References:
- Do Language Models have Common Sense? [ paper ]
- Commonsense Knowledge Mining from Pretrained Models. [ paper ]
- Evaluating Commonsense in Pre-trained Language Models. [ paper ]
- Why Do Masked Neural LMs Still Need Common Sense Knowledge. [ paper ]
Do Language Models have Common Sense? 2019.
Authors: Trieu H. Trinh, Quoc V. Le
Org.: Google
本文工作:
- 展示能够证明LM可以学习捕获一定常识知识的证据,并且这种知识可以很容易的捕获到;
- 本文的主要观察:LM可以计算任意statement的概率,这个概率可以用于评价一个statement的真实性;
本文方法: LM Scoring;
- 与其他增加特定分类层的做法不同,本文对于MLM模型不进行任何模块的增加,而是增加了一项额外的training objective,联合原始的LM训练object,在数据集上对LM进行微调;
- $Loss_{new} = Loss_{LM} + max(0, log(Perp_{positive}) - log(Perp_{negative}) + \alpha)$
- $\alpha = 0.5$
Excerpt:
- Namely, language models are trained on text corpora, which encodes human knowledge in the form of natural language.
Commonsense Knowledge Mining from Pretrained Models. EMNLP,2019.
Authors: Joshua Feldman, Joe Davison, Alexander M. Rush
Org.: Harvard University
动机:
- inferring commonsense knowledge 是NLP的关键挑战,但是训练数据很稀疏,之前的工作表明,有监督学习下的commonsense mining在新的数据上的效果不好。
- 之前的利用常识知识增强机器学习模型方法:
- 1、直接用常识知识库对模型进行增强,虽然包含了高质量的信息,但是缺少覆盖度;
- 2、常识知识库补全,由提高资源的覆盖度为驱动;
本文方法
本文设计了一种利用大型预训练的双向语言模型生成常识知识的方法;
- 通过转换 relational triples 为 masked sentence,可以使用PBLM通过估计两个实体的点互信息,对三元组的有效性进行排序;
- 由于没有对PBLM的权重进行更新,本文的方法不会对知识库覆盖的常识知识产生偏置;
本文尝试利用语言模型的世界知识来直接识别常识事实;
- 利用MLM来确定再一个可能的关系下,两个实体之间的点互信息;
- 构建以句子的形式知识候选候选片段,可以用语言模型来近似一个文本的似然;
给定一个常识
head-relation-tail三元组:$x = (h,r,t)$,确定一个数值 $y\in \mathbb{R}$ 来反应一个给定三元组反映真实知识的确信度;head和tail都是任意长度词序列:- $h = \{ h_1, h_2, …, h_n\}$
- $t = \{t_1, t_2, …, t_m \}$
- 关系 $r \in \mathbb{R}$ 属于一个已知的关系集合;
- 目标:确定一个函数 $f$ 映射 relational triples 到一个有效性打分;
- $f(x) = \sigma(\tau (x))$
- $\tau$ 是句子生成函数;
- $\sigma$ 是打分模型;
本文方法依赖于两种类型的PLM:标准的单向模型和Masked双向模型;
Coherency Ranking (一致性打分)
- 将三元组根据模板转化为一个自然语句,可以产生一个候选句子集合,根据预训练单向语言模型 $P_{coh}$ 选择具有最高log-likelihood打分的候选句子;
- $S^\ast = argmax_{S\in \mathcal{S}} [logP_{coh}(S)]$
- 将三元组根据模板转化为一个自然语句,可以产生一个候选句子集合,根据预训练单向语言模型 $P_{coh}$ 选择具有最高log-likelihood打分的候选句子;
Scoring Generated Triples
- $PMI(t,h|r) = log p(t|h, r) - log p(t|r)$
- 使用MLM模型 $P_{cmp}$ 计算打分;
- $p(t|h,r) = P_{cmp} (w_i = t| w_{1:i-1}, w_{i+1:m})$
- 由于
tail可能是由$j$个词构成,使用贪婪近似的方法来估计其概率。 - 首先 mask 所有
tail中的词,然后计算每个的概率; - 然后找到最大概率的词的概率 $p_k$ ,重复 $j$ 次;
- 最终的条件似然:$p(t|h,r) = \prod _{k=1}^{j} p_k$
- 由于
- 边缘概率 $p(t|r)$ 计算类似,只不过在此时将
head也全都mask掉; 
最终的分数:
- $PMI_{\lambda}(t,h|r) = \lambda log p (t|h,r) - log p(t|r)$
- $\lambda$ 是超参数;
- 由于PMI的计算是对称的,我们还可以计算得到 $PMI_{\lambda}(h,t|r)$ 打分;
最终是将两个打分进行平均,以减少我们估计的方差;
Cited
- A recent study shows how to attain common sense knowledge from pretrained MNLMs without additional training (Feldman, Davison, and Rush 2019).
Evaluating Commonsense in Pre-trained Language Models. AAAI,2020.
Authors: Xuhui Zhou, Yue Zhang, Leyang Cui, Dandan Huang
Org.: UW, Westlake University, Zhejiang University
Motivation:
- 目前已经有很多工作对 Contextualize Representation(CR) 的 syntactic、semantic、word sense 知识进行了研究,并解释了为什么 CR 适用于这些任务;
- 但是鲜有工作调查 CR 中包含的 Commonsense Knowledge;
- 本文主要研究 GPT、BERT、XLNET、RoBERTa 的常识能力(Commonsense ability),通过在几个 challenging benchmarks 上进行测试,我们发现:
- 1、语言模型及其变体是提升模型常识能力的 effective objectives;
- 2、双向上下文和更大的训练集是加分项;
- 3、在需要更多推理步的任务上,现有的语言模型效果表现不佳;
- 通过构造 dual test cases 测试模型的鲁棒性,结果表明,LMs对于这些cases表示出了困惑,LMs只是学到了surface层面的常识而不是的deep level;
本文的方法:
benchmark包括:Conjunction Acceptability、Sense Making、WSC、SWAG、HellaSwag、Sense Making with Reasoning、Argument Reasoning Comprehension;
- 对上述数据集进行分类和重组,划分为 word-level 和 sentence-level 两组,从这两个层次来测试模型;
- word-level:CA、WSC、SM;
- 关注 名词、动词、形容词、副词、代词、连词;
- sentence-level:SMR、SWAG、HellaSwag、ARCT;
- 关注 常识推理;
- word-level:CA、WSC、SM;
- 对上述数据集进行分类和重组,划分为 word-level 和 sentence-level 两组,从这两个层次来测试模型;
常识能力可以分为两个方面:
- 拥有常识能力的模型应该具备关于世界的基础知识;
- 拥有常识能力的模型应该具备基于常识知识的推理能力;
实验设计(Experiment Design)
- 从 单向上下文LM模型 和 双向上下文LM模型 两类分别考虑一个句子的打分;
- 假设句子 $S$ 有 $n$ 个词组成 $S=\{w_1, …, w_{k-1}, w_k, w_{k+1}, …, w_n\}$,定义其得分为:
- 分母上的 $n$ 是为了消除句子长度的影响;
- 对于单向模型:
- $context_k = S_{<k} = \{w_1, …, w_{k-1}\}$
- 对于双向模型:
- $context_k = S_{-k}$ ,表示移除 $S$ 中的第 $k$ 个词,被替换为
[MASK];
- $context_k = S_{-k}$ ,表示移除 $S$ 中的第 $k$ 个词,被替换为
- 直觉上,$P_{\theta}(w_k | context_k)$ 可以解释为 在给定 $context_k$ 的条件下 $w_k$ (出现)的可能性;
- 在计算完句子打分之后,模型选择得分高的结果作为预测输出;
Robustness Test,通过几种方法构造dual test样例
- add、delete、replace、swap two words;
- 理论上,具备相关常识知识的模型,应该对于一对dual test样例给出一致的预测结果。
- 为了更好的调查模型给出poor consistency的原因,计算模型是如何在 $S_{correct}$ 和 $S_{incorrect}$ 之间做出选择的, 两个 $S$ 拥有相同的词数;
- $q_k = log( \frac{P_{\theta} (w_k | S_{correct} - \{w_k\}) }{ P_{\theta} (w_k | S_{incorrect} - \{w_k\}) })$, $1 \leq k \leq n$
- $Q = \sum_k q_k$
- 看 $Q$ 是否大于0
- 打分方法参考【A simple method for commonsense reasoning. 2018.】
Why Do Masked Neural LMs Still Need Common Sense Knowledge?
Authors: Sunjae Kwon et al.
Org.: Korea Advanced Institute of Science and Technology
MNLM = masked neural language model
- 本文的工作:本文的重点是通过理解单词之间的语义关系,来验证基于MNLM的RC模型可以回答多少或处理多少复杂的RC任务。 针对这个问题,我们提出了以下有关MNLM的常识理解的问题
- 1、MNLM是否理解不同的常识知识类型,尤其是关于 relations of attributes;
- 2、MNLM是否理解 两个相关关系的关联(a relationship between two related relations);
- 3、基于MNLM的RC模型如何解决不同难度水平的问题?
- 4、对于基于MNLM的RC模型,最难的RC任务是什么?
- 针对问题1和问题2,设计了一个 knowledge probing test 来分析MNLM是否理解结构化的常识知识,如外部知识库中的语义三元组;
- 实验结果反映,MNLM可以部分地理解不同类型的常识知识,并且发现还有很多知识尚未训练到,不能准确地分别relations;
- 针对问题3和问题4,首先根据context和question的lexical overlapping定义了一个RC问题的难度;
- lexical variation(词汇多样性)是一个RC难度的关键的决定因素;
- 问题需要常识知识的对基于MNLM的RC模型是个挑战;
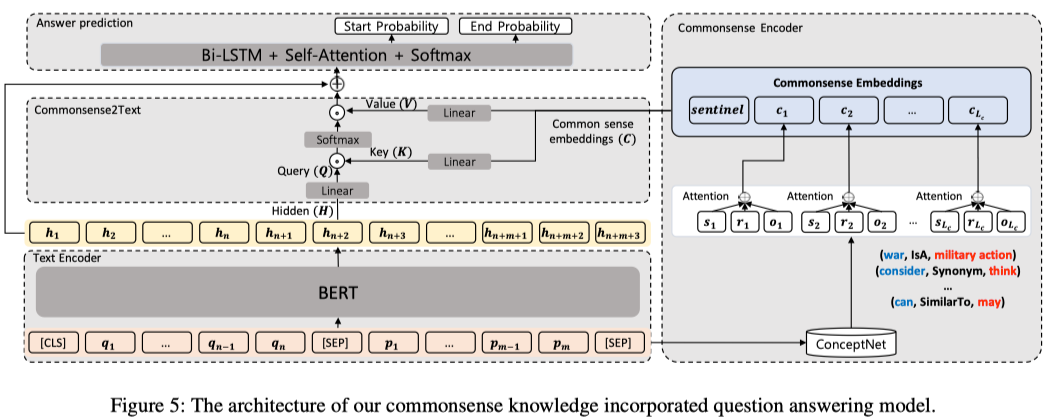
- 基于上述的结果,本文提出了一个改善MNLM的方法,通过外部知识库加入知识:
- 任务数据集:SQuAD
- manual,
- automatic,提出了一个神经网络结构来引入知识;
- 本文贡献:
- 提出了一个 knowledge probing 测试,度量训练的 MNLM 中包含多少常识知识;
- 发现,MNLM,并没有完全、准确地理解知识;
- 通过审查基于MNLM的RC模型的结果,发现目前的MNLM在解决需要常识知识的问题上存在决定性的瓶颈;
- 实验性的证实了,可以通过手工/自动地方式向MNLM中补充常识知识;
- 提出了一个 knowledge probing 测试,度量训练的 MNLM 中包含多少常识知识;