Title: Enhancing Pre-Trained Language Representations with Rich Knowledge for Machine Reading Comprehension
Author: An Yang et al.
Org.: MOE(PKU), Baidu
Published: ACL,2019
Motivation
- 预训练语言模型在机器阅读理解任务上取得了突破性进展。通过在海量无标注文本数据上对足够deep的网络结构进行预训练而得到的LM,能够捕捉复杂的语言现象,更好地理解语言。
- 然而,真正意义上的阅读理解不仅要求机器具备语言理解的能力,还要求机器具备知识以支撑复杂的推理。
- 例如:

- 这个例子需要用到下面的知识
- world knowledge:Trump is the person who leads US
- word knowledge:sanctions has a common hypernym with ban
- BERT在不知道额外知识的情况下无法正确地判断出结果
- 这个例子需要用到下面的知识
This Work
- 为了同时利用强大的PLM捕获的语言规律和外部高质量的知识/事实,提出了语言表示与知识表示的深度融合模型 KT-NET(Knowledge and Text Fusion Net)
- 外部知识使用的是 包含词汇知识的WordNet 以及 包含实体信息的NELL
- 没有采取符号化的知识表示,而是使用了KB embedding,文中给出了两点原因:
- 1、KB embedding 带有整个KB的全局信息
- 2、易于同时融合多个KBs,而不需要过多的task-specific设计
- 在ReCoRD(https://sheng-z.github.io/ReCoRD-explorer/)数据集上取得了SOTA
Model
模型的整体结构如图所示,主要包含4个模块:
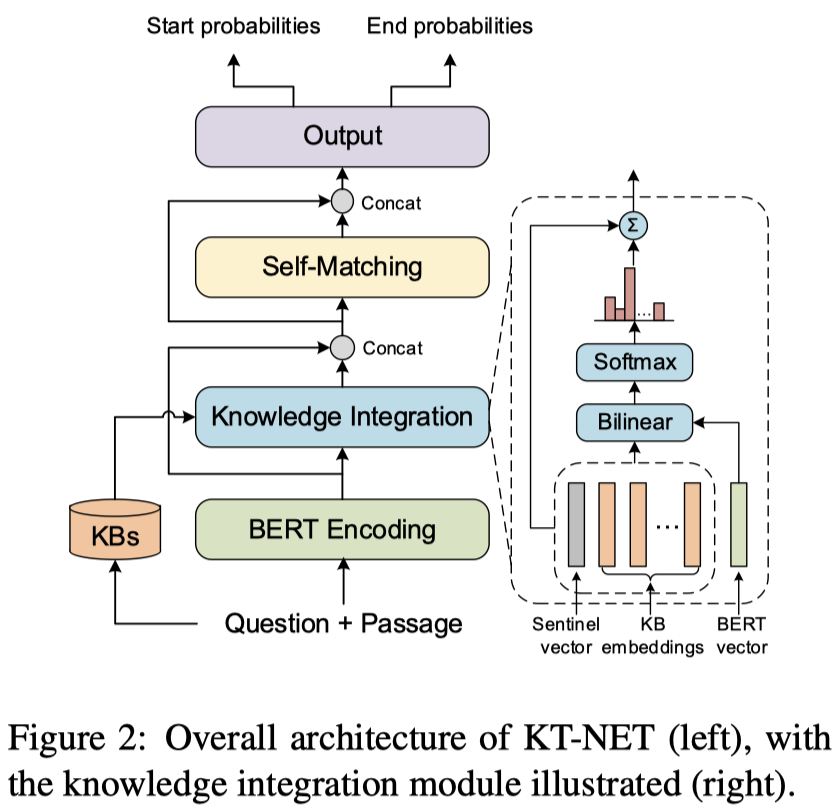
- BERT encoding layer
- knowledge integration layer: select desired KB embeddings and integrate KB representation with BERT representation
- self-matching layer: fuse BERT and KB representations
- output layer: predict the final answer
使用 BERT 进行编码时,将question和passage连在一起输给BERT,question 作为 sentence1,passage 作为 sentence2。
使用 BERT 最后一层的输出 $h_i^L \in \mathbb{R}^{d_1}$ 作为 passage 和 question 中每个token的上下文编码。
下面主要介绍一下KT-NET中最重要的两个模块和KB编码与抽取过程:
Knowledge Integration Layer
对于每个token $s_i$,我们可以得到上下文编码 $h_i^L$,以及检索到的相关KB concepts集合 $C(s_i)$
- $C(s_i)$中的每个 $c_j \in \mathbb{R}^{d_2}$ 是预训练好的KB embedding
使用Attention机制自适应地选择最相关的KB Concepts,同时引入了一个sentinel向量$\bar{c} \in \mathbb{R}^{d_2}$,来控制检索出来的KB Concepts中没有相关KB的情况:
- concept 相关度:$\alpha_{ij} \propto \text{exp}(c_j^\top W h_i^L)$
- $W\in \mathbb{R}^{d_2 \times d_1}$
- sentinel 相关度:$\beta_i \propto \text{exp}(\bar{c}^\top W h_i^L)$
经过Attention之后得到该token的 Knowledge State 表示向量:
- $\mathbf{k}_i = \sum_j \alpha_{ij}c_j + \beta_i \bar{c}$
- 由于sentinel向量的加入,需要对attention score进行约束:$\sum_j \alpha_{ij} + \beta_{i} = 1$
最后,将得到是knowledge state向量与上下文编码表示进行串联,得到本模块的输出:
- knowledge-enriched 表示:$u_i = [h_i^L,k_i] \in \mathbb{R}^{d_1 + d_2}$
Self-Matching Layer
获取了knowledge-enriched表示之后,通过self-attention机制使上下文表示和知识表示进行交互,本文中设计了直接交互和间接交互两种self-attention计算方式
直接(direct)交互:采用的是BIDAF中的trilinear公式计算attention,计算token $s_j$ 和 token $s_i$ :
- $r_{ij} = w^\top [u_i, u_j, u_i \odot u_j]$
- $w \in \mathbb{R}^{3d_1 + 3d_2}$
- row-wise softmax: $a_{ij}=\frac{\text{exp}(r_{ij})}{\sum_j \text{exp} (r_{ij})}$
- attended vector: $\mathbf{v}_i = \sum_j a_{ij} u_j$
- $\mathbf{v}_i$ 表示 每个token j与token i的直接交互程度
间接(indirect)交互:
- 间接交互指的是:token i和token j可以通过一个中间token k产生间接的关联,计算间接交互的方式很简单
- attention matrix $\bar{\mathbf{A}} = \mathbf{A}^2$
- $\bar{\mathbf{v}}_i = \sum_j \bar{a}_{ij} u_j$
最后,将两种交互得到的attended向量表示进行串接,作为本模块的输出:
- $\mathbf{o}_i = [u_i, v_i, u_i - v_i, u_i \cdot v_i, \bar{v}_i, u_i - \bar{v}_i] \in \mathbb{R}^{6d_1 + 6d_2}$
Knowledge Embedding and Retrieval
KB Embedding:
- 采用的是 Yang et al. (2015)[1] 提出的 BILINEAR 算法
KB Concepts Retrieval:
- WordNet:给定一个词,返回其在WordNet中的额同义词集(synsets)作为候选的KB Concepts
- NELL:首先对Passage和Question进行NER,通过字符串匹配在NELL找到实体对应的mention,抽取对应的KB作为候选的KB Concepts
- 每个KB Concept 其实是在KB中对应的尾实体?
在这一部分最后,文中还列举了自身的几点Advantages:
- 之前的一些结合knowledge的MRC工作,都可以算作是一种 retrieve-then-encode 范式,这部分工作只对抽取出来的相关知识进行编码(参考另一篇blognote)与整合,获得的是局部的、与文本相关的知识信息
- 本文的工作首先是在整个KB上预训练出kb embedding,可以捕获全局的信息
- 基于使用的KB Embedding方法来说,是全局的表示
- 易于扩展至融合多个KB的信息
- 对于每个token可以从不同的KB中抽取出不同的KB Concepts集合 $C^j(s_i)$
- 通过不同的KB Concepts集合 $C^j(s_i)$ 计算出不同的 Knowledge State 向量 $k_i^j$
- 直接将多个 $k^j_i$ 与 $h_i^L$ 串联获得融合多个KB的knowledge-enriched表示:$u_i = [h_i^L, k_i^1, k_i^2,…]$
Experiments
- KT-NET中的encoder使用的是BERT-Large-Cased版本,输入最大长度限制为 384,学习率 3e-05,batch大小为24
- KB embedding是预训练好的,在训练过程中固定,不进行微调
- 实验数据集为:ReCoRD 和 SQuAD
- case study
- 从例子的热力图中,可以明显看出与BERT相比,KT-Net可以使不同的question词对passage中的词赋予不同的相关性,并且具有KB信息的支持,而BERT中,不同的question词对同一个passage中的词的相关性是相近的,也就是说,question中的每个词对于passage中的词的相关性相等,
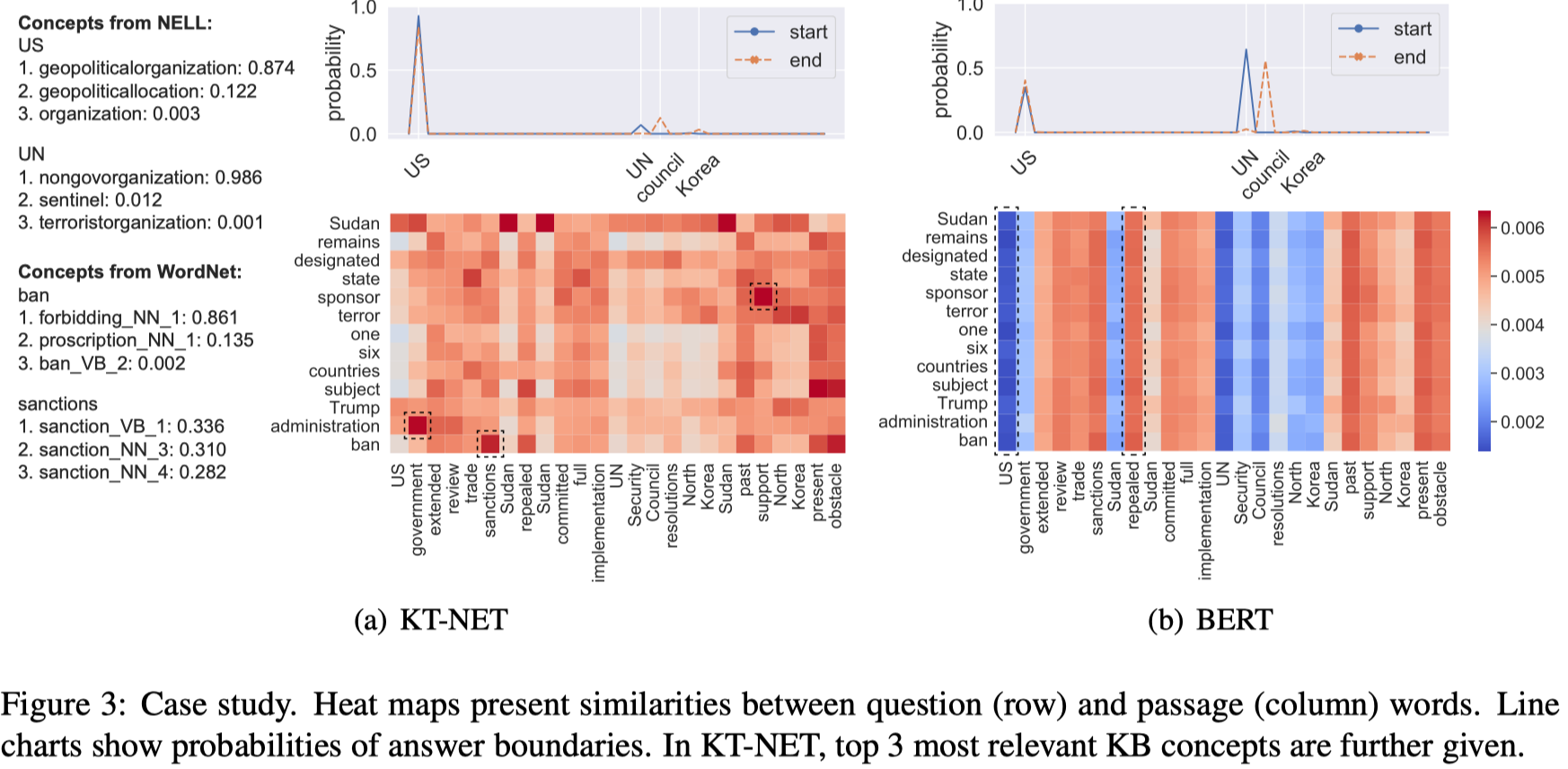
Analysis & Summary
- KT-NET 仅在 ReCoRD 数据集上取得了SOTA的成绩,印象中在leaderboard上放了将近半年也没有其他模型可以超越它的成绩,足以证明这个模型的性能
- 如何选择预训练KB embedding的方法?
- 从在SQuAD数据集上的实验可以看出,相比$KT-NET_{BOTH}$和$KT-NET_{NELL}$,$KT-NET_{wordnet}$取得了最好的结果,可以间接的说明,SQuAD数据集仅需要文本的信息就可以很好的回答问题,并不依赖外部的世界知识(实体信息)
- 1.Embedding entities and relations for learning and inference in knowledge bases. ICLR,2015. ↩