Title: Explain Yourself! Leveraging Language Models for Commonsense Reasoning
Authors: Nazneen Fatema Rajani, Bryan McCann, Caiming Xiong, Richard Socher
Org.: Salesforce Research
Published: ACL 2019
official code: https://github.com/salesforce/cos-e
Motivation
Commonsense reasoning that draws upon world knowledge derived from spatial and temporal relations, laws of physics, causes and effects, and social conventions is a feature of human intelligence.
However, it is difficult to instill such commonsense reasoning abilities into artificial intelligence implemented by deep neural networks. While neural networks effectively learn from a large number of examples, commonsense reasoning for humans precisely hits upon the kind of reasoning that is in less need of exemplification.
Rather, humans pick up the kind of knowledge required to do commonsense reasoning simply by living in the world and doing everyday things.
AI models have limited access to the kind of world knowledge that is necessary for commonsense reasoning.from official blog: https://blog.einstein.ai/leveraging-language-models-for-commonsense/
- DL 模型在需要常识推理的任务上表现不佳,原因可能是往往需要某种形式的世界知识,或是推理的信息未在输入中直接显示出来
- 虽然已经有了一些用于检验模型Commonsense推理能力的数据集,但是 it is still unclear how these models perform reasoning and to what extent that reasoning is based on world knowledge.
This Work
- 构建了一个Common Sense Explanations(CoS-E)数据集:收集了人类对于常识推理的解释(模拟人类的常识推理过程)以及highlight annotation(针对问句的)
- 提出了一个常识自动生成解释(Commonsense Auto-Generate Explanation,CAGE)框架:使用CoS-E数据集来训练语言模型,是LM可以自动的产生解释(这个解释可以在训练和推理过程中使用),证明可以有效地利用语言模型来进行Commonsense Reasoning
- 在任务数据集(CommonsenseQA)上取得了10%的提升(Version 1.0)
- 还进行了跨领域迁移的实验
Background and Related Work
- Commonsense reasoning
- Natural language explanations
- Knowledge Transfer in NLP
CoS-E Corpus
Common Sense Explanations 数据集是在基于CommonsenseQA任务数据集上构建的,包含两种形式的人类解释:
- 1、open-ended 自然语言解释 (CoS-E-open-ended)
- 2、对于问句,标注了 highlighted span annotations,标注的是对于预测正确答案起到重要作用的词 (CoS-E-selected)
- 示例:

Algorithm and Model
(在这篇文章中,进行实验时使用的是CommonsenseQA Version 1.0 的数据集,所以只有三个候选答案,在 Version 1.1 中,每个问题对应5个候选答案)
框架图:
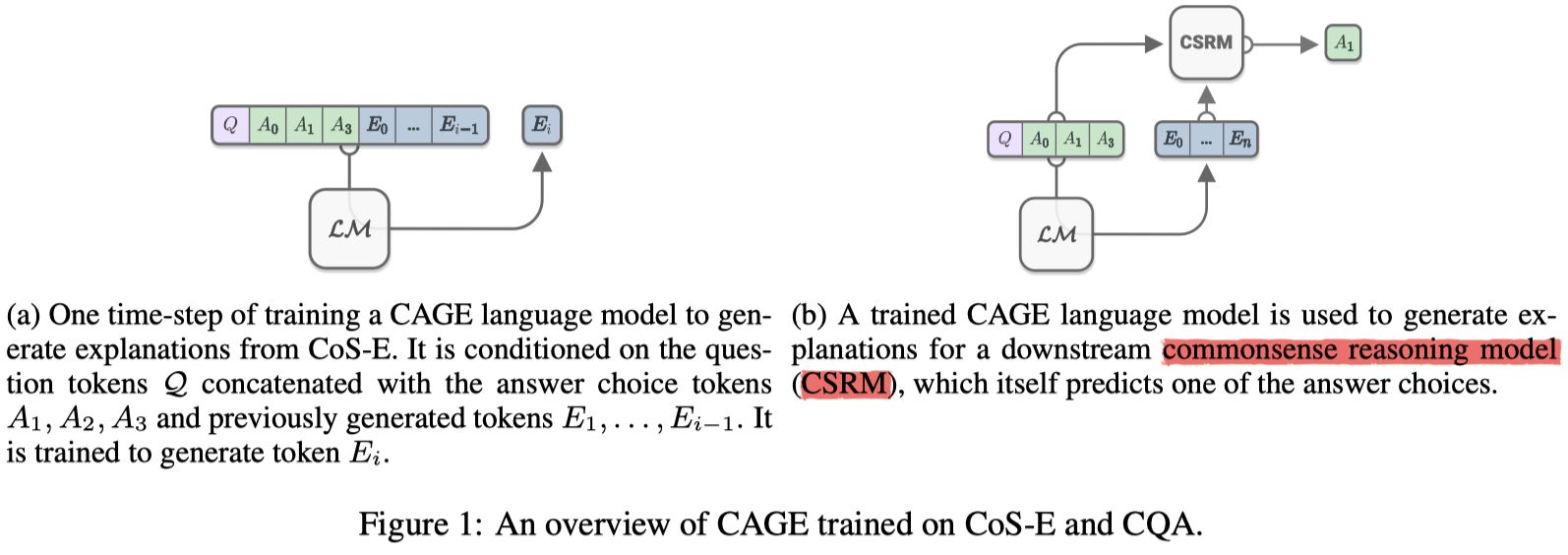
Commonsense Auto-Generated Explanations (CAGE)
在CAGE框架中,使用GPT进行微调。微调部分的框架如上图中的图(a)所示。
本文提出了两种生成解释(即微调GPT-LM)的方法:
- 1、explain-and-then-predict(reasoning)
- 2、predict-and-then-explain(rationalization)
方法一:Reasoning
- 输入:$C_{RE} = q,c_0, c_1, c_2 \text{ ?}\text{ commonsense says} $
- 目标:条件式生成 explanations $e$
- $\sum_i \text{log} P(e_i|e_{i-k},…,e_{i-1}, C_{RE}; \Theta)$
- 其中,$k$ 是语言模型生成句子的窗口大小,在本文中,设为大于explanation的长度
- 称为reasoning的原因:
- 在推理阶段也可以自动的生成explanation,为常识问答提供额外的上下文
- Note:在生成explanation的过程中不知道正确答案的标签
方法二:Rationalization
- 输入:$C_{RA} = q,c_0, c_1, c_2 \text{ ? } a \text{ because} $
- 目标:同上
- 在这个算法中,在训练时,生成explanation的过程中是已知正确答案的标签的
- 相当于为正确的 q-a 对 产生一个合理的解释
- 而不是真正的常识推理
CAGE的参数设置:
- 最大序列长度:20
- batch size:36
- train epochs:10
- learning rate:$1e-6$
- warmup linearly with proportion $0.002$
- weight decay:0.01
- 模型选择指标:在验证集上的BLEU和perplexity
Commonsense Predictions with Explanations
这部分关注的是,给定一个人类生成的解释或是LM推理生成的解释,使模型在CQA任务上进行预测。见上图图(b)
任务模型采用BERT with multiple choice
- BERT输入:question [SEP] explanation [SEP] candidate answer choice
- 微调BERT的参数:
- batch size:24
- test batch size:12
- train epochs:10
- maximum sequence length:175(baseline=50)
Experiments
这篇文章的实验部分很充分、很完整,包含以下几个方面:
- 使用CoS-E进行CQA任务,在dev上的效果:Table-2
- 仅在训练时应用 CoS-E-open-ended
- BERT baseline:63.8%
- 在BERT中加入CoS-E-open-ended,提升了2个点(65.5%)
- CAGE-reasoning:72.6%
- CQA test set 上的效果见 Table-3
- Table-4:在训练和验证时同时应用CoS-E
- Table-5:在CQA v1.1 测试集上的结果
- 迁移到域外数据集
Summary & Analysis
论文中有意思的几点分析
- explanations可以帮助阐明更长更复合的问题
- CAGE-reasoning 生成的explanations中,有43%的可能性包含答案选项