- 2.Todor Mihaylov, Peter Clark, Tushar Khot, and Ashish Sabharwal. 2018. Can a suit of armor conduct electricity? a new dataset for open book question answering. In EMNLP. ↩
- 3.Tony Jenkins. 1995. Open Book Assessment in Computing Degree Programmes. Citeseer. ↩
- 4.J Landsberger. 1996. Study guides and strategies. ↩
- 5.Dorottya Demszky, Kelvin Guu, and Percy Liang. 2018. Transforming question answering datasets into natural language inference datasets. arXiv preprint arXiv:1809.02922. ↩
- 6.Harsh Trivedi, Heeyoung Kwon, Tushar Khot, Ashish Sabharwal, and Niranjan Balasubramanian. 2019. Repurposing entailment for multi-hop question answering tasks. arXiv preprint arXiv:1904.09380. ↩
- 7.Sewon Min, Victor Zhong, Richard Socher, and Caiming Xiong. 2018. Efficient and robust question answering from minimal context over documents. arXiv preprint arXiv:1805.08092. ↩
- 8.Yankai Lin, Haozhe Ji, Zhiyuan Liu, and Maosong Sun. 2018. Denoising distantly supervised open-domain question answering. In Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 17361745. ↩
- 9.Hai Wang, Dian Yu, Kai Sun, Jianshu Chen, Dong Yu, Dan Roth, and David McAllester. 2019. Evidence sentence extraction for machine reading comprehension. arXiv preprint arXiv:1902.08852. ↩
- 10.* lexical match: the approach used throughout the paper up to this point; * semantic alignment match: relaxes the requirement for lexical match; * i.e., two tokens are considered to be matched when the cosine similarity of their embedding vectors is larger than a margin; * Table 7 shows the alignment-based ROCC indeed performs better than the ROCC that relies on lexical match; * but the improvements are not large; ↩
- 10.Vikas Yadav, Rebecca Sharp, and Mihai Surdeanu. 2018. Sanity check: A strong alignment and information retrieval baseline for question answering. In The 41st International ACM SIGIR Conference on Research & Development in Information Retrieval, pages 1217–1220. ACM. ↩