Title: K-ADAPTER: Infusing Knowledge into Pre-Trained Models with Adapters
Authors: Ruize Wang, et. al.
Org.: MSRA, Fudan University.
Published: unpublished
Motivation
本文研究问题:向大型预训练(语言)模型中注入知识。
尽管预训练模型(GPT、BERT、XLNET等模型)取得了很大的进展,最近的一些研究[1][2][3]表明,以无监督方式训练的语言模型很难捕获丰富的知识;
先前的工作[4][5][6][7][8][9]主要集中与通过设计knowledge-driven的训练目标来增强standard LM的训练目标,然后通过多任务学习的方式更新模型的全部参数;
这样的方式存在几点限制:
- 无法进行终身学习(continual learning)
- 模型的参数在引入新知识的时候需要重新训练;
- 对于已经学到的知识来说,会造成灾难性遗忘(catastrophic forgetting);
- 模型产生的是耦合的表示(entangled representations)
- 为进一步探究引入不同知识的作用/影响带来困难;
Note:这篇文章中Related Work部分对于向PLM中注入知识这一方向进行了很好的梳理,推荐阅读原文Sec. 2,相关工作的区别主要在于 a) knowledge sources 和 b) training objective;
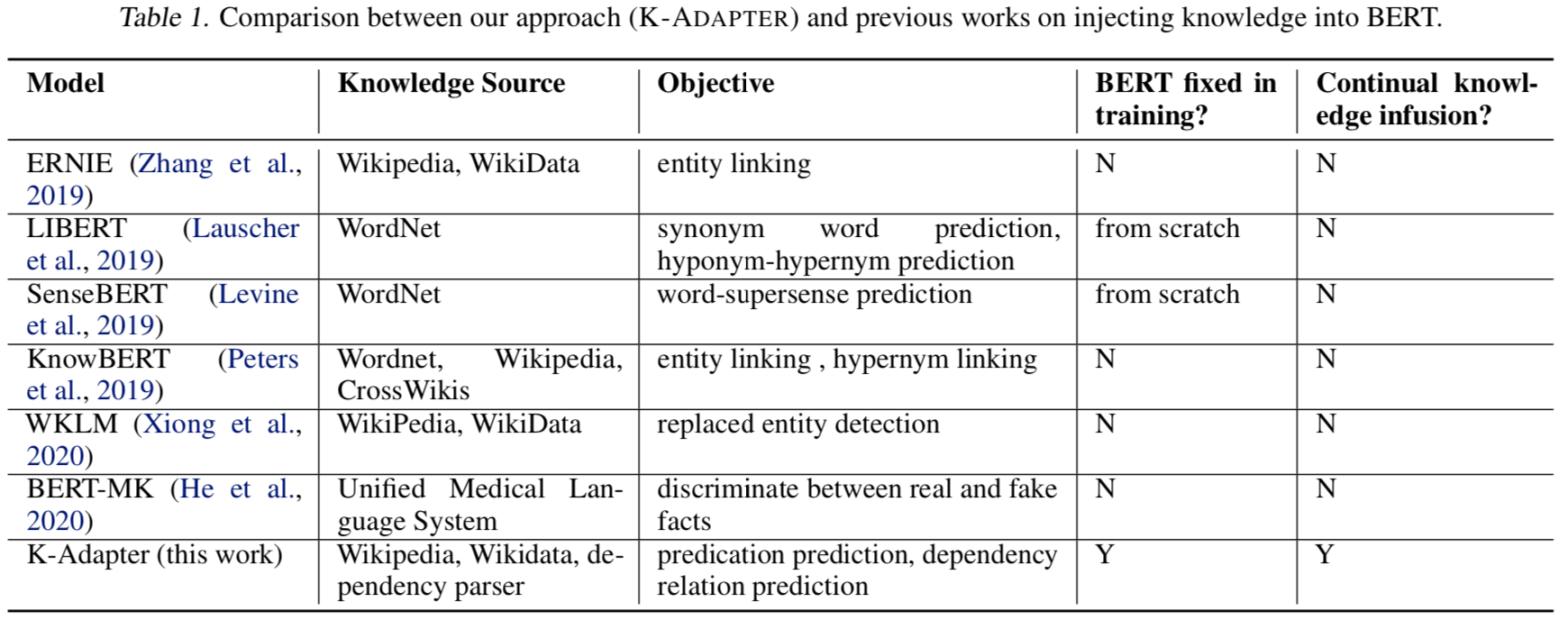
Table-1:K-Adapter 和 先前工作的对比;
This Work
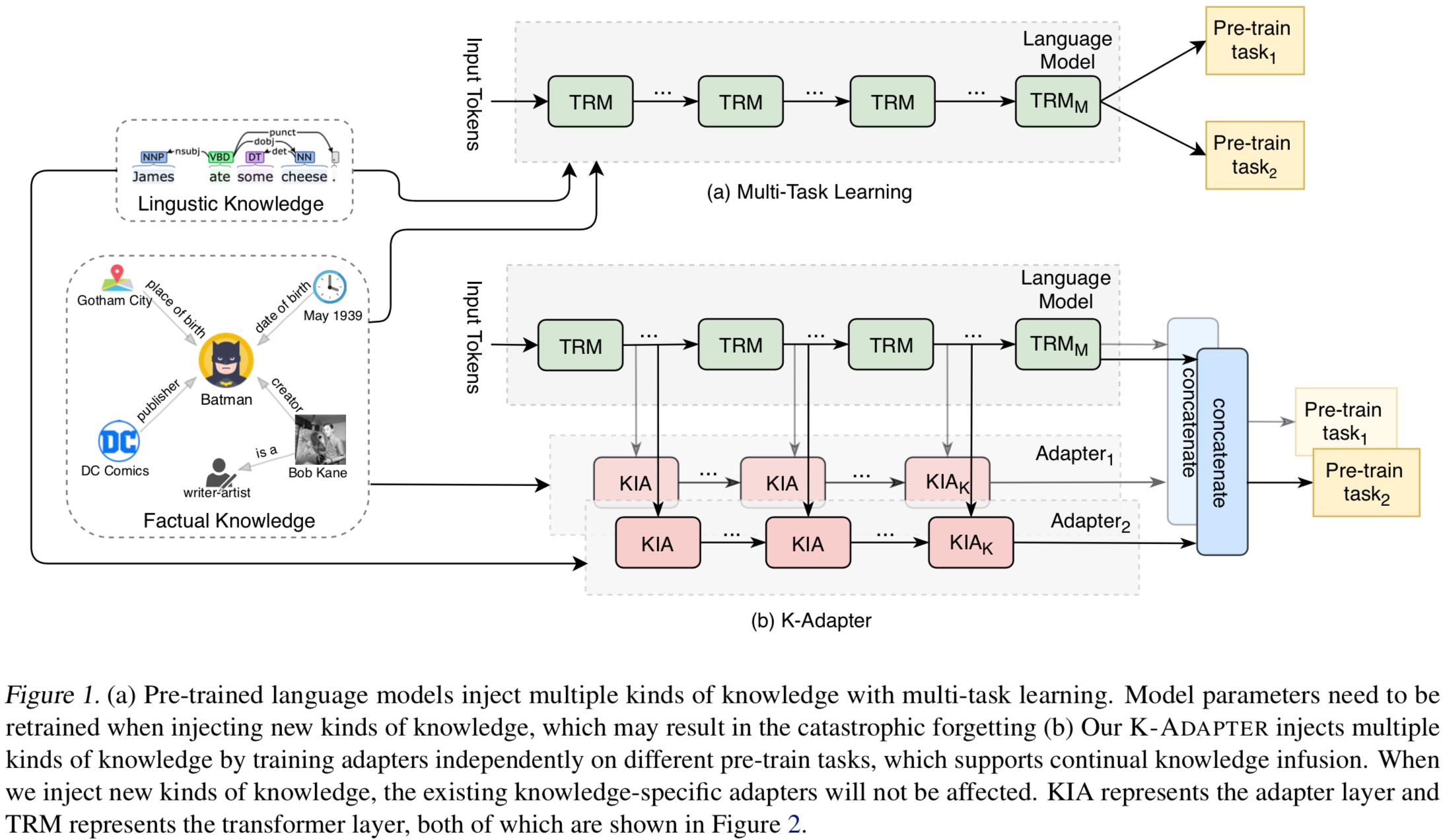
基于上述问题,本文提出了 K-Adapter,一种灵活、简便的向PLM中注入知识的方法,可以进行持续知识融合以及产生解耦的表示,保留了PLM产生的原始表示,可以引入多种知识;
Adapter:可以看做是一个 knowledge-specific 模型,可以作为一个插件,加在PLM外部,输入包含PLM中间层输出的隐状态,一种知识类型对应于一个Adapter,一个PLM可以连接多个Adapter;
本文引入的知识类型(具体引入知识的任务形式,在模型部分进行介绍):
- factual knowledge,将Wikipedia文本对齐到Wikidata三元组;
- linguistic knowledge,对web文本进行依存分析得到;
本文贡献:提出了一个K-Adapter模型;
- 通过知识适配器可以同时引入factual knowledge和linguistic knowledge;
- 相应地,最终的模型包含一个PLM和两个Adapter;
- 在下游任务(包含),以及在LAMA上的实验表明,与RoBERTa相比,K-Adapter 可以捕获更丰富的factual和commonsense知识;
本文工作与先前工作的3个不同之处:
- 同时考虑了fact-related和linguistic-related的目标函数(为了同时引入两种类型的知识);
- 在注入知识的过程中,原始的PLM参数没有变化;
- 可以支持持续学习,不同的知识适配器的学习是解耦的(独立的),后续再加入知识不会对已加入的知识产生影响;
K-ADAPTER
本文中的PLM使用RoBERTa;
图:(a) 基于多任务学习向PLM引入知识的框架,(b) 本文通过知识适配器引入知识的框架;
3.1 Adapter 结构
Adapter的具体结构如Fig.2所示:
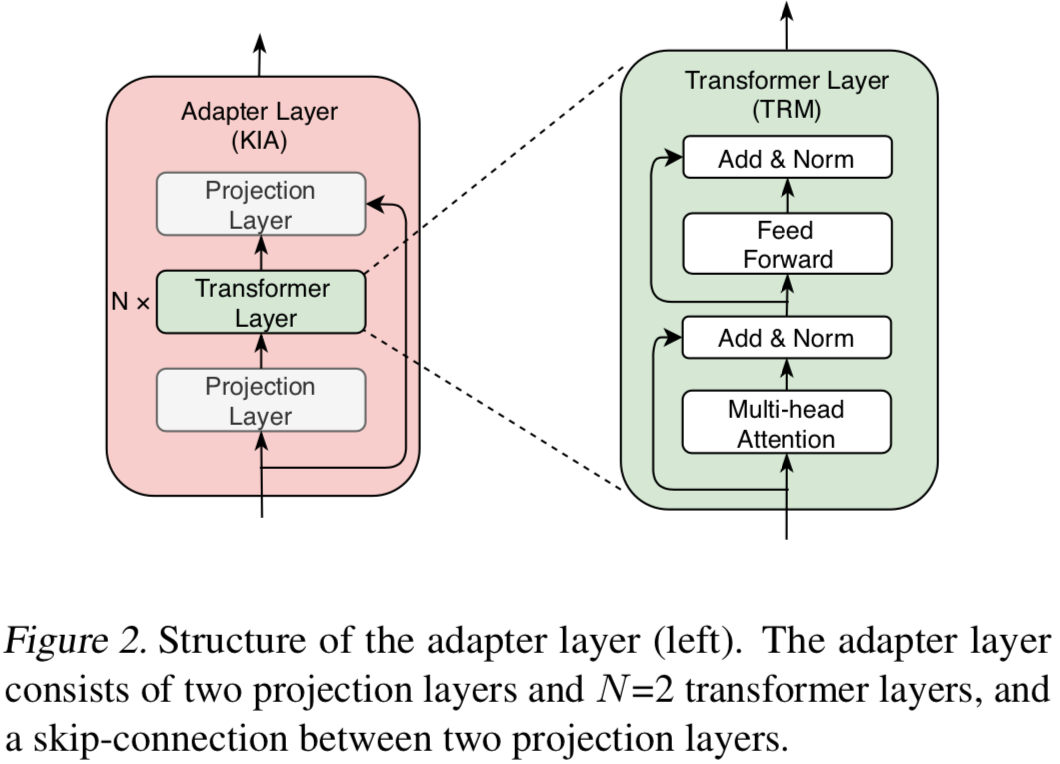
每个Adapter模型包含 K个adapter层,每个adapter层包含:
- N个transformer层;
- 2个映射层;
- 1个残差连接;
与PLM的连接位置:将adapter层连接到PLM中不同的transformer层上
与PLM的连接方式:
- 当前adapter层的输入:a) transformer层输出的隐藏层,b) 前一个adapter层的输出,这两个表示进行concat;
- Adapter模型的输出:a) PLM最后一层的隐藏层输出,和 b) 最后一个adapter层的输出,进行concat作为最终的输出;
预训练-微调阶段:
- 不同的Adapter在不同的预训练任务上分别进行训练;
- 对于不同的下游任务,K-Adapter采用和RoBERTa相同的微调方式;
- 只使用一种Adapter时,Adapter模型的最终输出作为task-specific层的输入;
- 使用多种Adapter时,将多个Adapter模型的输出进行concat作为task-specific层的输入;
预训练设置:
- 使用RoBERTa-Large模型,335M参数;
- adapter层中的transformer层数 $N=2$,维度 $H_A=768$,self-attention head $A_A = 12$;
- adapter层中的两个映射层维度分别是 1024 和 768;
- adapter层连接在RoBERTa模型的 $\{0,11,23\}$层上;
- 不同的adapter层之间不共享参数;
- Adapter模型参数量:42M;
3.2 Factual Adapter
Factual Knowledge 主要来源于文本中实体之间的关系;
数据集:T-REx,将Wikipedia摘要和wikidata三元组进行了对齐;
数据集规模:5.5M句子,430种关系;
FacAdapter的预训练任务:关系分类,给定context和一对实体,对其间关系标签进行分类;
预训练任务相关的模块:引入了pooling层;
FacAdapter的参数随机初始化;
3.3 Linguistic Adapter
Linguistic Knowledge 主要来源于文本中词之间的依存关系;
数据集:BookCorpus,利用Standford Parser进行处理,
数据集规模:1M;
LinAdapter的预训练任务:依存关系分类,预测给定句子中每个token在依存分析结果中的father index
预训练任务相关的模块:引入了pooling层;
LinAdapter的参数随机初始化;
Experiments
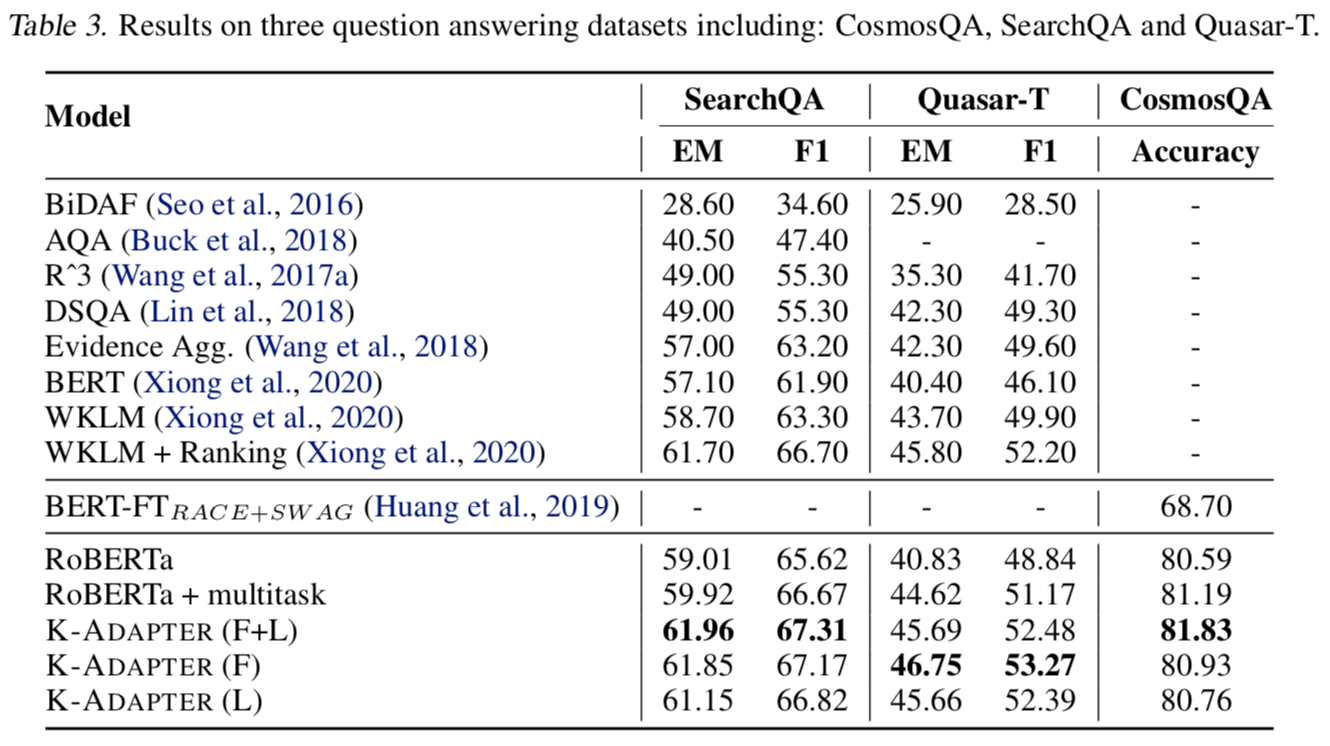
在三类下游任务上验证K-Adapter的性能:a) relation classification,b) entity typing,c) question answer;
主要关注在QA任务上的结果;
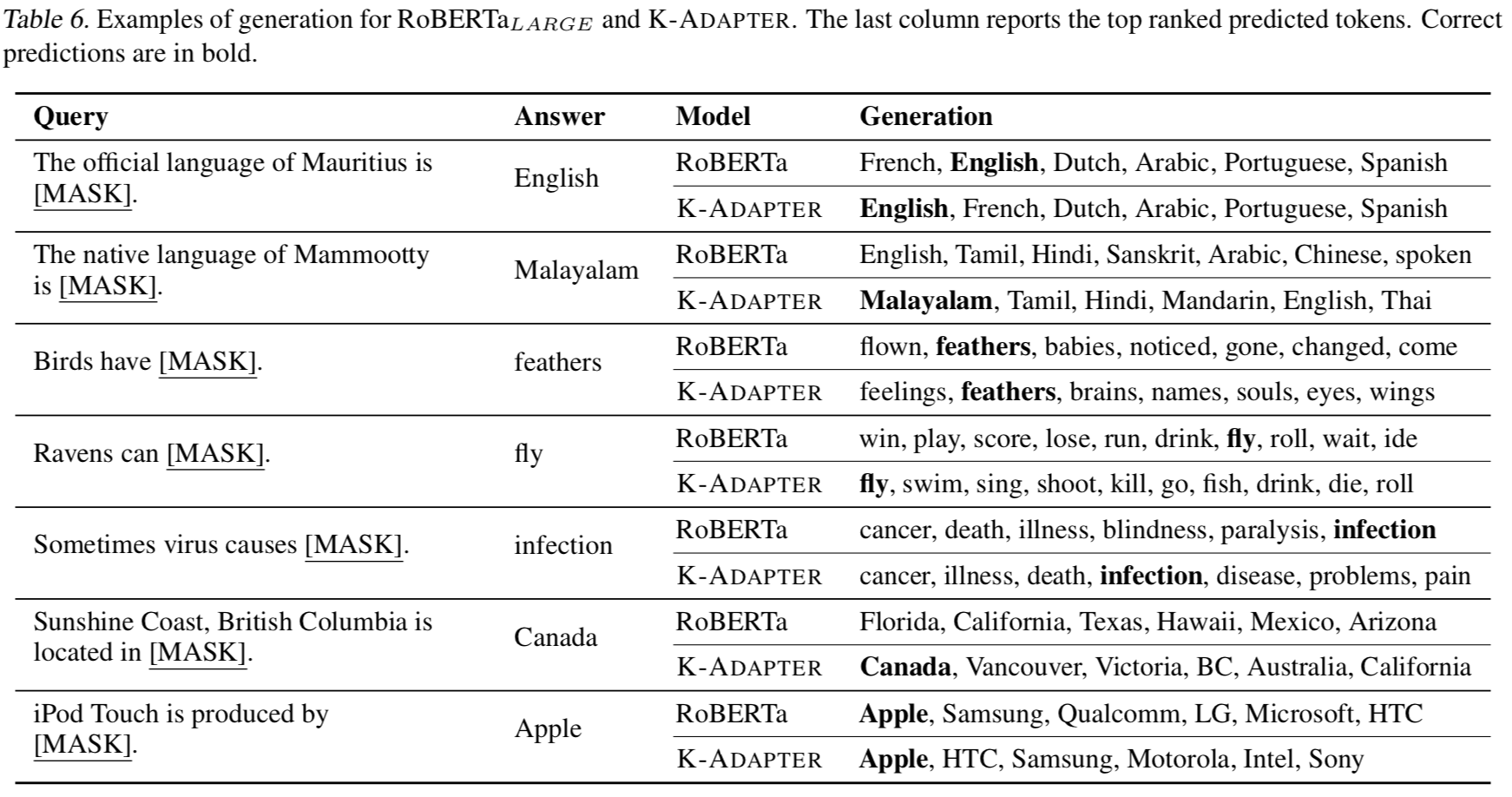
针对 LAMA query 的生成(预测被Mask位置的词)结果:
Summary & Analysis
- 目前这版的K-Adapter模型,在融合多种知识的adapter产生表示上的方法比较heuristic;
- RoBERTa自身已经具备很强的general 语言知识/语言学知识,LinAdapter对于下游任务的提升并不明显,额外引入的知识和PLM自身的知识有复合的部分。
- 两个训练K-Adapter的任务,是否适用于学到事实型知识和语言学知识?
- 如何针对不同的知识设计不同的学习/预训练任务?
- 1.BERT is Not a Knowledge Base (Yet): Factual Knowledge vs. Name-Based Reasoning in Unsupervised QA. arXiv preprint arXiv:1911.03681, 2019. ↩
- 2.Negated LAMA: Birds cannot fly. arXiv preprint arXiv:1911.03343, 2019. ↩
- 3.oLMpics On what Language Model Pre-training Captures. arXiv preprint arXiv:1912.13283, 2019. ↩
- 4.ERNIE: Enhanced Language Representation with Informative Entities. In ACL, pp. 1441–1451, 2019. ↩
- 5.Informing unsupervised pretraining with external linguistic knowledge. arXiv preprint arXiv:1909.02339, 2019. ↩
- 6.Sensebert: Driving some sense into bert. arXiv preprint arXiv:1908.05646, 2019. ↩
- 7.Knowledge enhanced contextual word representations. In EMNLP, pp. 43–54, 2019. ↩
- 8.Integrating Graph Contextualized Knowledge into Pre-trained Language Models. In AAAI, 2020. ↩
- 9.Pretrained Encyclopedia: Weakly Supervised Knowledge-Pretrained Language Model. In ICLR, 2020. ↩