Title: Explicit Utilization of General Knowledge in Machine Reading Comprehension
Author: Chao Wang, Hui Jiang
Org.: York University
Published: ACL,2019
Old Version: Exploring Machine Reading Comprehension with Explicit Knowledge. arXiv:1809.03449
Motivation
- MRC模型和人类之间的差距有两方面
- 1、MRC模型需要大量的训练样例来学习
- 2、MRC模型对于有意加入噪声数据不鲁棒
- 造成差距的原因在于目前MRC模型仅利用了给定passage-question对中的信息,而没有像人类一样利用一些general knowledge
- 如何利用抽取的知识
- 目前的做法都是隐式地将抽取到的知识的编码用于增强相应词的lexical/contextual表示
- 缺点:缺乏解释性和控制性
This Work
- 本文中提出,词之间的语义联系(inter-word semantic connections)可以作为一种general knowledge
- 例如:

- 例如:
此外,本文
- 提出了一种 data enrichment 方法,利用 WordNet 作为知识源,为passage-question对抽取 inter-word semantic connections
- 提出了一个 Knowledge Aided Reader(KAR) 模型,用于显示地将抽取到的 general knowledge 引入到模型中,并辅助 attention 机制
Data Enrichment Method
本文介绍的基于 WordNet 的数据富集的方法是一个可控的抽取过程
Semantic Relation Chain
WordNet 中的几个要素:
- synset:同义集合(a set of words expressing the same sense)
- 一个词可以有多个不同的senses,可以属于多个synset
- semantic relations:synset 之间的语义关系
- 在NLTK中,共有16种
- hypernyms, hyponyms, holonyms, meronyms, attributes, etc.
- 在NLTK中,共有16种
本文根据 synset 和 semantic relation 定义了一个新的概念:Semantic Relation Chain
- 连接一个 synset 与另一个 synset 的一系列 semantic relation(a concatenated sequence of semantic relations)
- semantic relation chain 中的每个 semantic relation 定义为一跳(a hop)
Inter-word Semantic Connection
Data Enrichment 方法的核心问题就是确定两个词之间是否存在 语义的联系(semantically connections)
为了解决这个问题,定义了一个新的概念:扩展同义词集(the extended synsets of a word)
- 定义:通过 semantic relation chain 可以到达的 synset
- 定义符号:$S_w$ 表示 synset,$S_w^*$ 表示扩展同义词集
- 理论上来看,如果不加以限制的话,WordNet 中所有的 synset 都将属于 $S_w^*$
- 故此,引入了一个超参数 $k \in \mathbb{N}$,表示 semantic relation chain 的最大跳数
- 即,只有小于 $k$ 的 chains 才用于构建 $S_w^*$:
- $ S_w^{*}(k) $
- $\text{ if } k=0, \text{ we will have }S_w^{*}(0)=S_w$
构建 inter-word semantic connections,定义:
- 当且仅当 $S_{w_1}^* (k) \cap S_{w_2} \neq \emptyset$ 时,$w_1$ 和 $w_2$ 具有语义关联
General Knowledge Extraction
遵循上述的定义,为给定的 passage-question 对抽取任意词与 passage 中的词的 inter-word semantic relation:
- 只抽取 positional information
- 对词 $w$,抽取一个集合 $E_w$,包含所有 passage 中与 $w$ 有语义关联的词的位置,如果 $w$ 本身是 passage 中的词,去除其本身在 passage 中的位置
- 通过上一节定义的超参数 $k$ 就可以控制抽取的 扩展同义词集 的大小,即抽取出来的 general Knowledge 的数量
- 超参数 $k$ 通过在验证集上的效果确定
Knowledge Aided Reader
KAR 模型的结构如下图所示:
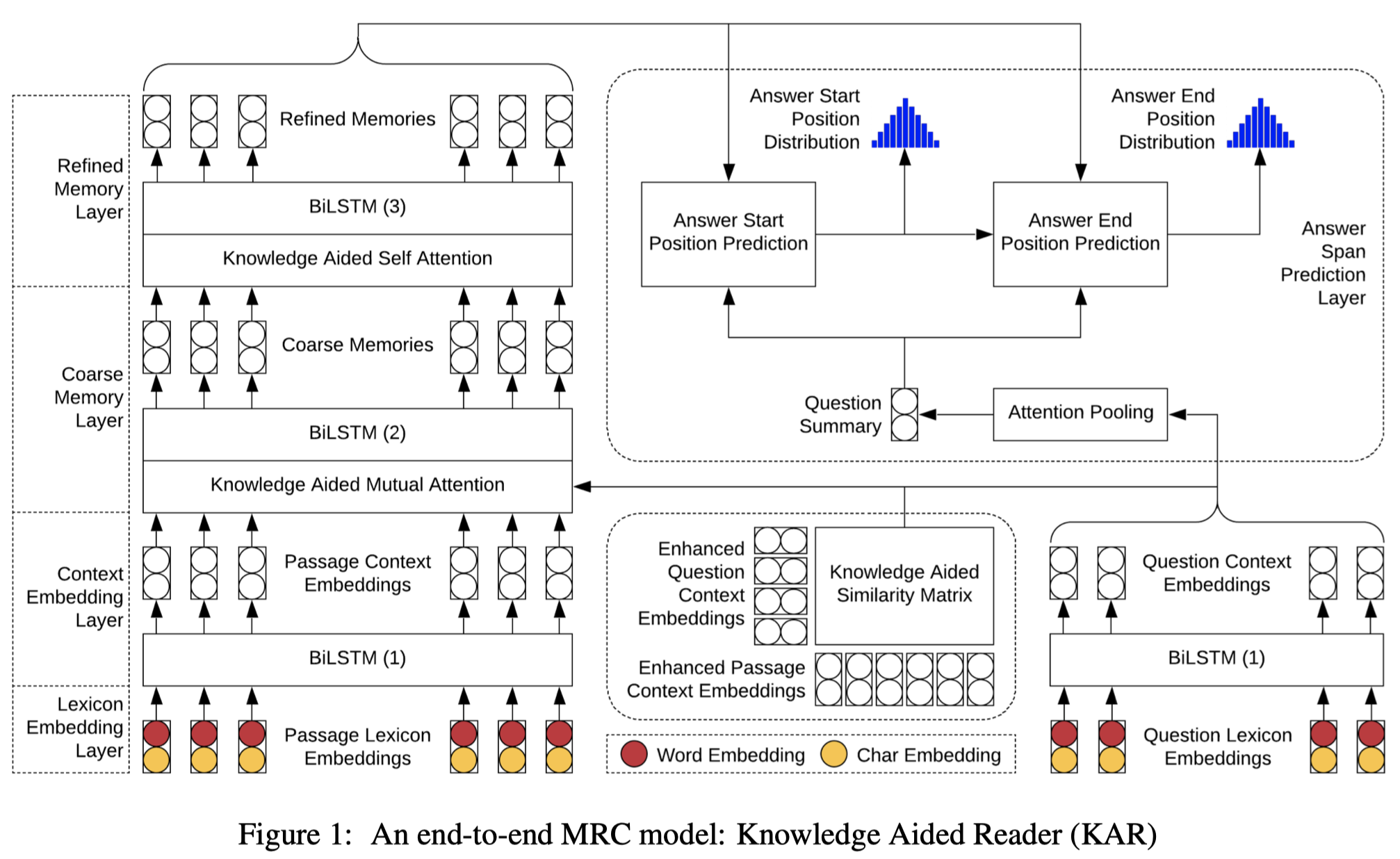
- 与现有的一些模型相比,主要的改进集中在右侧部分的输入和引入 general Knowledge 之后, attention 计算的改进
Notation:
- $P = \{p_1, … , p_n\}$
- $Q = \{q_1, … , q_m\}$
Knowledge Aided Mutual Attention
- 利用提前抽取好的 general Knowledge 为每个词 $w$ 构建 增强的上下文表示 $c_w^*$
- 通过 $E_w$ 和 原始上下文向量 $C_p$ 的对应关系 得到 matching context embeddings $Z \in \mathbb{R}^{d\times |E_w|}$
- 计算 matching vector $c_w^+$
- $t_i = v_c^{\top} tanh(W_c x_i + U_c c_w) \in \mathbb{R}$
- $c_w^+ = Z \text{ softmax} ({t_1,…,t_{|E_w|}}) \in \mathbb{R}^{d}$
- $c_w^* = \text{ReLU}( \text{MLP}([c_w ; c_w^+]) )$
- attention 的计算方式 同 BIDAF
Knowledge Aided Self Attention
- 方法同上
Experiments
- 超参数 $k$ 的选择
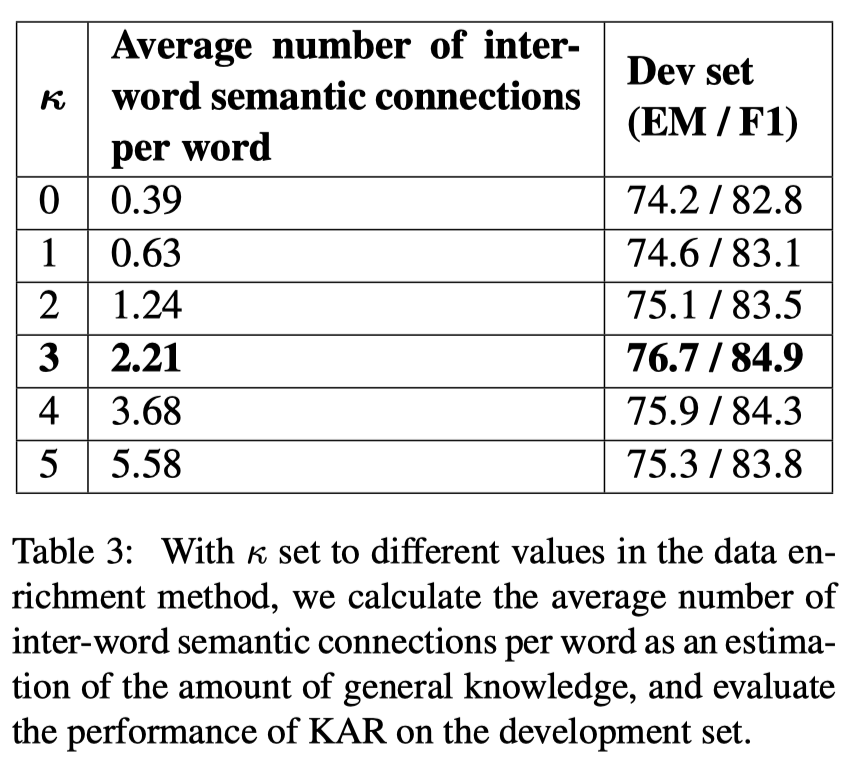
Summary & Analysis
- 抽取出来的 general knowledge 相当于为 passage-question 对中的词构建了一个隐式的关联矩阵,通过这个关联矩阵,在两次 attention 中抽取出对应的 contextual representation 和 coarse memory (result of mutal attention)来辅助增强 attention 的输入