Title: Incorporating External Knowledge into Machine Reading for Generative Question Answering
Authors: Bin Bi, Chen Wu, Ming Yan, Wei Wang, Jiangnan Xia, Chenliang Li
Org.: Alibaba DAMO
Published: EMNLP 2019
code: NULL
This Work
与其他 Knowledge-aware QA 的工作不同,本文的研究重心是:在MRC中使用外部知识来生成自然语言语句答案。
与抽取式阅读理解不同,生成式阅读理解所产生的自然语言形式的答案片段不一定在给定的 passage 中出现。
目前大多数工作,把给定的 passage 作为唯一的信息源,来生成答案。由于缺少一些常识知识或背景知识,例如词汇知识或关系型知识,无法正确理解某些片段或正确回答某些问题(尤其是 non-trivial question)。这些知识虽然未在文本中显式出现,但是却可以在 外部KB 中找到。
基于上述,本文提出了一个 Knowledge-Enriched 答案生成模型(KEAG):
- 利用从4个信息源聚集得到的证据信息来生成答案,即在生成每个答案词时,从多个信息源中选定某一个作为生成答案词的源;
- 4个信息源分别是:question,passage,vocabulary,knowledge (ConceptNet)
- 设计了一个 source selector 用于选择用于生成词的知识源;
- 注:知识在答案的某些部分起着关键作用,而在一些情况下,文本上下文提供的信息应优先于上下文无关的通用知识;
- KEAG 自适应地决定何时利用符号化知识,以及哪些知识是有用的。使模型能够利用没有显式地在文本中给出的、但是对回答问题有帮助的外部知识。
- 通过可微分的采样方法向模型中引入离散隐变量,并进行训练;
使用的数据集是:MS-MARCO数据集中的 Q&A + Natural Language Generation 任务。
Model: Knowledge-Enriched Answer Generator
KEAG 的整体模型结构如下图所示: 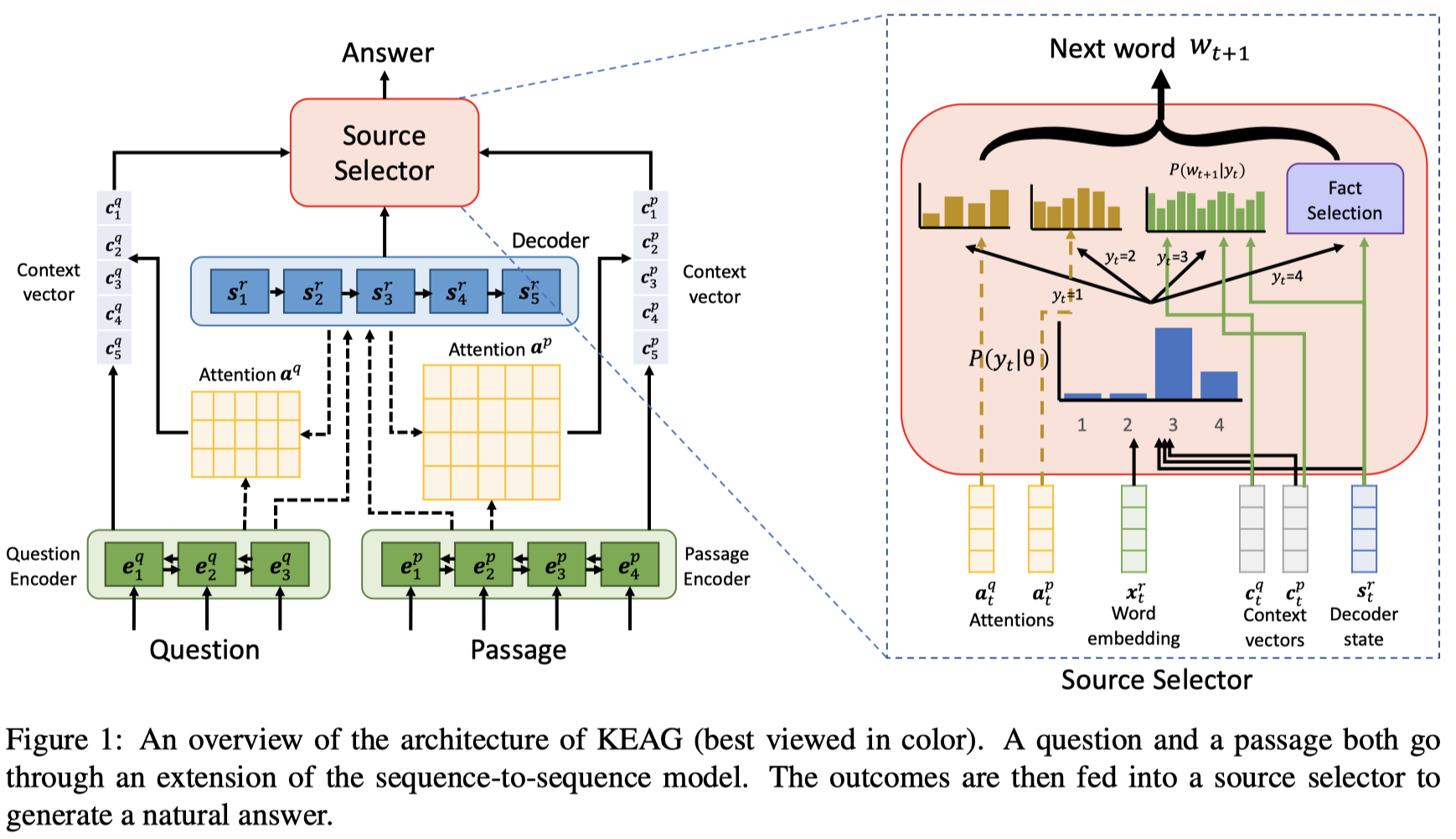
模型的输入:
- question $q = {w_1^q,w_2^q,…,w_{N_q}^q}$
- passage $p = {w_1^p,w_2^p,…,w_{N_p}^p}$
- 知识库 $K$, 由一系列三元组组成,每个三元组 $f = (subject, relation, object)$
模型的输出: - answer $r = {w_1^r, …, w_{N_r}^r}$
4个知识源:
- question $q$
- passage $p$
- global vocabulary $V$
- knowledge $K$
1.Seq2Seq
本文的主体模型是基于 seq-to-seq attention 模型的扩展;
在编码端,question 和 passage 分别通过两个不同的 encoder 进行编码,每个编码器都是 BiLSTM ;
编码端的输出为 encoder 的隐藏层状态:
- question $E_q$
- passage $E^p$
在解码端,使用 unidirectional-LSTM,输出的隐藏层状态为 $s_t^r$;
分别计算 question 和 passage 的注意力分布:
- $a_t^q = \text(softmax)(g^{q\top} \text{tanh}(W^q E^q + U^qs_t^r + b^q))$
- $a_t^p = \text(softmax)(g^{p\top} \text{tanh}(W^p E^p + U^p s_t^r + V^p c^q+ b^p))$
- $g^q$, $W^q$, $U^q$, $b^q$, $g^p$, $W^p$, $U^p$, $b^p$ 是训练参数;
- 注意力分布可以认为是 source words 上的概率分布;
为了避免生成重复,本文也采用了 coverage 机制:
- $c_t^q = \sum_i a_{ti}^q \cdot e_i^q$
- $c_t^p = \sum_i a_{ti}^p \cdot e_i^p$
- 其中 $e_i^q$ 和 $e_i^p$ 分别是 question 和 passage 的 encoder 隐状态;
计算得到的 上下文向量 $c_t^$, 注意力分布 $a_t^$ 以及 decoder 状态 $s_t^r$ 在后续步骤中用于决定 下个词 的生成来源;
2.Source Selector
在答案生成过程中,在每个时刻,先使用 source selector 选择一个词源;
在 第 $t$ 时刻,为了决定在哪个源中进行待生成词概率的计算,引入一个离散隐变量 $y_t \in \{1,2,3,4\}$,作为源指示器:
- 如果选择 question 作为 source,$y_t = 1$ :
- 待生成词将从下面的分布中选取:$a_t^q \in \mathbb{R}^{N_q}$
- $P(w_{t+1}|y_t) = \sum_{i:w_i=w_{t+1}} a_{ti}^q$
- 如果选择 passage 作为 source,$y_t = 2$ :
- 待生成词将从下面的分布中选取:$a_t^p \in \mathbb{R}^{N_p}$
- $P(w_{t+1}|y_t) = \sum_{i:w_i=w_{t+1}} a_{ti}^p$
- 如果选择 vocabulary 作为 source,$y_t = 3$ :
- 待生成词将从下面的分布中选取:$P_v(w|c_t^q, c_t^p, s_t^r) = \text{softmax}(W^v \cdot [c_t^q, c_t^p, s_t^r] + b^v)$
- $P(w_{t+1}|y_t) = P_v(w|c_t^q, c_t^p, s_t^r)$
- 如果选择 知识 作为 source,$y_t = 4$:
- 需要使用 fact selector,在下一节中介绍;
3.Knowledge Integration
首先从KB中抽取相关的facts,然后从中选择最相关的fact用于生成答案
3.1 Related Fact Extraction
抽取出与question和passage相关的候选facts集合,对于一个 $(q,p)$ 对,抽取出 facts 中的 subject 或是 object 出现在 question 或 passage 中的三元组,对三元组的打分规则如下:
- score+4 : subject 在 question 中出现,且 object 在 passage 中出现;
- score+2 : subject 和 object 都在 passage 中出现;
- score+1 : subject 在 question 或 passage 中出现;
最终,选择分数排序 top - $N_f$ 个 facts 用于后续操作;
3.2 Fact Selection
Fact Selection 模块的结构如下图所示: 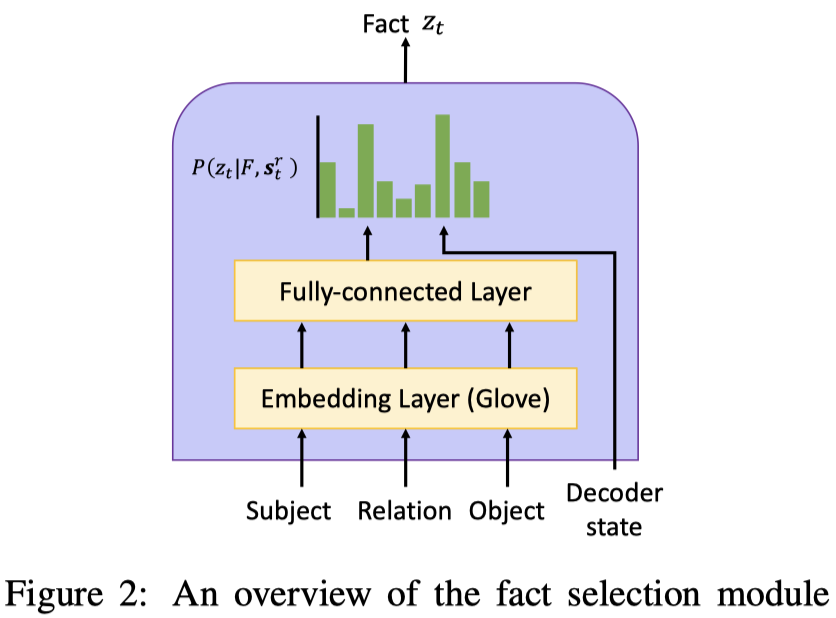
- Fact Embedding:
- 每个 fact 的编码由 subject、relation、object的 Embedding 串联得到
- subject、relation、object的 Embedding 由 Glove 进行初始化
- $f = W^e \cdot [e^s, e^r, e^o] + b^e$
- Facts 集合的表示:$F = \{f_1, f_2, …, f_{N_f}\}$
- 选择 最相关的 Facts:
- 引入 离散随机隐变量 $z_t \in [1, N_f]$ 用以指示哪条 fact 被选中;
- $z_t$ 通过从 离散分布 $P(z_t | F, s_t^r)$ 中采样得到:
- $P(z_t | F, s_t^r) = \frac{1}{Z}\cdot \text{exp}(g^{f\top} \text{tanh}(W^f f_{z_t} + U^f s_t^r + b^f))$
- $Z = \sum_{i=1}^{N_f} \text{exp}(g^{f\top} \text{tanh}(W^f f_{i} + U^f s_t^r + b^f))$
- 在这里使用了 Gumbel-Softmax 技巧;
- $z_t$ 表示 第 $z_t$ 个 fact 在 $t$ 时刻被 decoder 选中,当模型决定从知识源中生成词是,将 选中fact 中的 object 词作为将要生成的答案词;
Experiments
主实验:
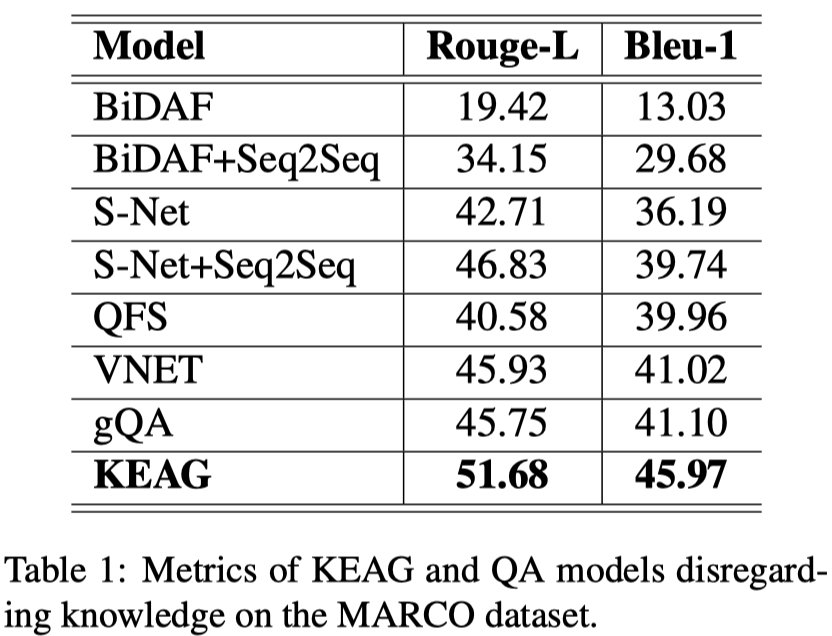
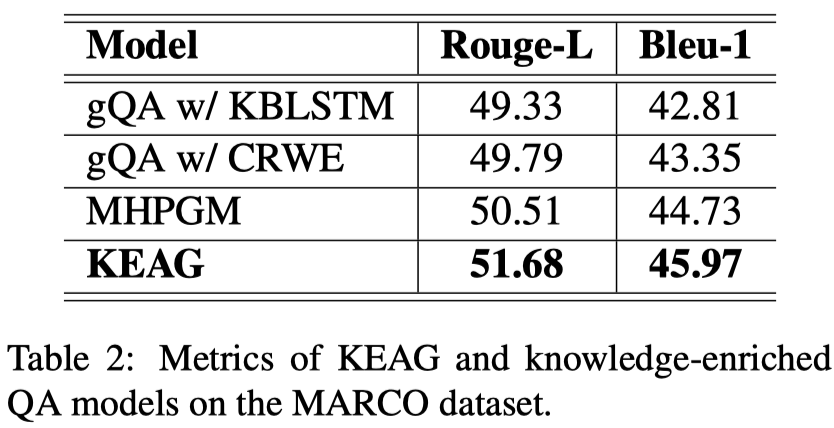
和加知识模型的对比:
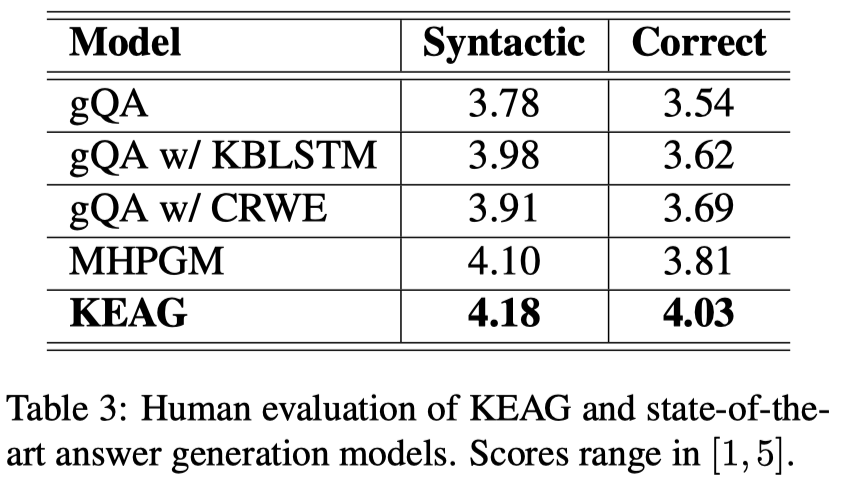
人工评测:
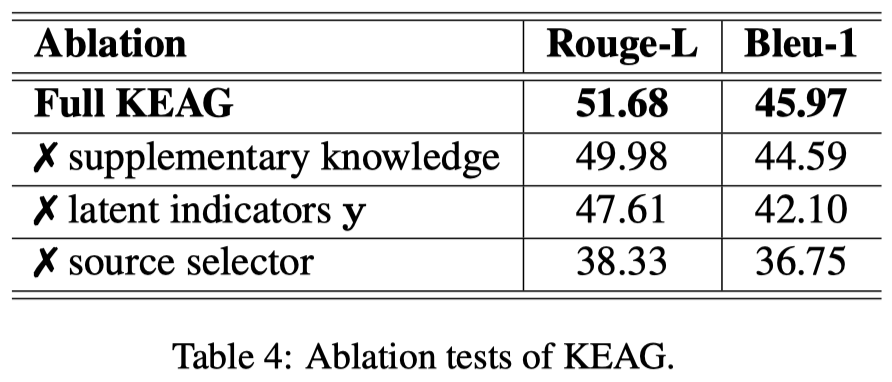
去除实验:
可视化例子:

Related Works
- generate natural answers in QA
- 知识在 QA 任务中的作用:
- Knowledgeable reader: Enhancing cloze-style reading comprehension with external commonsense knowledge.
- Improving question answering by commonsense-based pre-training.
- World knowledge for reading comprehension: Rare entity prediction with hierarchical lstms using external descriptions.
- incorporating knowledge into QA models without passage reading:
- Neural generative question answering.
- combines knowledge retrieval and seq2seq learning to produce fluent answers, but it only deals with simple questions containing one single fact.
- Generating natural answers by incorporating copying and retrieving mechanisms in sequence-tosequence learning.
- extends it with a copy mechanism to learn to copy words from a given question
- Natural answer generation with heterogeneous memory.
- introduced a new attention mechanism that attends across the generated history and memory to explicitly avoid repetition, and incorporated knowledge to enrich generated answers.
- Neural generative question answering.
- knowledge-enhanced natural language (NLU) understanding:
- Dynamic integration of background knowledge in neural NLU systems.
- dynamically integrates background knowledge in a NLU model in the form of free-text statements, and yields refined word representations to a task-specific NLU architecture that reprocesses the task inputs with these representations.
- Leveraging knowledge bases in LSTMs for improving machine reading.
- leverages continuous representations of knowledge bases to enhance the learning of recurrent neural networks for machine reading.
- Commonsense for generative multi-hop question answering tasks.
- a QA architecture that fills in the gaps of inference with commonsense knowledge. The model, however, does not allow an answer word to come directly from knowledge.
- Dynamic integration of background knowledge in neural NLU systems.
Analysis & Summary
- 可视化实验中缺少了fact selector的结果;
- 1.Chuanqi Tan, Furu Wei, Nan Yang, Bowen Du, Weifeng Lv, and Ming Zhou. 2018. S-net: From answer extraction to answer synthesis for machine reading comprehension. In AAAI. ↩
- 2.Rajarshee Mitra. 2017. An abstractive approach to question answering. CoRR, abs/1711.06238. ↩
- 3.Preksha Nema, Mitesh M. Khapra, Anirban Laha, and Balaraman Ravindran. 2017. Diversity driven attention model for query-based abstractive summarization. In Proceedings of the 55th Annual Meeting of the Association for Computational Linguistics, pages 1063–1072. Association for Computational Linguistics. ↩