Title: Graph-Based Reasoning over Heterogeneous External Knowledge for Commonsense Question Answering
Author: Shangwen Lv, Daya Guo , Jingjing Xu, Duyu Tang, Nan Duan, Ming Gong, Linjun Shou, Daxin Jiang, Guihong Cao, Songlin Hu
Org.: CAS, Sun Yat-sen University, PKU, Microsoft
Published: AAAI,2020
Code: NULL
Motivation
常识问答任务(Commonsense Question Answering, CSQA) 要求回答需要背景知识的,且背景知识未在问题中提及的一些问题
CSQA 的主要挑战是:如何从外部的知识中抽取证据信息,并给予证据做出预测。
近期的工作主要集中在两个方面:
- 根据带有人工标注出证据的数据集,学习生成证据 cose.
- 问题是:标注代价昂贵
- 仅从结构化知识库或是非结构化知识库,即同构知识源,中抽取证据信息,并没有同时利用不同来源的知识
- 为什么要同时利用结构化和非结构化的知识库?
- 结构化知识 (Structured Knowledge Source): 包含大量的三元组信息(概念 及其之间的关系),利于推理,但是存在覆盖度低的问题
- 非结构化知识 (Unstructured Knowledge Source): 即 Plain-Text,包含大量冗余的、覆盖范围广的信息,可以辅助/补充结构化知识
- 为什么要同时利用结构化和非结构化的知识库?
融合异构知识源必要性的例证: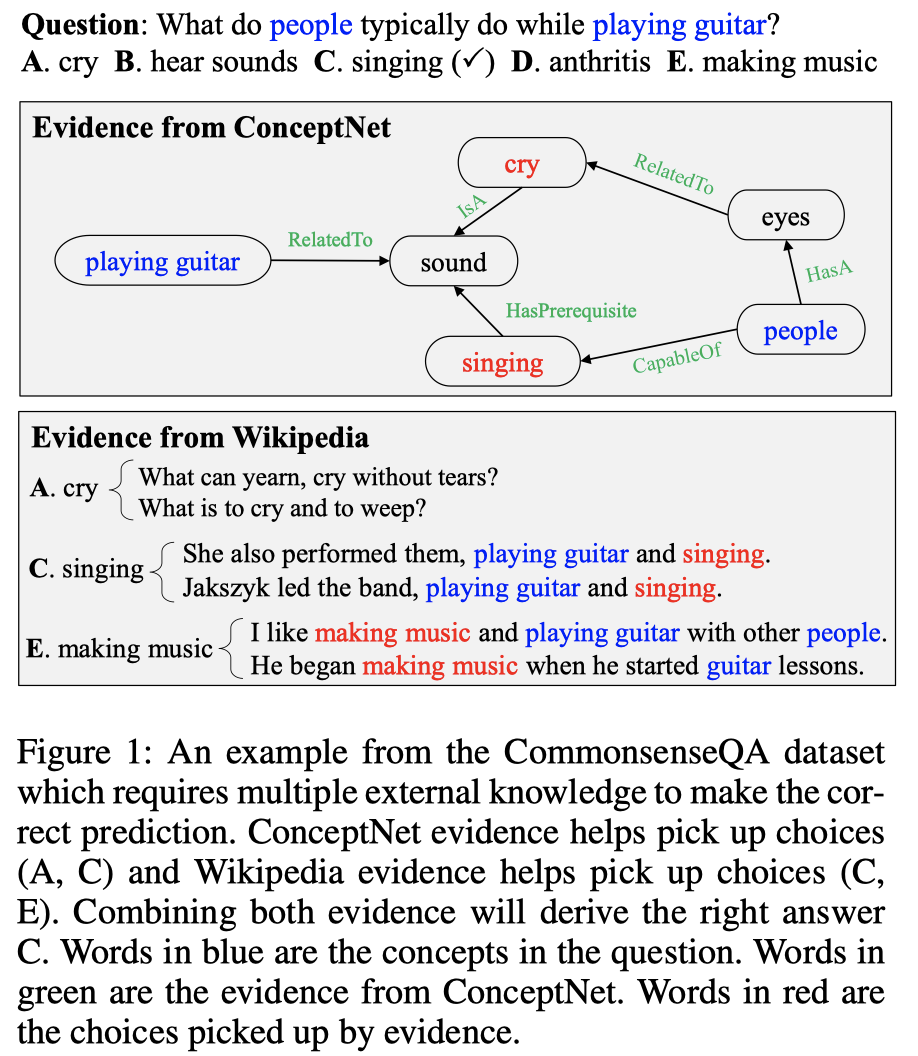
- 根据结构化知识库ConceptNet,可以挑选出候选 A 和 C
- 根据Wikipedia文本,可以挑选出候选 C 和 E
- 结合两类来源的证据,即可得到最终的正确答案 C
This Work
本文针对的数据集是:CommonsenseQA
本文的主要工作:
- 自动地从异构知识源中抽取证据,即同时从ConceptNet和Wikipedia文章中抽取知识
- 为每个知识源构建图,来获取证据间的关系结构
- 提出了一个基于图的模型,由两个模块组成:
- 基于图的上下文词表示学习模块
- 为每个知识源都构建图结构,CN中使用自身的三元组,Wiki中通过语义角色标注来抽取出句子的三元组(谓词,论元)
- utilize graph structural information to re-define the distance between words for learning better contextual word contextual word representations
- (利用图结构化信息来 重新定义词之间的距离以学习更好的上下文词表示)
- 基于图的推理模块
- 使用GCN编码图信息
- 使用图注意力机制聚集证据信息
- 基于图的上下文词表示学习模块
- 在CommonsenseQA上取得了当前最好的效果
Model
CommonsenseQA 的任务形式:
输入:问题 $Q = {q_1, …, q_m}$ 和包含五个选项的候选答案集合 $A = {a_1, a_2, …, a_5}$
目标:从候选集合中选出正确答案
评价指标:准确率
本文提出的框架: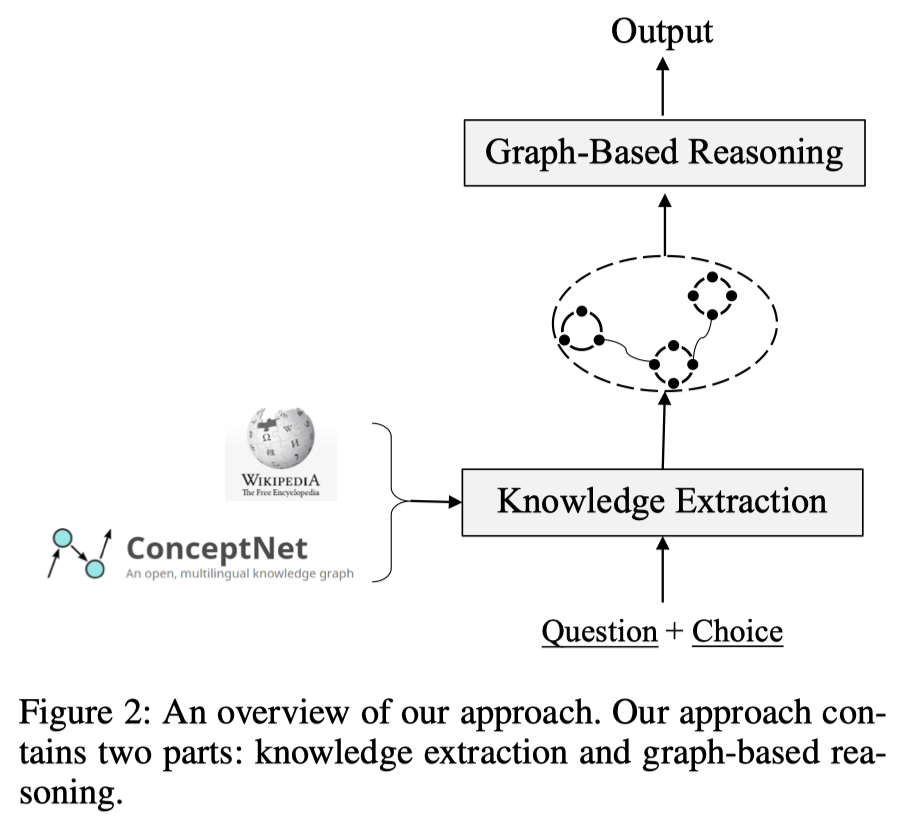
Knowledge Extraction
知识抽取,主要是对数据进行预处理的阶段
Knowledge Extraction from ConceptNet
构建 Concept-Graph :
1、对于每个问题和选项,在CN中确定其中出现的实体;
2、构建从问题中的实体到候选中的实体的路径:
- 小于 3 hops
3、对于从CN中抽取出来的路径拆分为三元组,将每个三元组看做一个节点,融合到图中:
- 如果两个三元组中包含相同的实体,就在图中相应的两点之间增加一条边
- 问题:为什么将三元组对应为图中的一个点?而不是之间利用CN原生的节点-关系结构
4、为了获取CN中节点的上下文词表示,将三元组根据关系模板转化为自然语言语句
Knowledge Extraction from Wikipedia
使用的 Wikipedia 版本信息:version enwiki-20190301
Wikipedia 文本处理:
1、使用 Spacy 从中抽取出 107M 个句子, 并用 Elastic Search 工具构建句子索引
2、对于每个训练样例,去除问句和候选中的停用词,然后将所有词串联,作为检索查询
3、使用 Elastic 搜索引擎 在检索查询和所有句子之间进行排序,选择出 top-K 个句子作为 Wikipedia 提供的证据信息,在实验中 K=10
构建 Wiki-Graph :
1、使用SRL抽取出 句子中每个谓词的论元 (主语和宾语)
2、将论元和谓词都作为图中的节点,谓词和论元之间的关系作为边
3、为了增强图的连通性,基于下述两条规则来在 节点 a 和 节点 b 之间加入边 (首先去除停用词):
- b 中包含 a 且 a 的词数大于3
- a 与 b 仅有一个不同的词,并且 a 和 b 包含的词数都大于3
Graph-Based Reasoning
基于图的推理模块: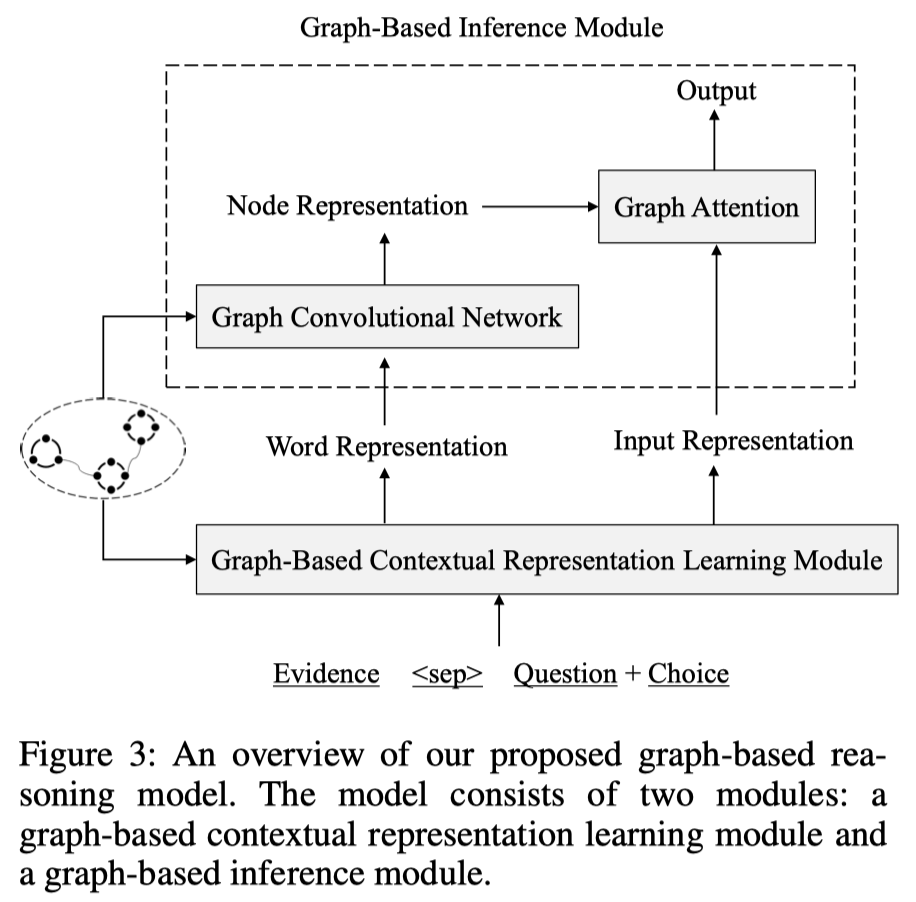
由两部分组成,分别是 1. 基于图的上下文表示学习模块 和 2. 基于图的推理模块
1.Graph-based Contextual Representation Learning Module
本文使用 XLNet 作为基本编码器。
将所有证据信息进行串联,作为 raw input 输入给 XLNet,获得每个词的表示。
这种方式构成的编码器输入存在一个问题:
- 使在不同的知识源中提及的词的距离变远,即便是语义相关的。
- (个人理解,这里是想说同一个词,在不同的证据句中出现的时候,由于仅仅将证据句进行简单串联,而且编码中依然存在长期依赖的问题,所以会造成,在多个证据句中出现的相同词的编码表示是存在较大差异的)
针对这个问题,提出根据 graph 结构,来re-define证据词之间的相对位置。
- 使语义相关的词的相对位置更近一些;
- 并用证据的内部关系结构获得更好的 CWR (contextual word representation);
- 采用的方法是:利用排序算法,根据知识抽取部分得到的图结构,对证据句的顺序进行re-order;
对于 Wikipedia Sentences :
- 构建一个句子图(sentence-graph),证据句是图中的节点
- 当满足以下条件时,在两个句子 $s_i$ 和 $s_j$ 间建立边:
- 如果在 Wiki-Graph 中的 节点 $p$ 和 $q$ 之间存在一条边,且 $p$ 和 $q$ 分别在句子 $s_i$ 和 $s_j$中。
- 然后根据 下图(算法1) 对证据句进行重排序

对于结构化知识CN :
- 根据关系模板,将 CN 中的三元组转化为自然语句,作为 CN 提供的证据句:
- E.g.:
(mammals, HasA, hair)—>mammals has hair
- E.g.:
- 也是根据上图的 算法1 对证据句进行重排序
注:从两个知识源中抽取出的证据句分别排序
(针对算法1的一些看法:深度优先搜索,构建的句子图是无向图,1、在DFS方法定义中,递归调用DFS时没有传递sorted_sequence参数;2、在每次访问完一个节点之后,都将其插入到sorted_sequence的第0位上;3、排序之后,选取多少个句子?)
最终,XLNet 的输入格式为:
- CN Evidence sentences $S^{\prime}_T$ ; Wiki Evidence sentences ; question $q$ ; choice $c$
- 四个部分的串接,用
[SEP]进行分隔 - 在实验部分,对choice还增加了一个头部:
The answer is - 最大长度设为
256 - 得到 word-level clue
2.Graph-based Inference Module
主要目的:在图级别上聚集、传播证据信息,并在图上进行推理以预测最终的答案
1、将 两个证据图 CN-graph 和 Wiki-Graph 看做一个图,使用 GCN 进行编码,获得节点的表示
- 在使用 GCN 的时候,将图看为无向图进行设置
- 节点表示:$i$-th node
- $h_i^0$ 由证据句的 hidden state 的平均得到
- $h_i^0 = \sigma(W \sum_{w_j \in s_i} \frac{1}{|s_i|} h_{w_j})$
- $s_j = \{w_0, …, w_t\}$
- $W \in \mathbb{R}^{d \times k}$
- $h_i^0$ 由证据句的 hidden state 的平均得到
2、证据传播过程,分为两步:聚集 和 组合
(1)从邻居节点聚集信息
- $z_i^l = \sum_{j\in N_i} \frac{1}{|N_i|} V^l h_j^l$
(2)组合,更新节点表示 - $h_i^{l+1} = \sigma(W^l h_i^l + z_i^l)$
($l$ 表示层数,$L$ 表示最终层)
3、利用图注意力,聚集图级别表示,进行最终的预测
- 使用 multiplicative attention,$h^c$ 表示 XLNet 中对应的
[CLS]位置的表示 - 第 $i$ 个节点的重要程度:
- $\alpha_i = \frac{h^c \sigma(W_1 h_i^L)}{\sum_{j\in N h^c \sigma(W_1 h_j^L)}}$
- 最终的图表示
- $h^g = \sum_{h\in N} \alpha_j^L h_j^L$
4、最终的预测打分
- $score(q,a) = \text{MLP}(h^g)$
- $p(q,a) = \frac{e^{score(q,a)}}{\sum_{a^{\prime}\in A} e^{score(q,a^{\prime})}}$
Experiments
实验设置:
- batch size = 4
- 学习率 = 5e-6
- 训练轮数 = 1 epoch (2800 steps)
主实验结果: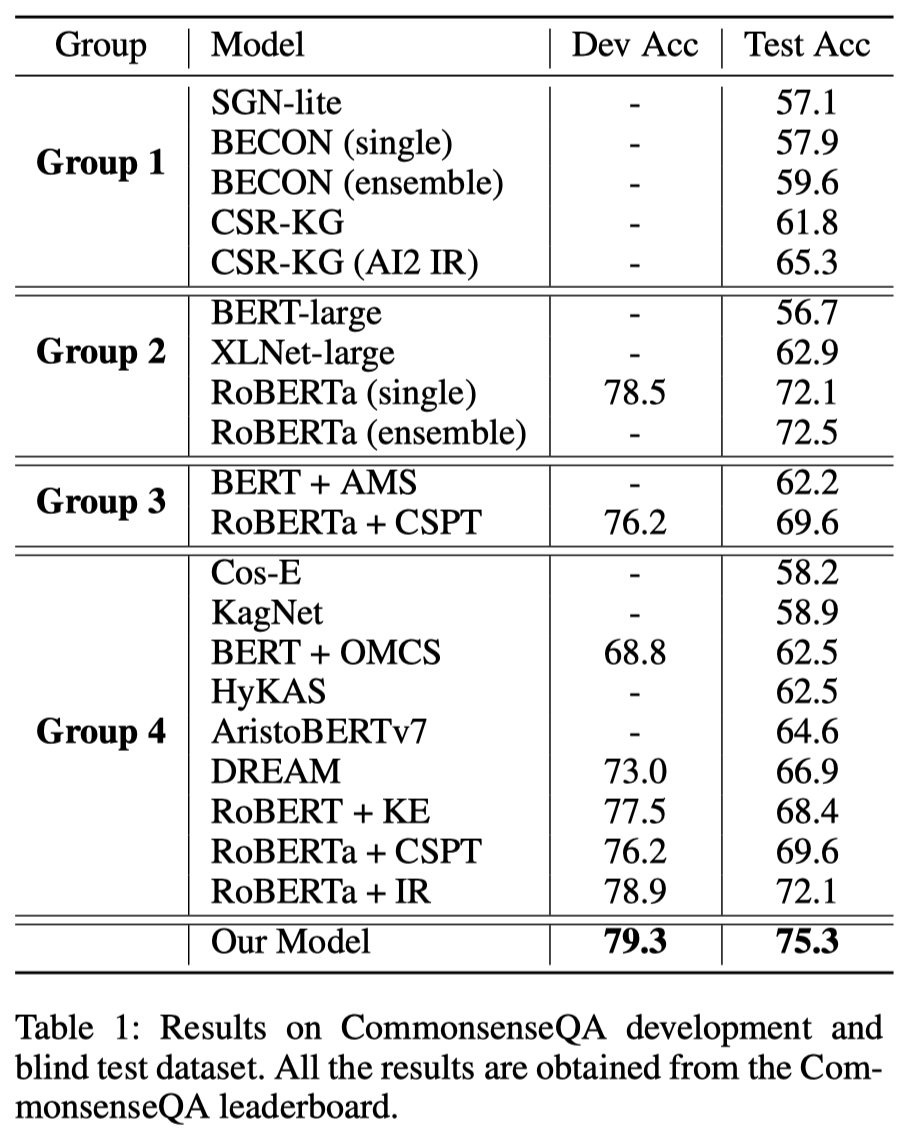
- 给leaderboard上公布出的模型划分了四个组,对比的很全面
Ablation Study
1、对模型组成结构的验证

2、对使用知识源的验证,证实了加入异构来源的知识对最终的性能提升有很大的帮助

Error Analysis
在验证集中随机选择了50个错误样例,错误类型大致分为三种:
- lack of evidence
- similar evidence
- dataset noise
Analysis & Summary
- 论文中涉及到了多个图,在叙述上有些混乱。
- 对于 topology 排序算法的验证,还需要加入一些例子来证明这部分性能提升的缘由,排序之前和排序之后,对于evidence的表示,产生了什么样的影响。
疑问:
- 在CN知识抽取部分,为什么将三元组对应为图中的一个点?而不是之间利用CN原生的节点-关系结构?
- 以句子作为节点,可能会获得更长的context信息,用于表示节点信息?
cose. Explain Yourself! Leveraging Language Models for Commonsense Reasoning. ACL,2019. note ↩