Title: Exploring ways to incorporate additional knowledge to improve Natural Language Commonsense Question Answering
Authors: Arindam Mitra, Pratyay Banerjee, Kuntal Kumar Pal, Swaroop Mishra, Chitta Baral
Org.: Arizona State University
Published: NULL, 2019
Code: NULL
This Work
Research Background:
- DARPA 和 Allen AI 提出了一系列数据集来促进 需要 commonsense knowledge (CS-KN) 问答任务的研究;
- 额外的挑战:常识知识通常不容易以文本形式获取;
- 近期,BERT/GPT 等预训练语言模型在多个 Multiple Choice Question-Answering (MCQ) 数据集上展示出了相当好的效果;
- 已经超越了一些针对特定任务精心设计的模型,甚至可以超过人类水平(i.e., SWAG);
- 成为了大多数新提出的数据集 baseline;
- 在需要超越QA对本身知识的question上也表现良好;
- 一些知识可能借由文本的形式,通过在巨大规模的text语料上训练时,封装在了LM中,由此引出的问题:
- 如果进一步给 LM 灌注 the needed KN 是否能带来性能的提升?
- 进行 KN infusion 的方法是什么?
- 一些知识可能借由文本的形式,通过在巨大规模的text语料上训练时,封装在了LM中,由此引出的问题:
这篇文章的目标是:设计将外部(常识)知识结合到 LM-based 模型中的方法,以提高QA模型在MCQ任务上的性能。
本文的具体工作:
- 确定外部知识源,展示通过 IR 技术抽取出的 fact 集合,在训练和测试阶段,会为性能带来提升;
- 进一步探索如果 用不同的方式提供 task-specific 知识 或是 用不同的策略使用可用的知识,能否进一步带来提升;具体介绍了:
- 3种传递知识 (pass knowledge) 的策略;
- 1\ revision: 在KB中拥有与数据集相关的 knowledge statements 上微调LM;
- 2\ open-book: 为 Q-A 对从KB中选择一定数量的 knowledge statements (textually similar to Q-A pair) 用来回答问题;
- 3\ mixture (revision & open-book): 先进行 revision,在进行 open-book;
- 5种利用知识 (use knowledge) 的模型;
- concat / max / simple sum / weighted sum / mac ;
- 3种传递知识 (pass knowledge) 的策略;
- 提出了一个新的框架,用于处理回答 MCQ 任务中 question 所需要的信息分散在不同的知识句 (knowledge sentences) 中的情况;
MCQ Datasets & Knowledge
(为了研究如何引入知识,首先要选出需要外部知识的一些数据集作为测试系统的QA任务)
MCQ Tasks:
- Abductive Natural Language Inference[1]
- Physical Interaction QA[2]
- Social Interaction QA[3]
- Parent and Family QA
- 这个数据集是本文为了对知识有更好的可控性而合成的数据集;
- 一方面来测试NLM的记忆能力,另一方面测试将分散在多个句子中的知识结合起来的能力;
- 数据集的来源是DBPedia,抽取其中的亲子关系,构造成多选型数据集;
Knowledge Sources (different KBs for different tasks):
Relevant Knowledge Extraction:
- 使用IR和Re-ranking等方法抽取出相关的 knowledge paragraph
- 这里使用的方法参考自ACL 2019的一篇文章[7]
- 先使用IR模型,然后通过计算 Information Gain 进行 re-ranking
- query 通过简单的 heuristic 方法产生(即,question/answer option/context中出现的非停用词)
- 对于每个数据集,选择 top-10 的知识句子。
示例:每个数据集及其从各自KB中抽取出的知识: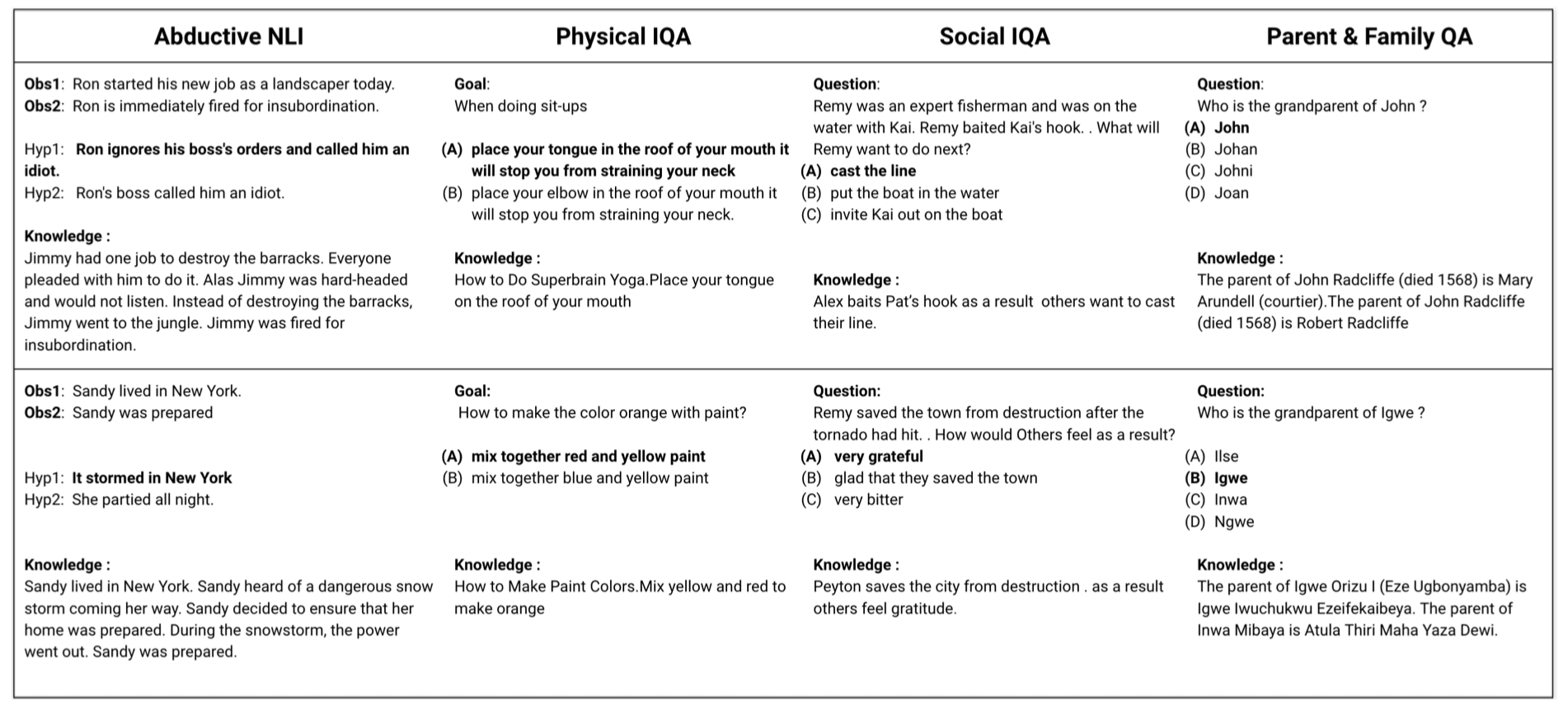
Modes of Knowledge Infusion
本文中使用的预训练的 BERT-uncased-whole-word-masked model 作为base模型。
本节介绍的5种知识结合方法是在open-book策略下进行的。
模型的输入:
- question $Q$;
- $n$ 个候选答案 $a_1, …, a_n$;
- $n$ 个 premises(每个候选答案对应一个premise)
- 每个 premise包含 $m$ 个 knowledge passages
- 使用 $k_{ij}$ 表示 第 $i-th$ 答案选项的第 $j-th$ knowledge passage
模型的输出:为每个候选答案计算一个分数 $score(i)$ , 最终选择分数最高的作为最终的答案
1.Concat
- 将每个选项的所有的($m$ 个)knowledge passage 连接起来,形成一个 knowledge passage $k_i$ ;
- BERT 的输入为:
[CLS] K_i [SEP] Q a_i [SEP]; - 选择 BERT 最后一层的
[CLS]的表示; - 计算所有选项,得到 $n$ 个
[CLS]表示,再经过一个 linear layer 计算得到 $score(i)$ ;
2.Parallel-Max
- BERT 的输入为:
[CLS] K_ij [SEP] Q a_i [SEP]; - 每条知识和QA对分别编码,对每个QA对中涉及的m条知识,计算m个打分选择最大值作为选项的打分
3.Simple Sum
- simple/weighted sum / MAC 假设信息分散在多个句子中,需要聚集这些分散的信息;
- BERT 的输入为:
[CLS] K_ij [SEP] Q a_i [SEP]; - 将 $m$ 个向量相加,得到最终的 summary vector;
- 计算所有选项,得到 $n$ 个 summary vector,再经过一个 linear layer 计算得到 $score(i)$ ;
4.Weighted Sum
- 与simple sum的区别:一些knowledge passage可能更有用;
- 为一个候选项对应的 $m$ 个
[CLS]表示计算一个标量权重 $w_{ij}$ (weight layer), 然后计算 $m$ 个[CLS]表示的权重和; - 最后通过一个线性映射和 复用 weight layer 来计算 候选项$a_i$的 $score(i)$;
5.MAC
MAC = Multi-sentence Alighment Classification
- 第一步同 weighted sum,先为一个候选项对应的 $m$ 个
[CLS]表示计算一个标量权重 $w_{ij}$ - reduce the normalized score
- $ w_{ij}^{\prime} = w_{ij} - ( 1 - w_{ij}) \ast max_{j\neq l \wedge l \in \{1…m\}} \{LinkStrength_{ijl}\} $
- $LinkStrength_{ijl} \in [0,1]$ 表示两个 knowledge passage 之间的连接强度
- 如果两个知识(即 knowledge passage)有更好的 link strength,那么他们可以联合起来推出新的信息
- 例如:
Facebook was launched in Cambridge和Cambridge is in MA的 link strength 更高,可以推出Facebook was launched in MAFacebook was launched in Cambridge和Boston is in MA的 link strength 较低
- weight reduction 的含义是:如果一个知识/knowledge passage,不足够和其他知识进行联合,那么它可能在最终的predicttion阶段也没必要被考虑
- link strength 的计算方式可以有很多形式,本文中介绍了一种 memory-efficient 的方式
- 从BERT输出的表示中抽取出 knowledge passage 对应的 token 表示:$h_{i,j}^1, …, h_{i,j}^p$
- $link_{ij} = \sum_{t=1}^p s_{ij}^t \ast h_{ij}^t$
- $s_{ij}$ 是标量,由 $h_{ij}$ 通过一个线性层得到,表示 $h_{ij}$ 是否可以被纳入 link description $link_{ij}$
Strategies of Knowledge Infusion
Notation:
- $D$ 表示 MCQ 数据集;$T$ 表示 pre-trained LM;$K_D$ 表示知识库,即抽取出来的 knowledge passages/sentences;K 表示 general knowledge base,即用来预训练 $T$ 的语料;
- $K$ 不一定包含 $K_D$
- Revision:在$K_D$上使用与MLM和NSP任务微调$T$ ,然后再在 $D$ 上进行微调
- Open-Book:$D$ 中的每个训练样例都有各自的 $K_D$,在扩充了知识的 $D$ 上微调 $T$
- Revision along with Open-Book:先进行 Revision,再进行 Open-book
Experiments
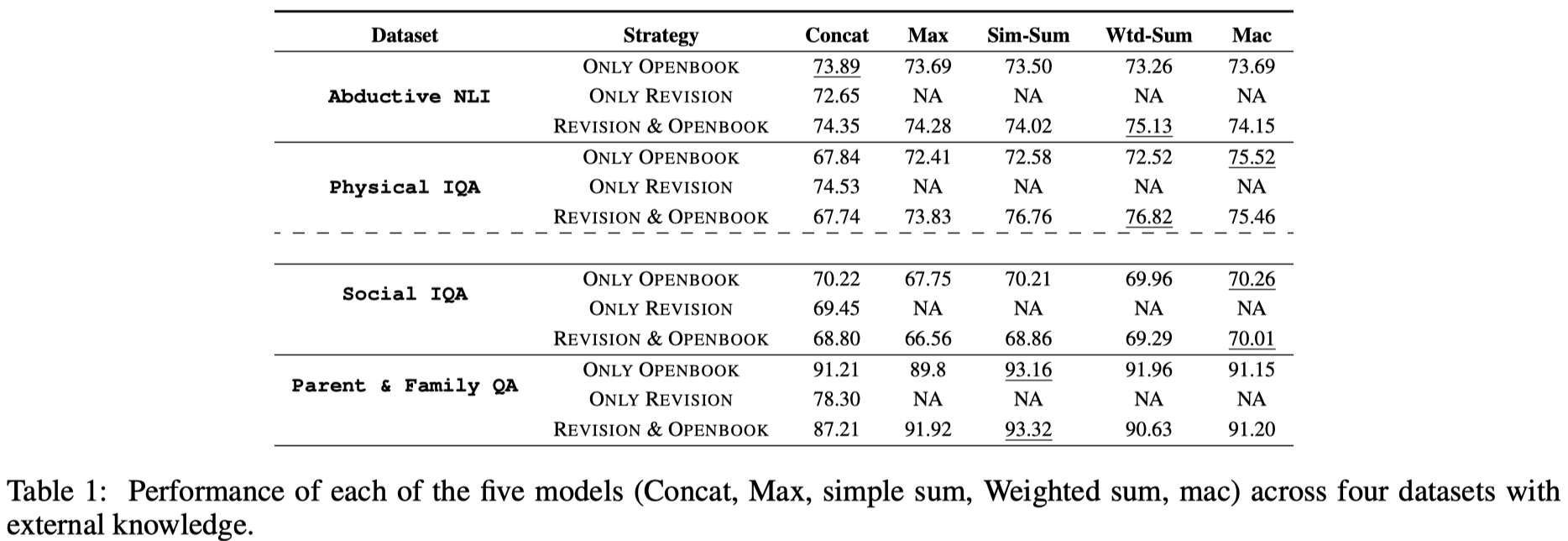
- 三种策略及五种知识融合模型在四个数据集上的效果:
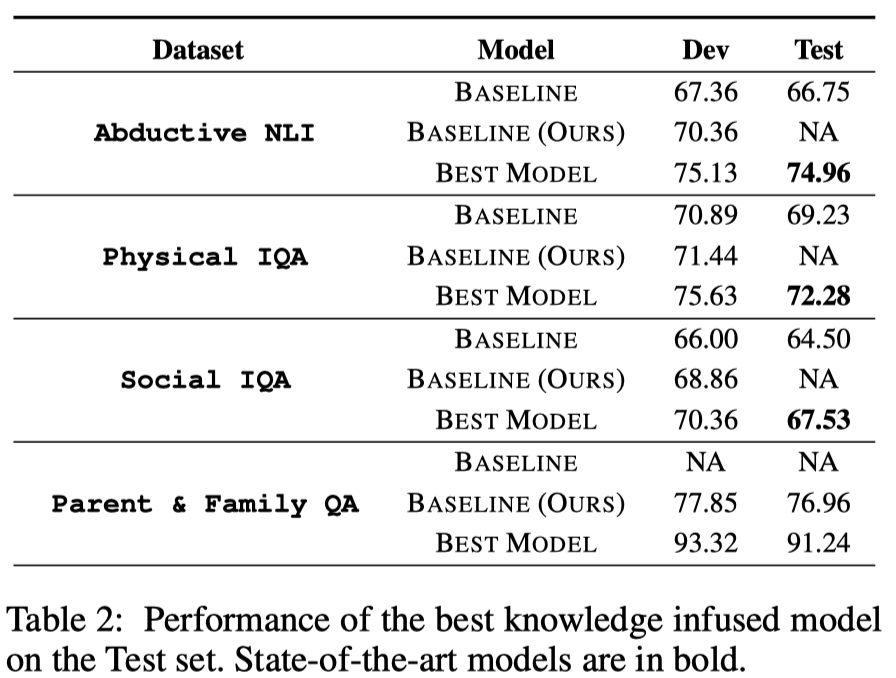
- 知识模型融合性能最好的再测试集上的效果:
- 对比实验:
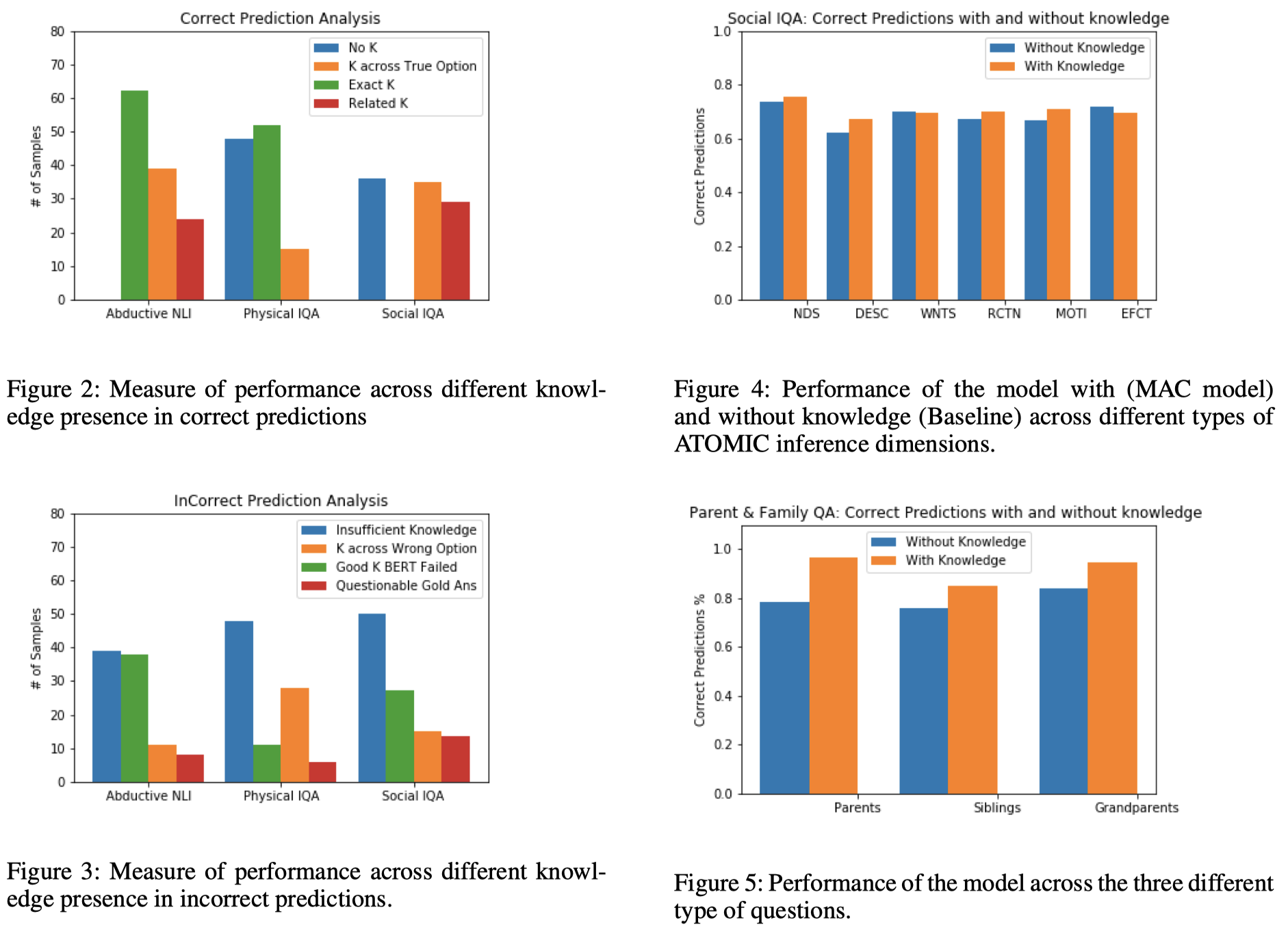
- 对于预测正确的情况,分析 (1) Exact appropriate knowledge is present, (2) A related but relevant knowledge is present, (3) Knowledge is present only in the correct option, and (4) No knowledge is present.
- 对于预测错误的情况,分析 (1) Is the knowledge insufficient, (2) Is the knowledge present in the wrong answer, (3) Knowledge is appropriate but model fails, and (4) Gold label is questionable.
Analysis & Summary
遗留问题:5种知识结合方法的计算中,标量权重值通过什么NN得到?标量的范围是否有限制?比如,需要在$[0,1]$之间?
这篇文章较为全面的总结了向LM中引入知识的策略以及计算表示的方法。
- 方法比较启发性但是很有效,在三个commonsense knowledge的数据集上都取得了SOTA的结果。
- 虽然已有的KB无法包含所有回答问题所需要的knowledge,但是KB确实能够提供重要的knowledge。
- BERT虽然已经具备了一些knowledge,但是仍然存在 给定knowledge但是模型无法回答的情况,或是使用了 irrelevant knowledge 产生了错误预测的情况,这些都是值得进一步研究的问题。
- 1.Abductive commonsense reasoning. 2019. Bhagavatula, C.; Bras, R. L.; Malaviya, C.; Sakaguchi, K.; Holtzman, A.; Rashkin, H.; Downey, D.; Yih, S. W.-t.; and Choi, Y.. arXiv preprint arXiv:1908.05739. ↩
- 2.https://leaderboard.allenai.org/physicaliqa ↩
- 3.Socialiqa: Commonsense reasoning about social interactions. 2019. Sap, M.; Rashkin, H.; Chen, D.; LeBras, R.; and Choi, Y. arXiv preprint arXiv:1904.09728. ↩
- 4.A corpus and evaluation framework for deeper understanding of commonsense stories. 2016. Mostafazadeh, N.; Chambers, N.; He, X.; Parikh, D.; Batra, D.; Vanderwende, L.; Kohli, P.; and Allen, J.arXiv preprint arXiv:1604.01696. ↩
- 5.Wikihow: A large scale text summarization dataset. 2018. Koupaee, M., and Wang, W. Y. arXiv preprint arXiv:1810.09305. ↩
- 6.Atomic: an atlas of machine commonsense for if-then reasoning. 2019. Sap, M.; Le Bras, R.; Allaway, E.; Bhagavatula, C.; Lourie, N.; Rashkin, H.; Roof, B.; Smith, N. A.; and Choi, Y. In Proceedings of the AAAI Conference on Artificial Intelligence, volume 33, 3027–3035. ↩
- 7.Careful selection of knowledge to solve open book question answering. 2019. Banerjee, P.; Pal, K. K.; Mitra, A.; and Baral, C. In Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics, 6120–6129. Florence, Italy: Association for Computational Linguistics. ↩