Authors: Shane Storks, Qianzi Gao, Joyce Y. Chai
Org.: Department of Computers Science and Engineering, Michigan State University
Year: 2019
Paper Link: https://arxiv.org/abs/1904.01172
Abstract
Commonsense Knowledge (CS Know.) 和 Commonsense Reasoning 是机器智能的两大重要瓶颈。
现有的NLP研究中,已经提出了一些需要常识推理的benchmarks和tasks,旨在评估机器获得和学习常识知识的能力。
这篇文章的主要目的是针对NLU的常识推理,提供关于以下四个方面的一个综述:
- 现有的任务和benchmarks
- Knowledge Resources
Learning and Inference Approachs
关于本篇文章的思维导图:
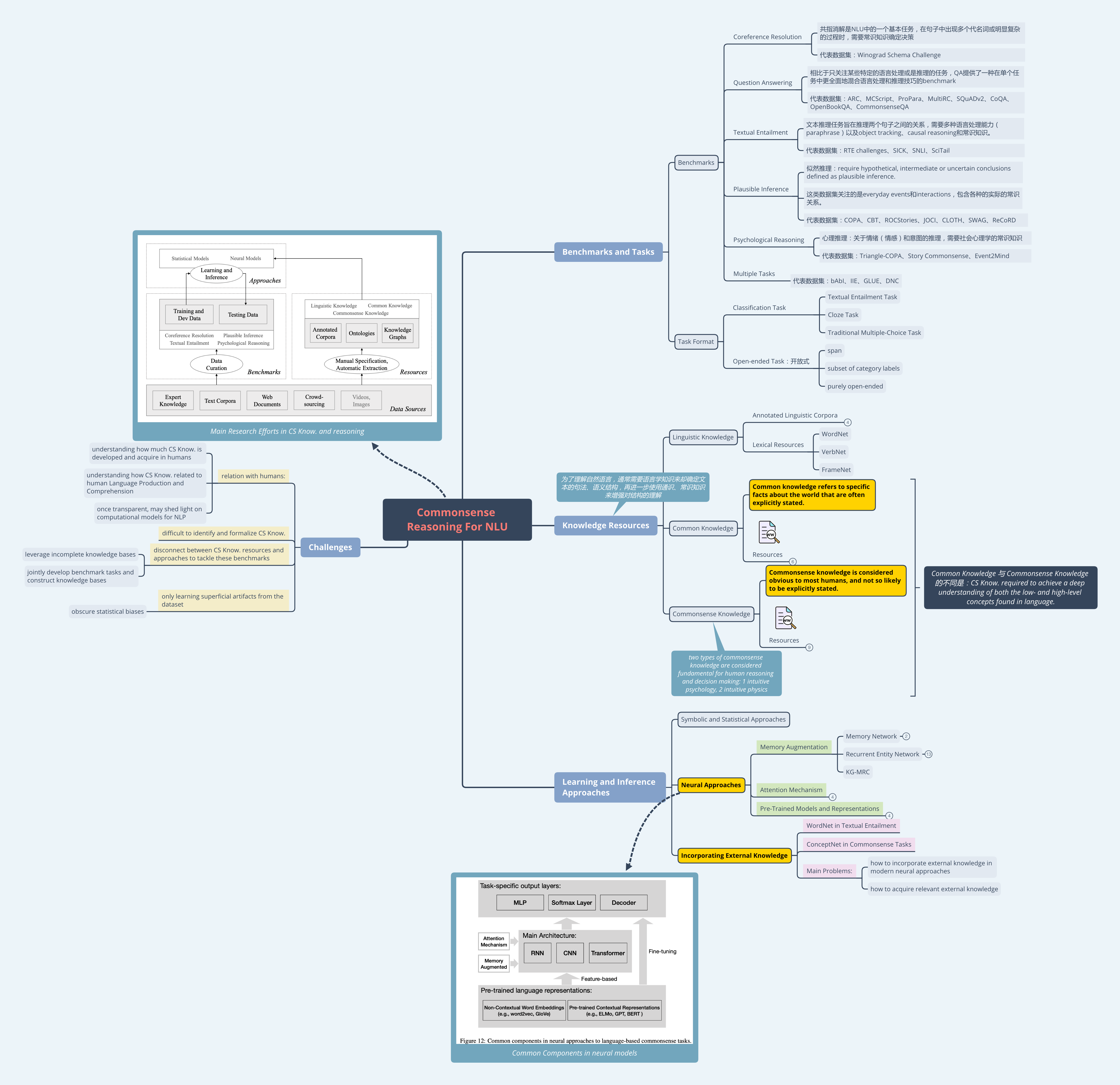
1.Introduction
Davis and Marcus (2015)davis 指出常识推理的挑战:spans from difficulties in understanding and formulating commonsense knowledge for specific or general domains to complexities in various forms of reasoning and their integration for problem solving.
现有的研究主要关注如下图所示的几个方面:(在这篇文章中主要关注文本数据源)
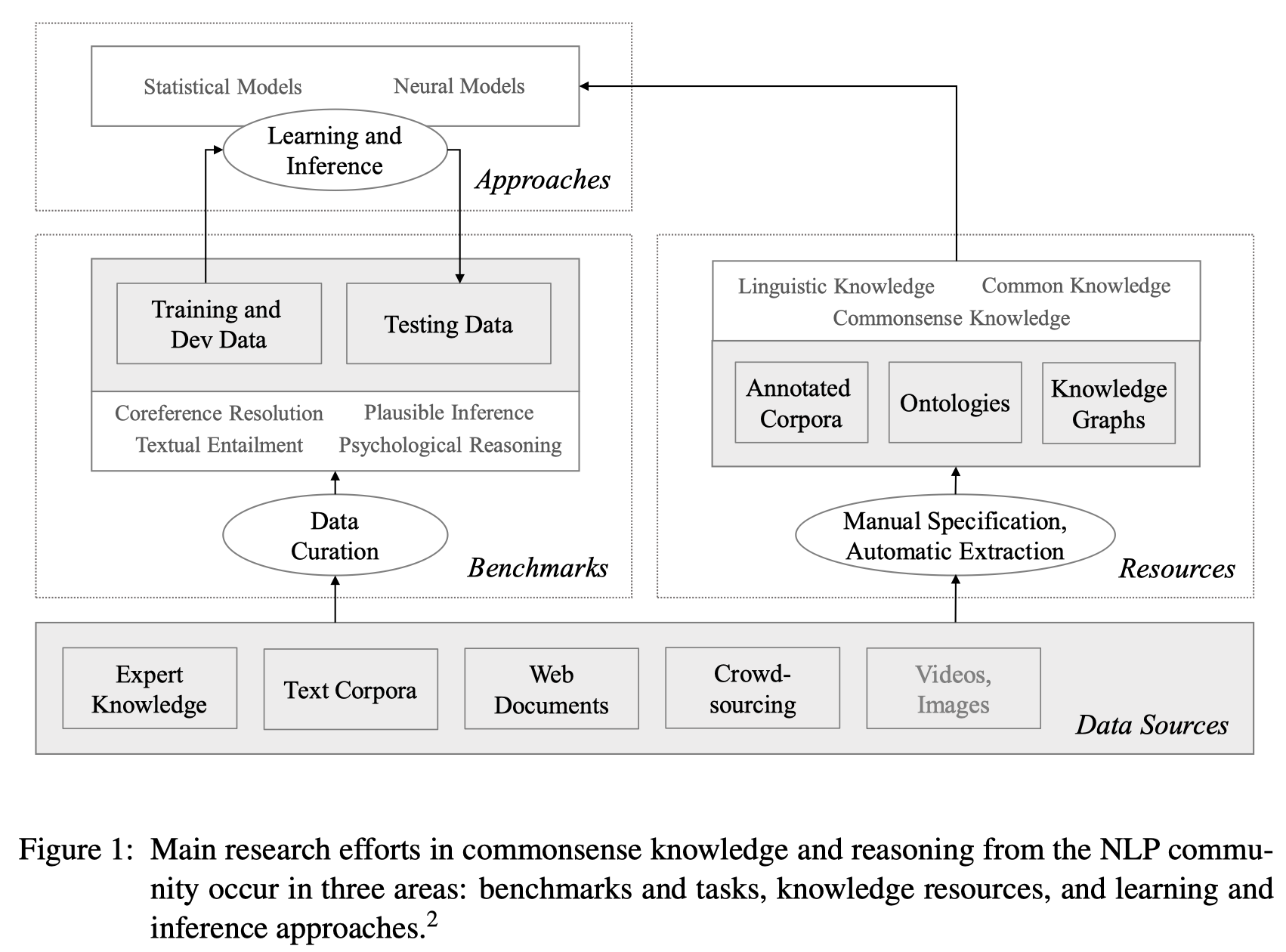
2.Benchmarks and Tasks
这章主要介绍一些需要常识推理的benchmarks,以及对构建这类benchmarks的重要要求进行一个总结。
- benchmarks数据集的发展:
2.1 Overivew of ExistingBenchmarks
很多常识benchmark数据集都是基于classic language processing问题建立起的,从focused task (共指消解、命名实体识别) 到更理解性的任务和应用。
Benchmarks不应该局限于需要 language processing 能力提升性能的类型,应该更有针对性,更关注某类的常识知识和推理 (或是某几类的混合) 。
将Benchmarks分为6类,分别展开介绍
2.1.1 Coreference Resolution
共指消解是NLU中的一个基本任务,在句子中出现多个代名词或明显复杂的过程时,需要常识知识确定决策。
- 代表数据集:Winograd Schema Challenge (link)
2.1.2 Question Answering
相比于只关注某些特定的语言处理或是推理的任务,QA提供了一种在单个任务中更全面地混合语言处理和推理技巧的benchmark。
contain questions requiring commonsense knowledge alongside question requiring comprehension of a given text.
- 代表数据集:ARC、MCScript、ProPara、MultiRC、SQuADv2、CoQA、OpenBookQA、CommonsenseQA
- ProPara:面向过程性文本,旨在学习目标的追踪和状态变化
2.1.3 Textual Entailment
文本推理任务旨在推理两个句子之间的关系,需要多种语言处理能力(paraphrase)以及object tracking、causal reasoning和常识知识。
- 代表数据集:RTE challenges、SICK、SNLI、SciTail
- RTE knowledge resources: https://aclweb.org/aclwiki/RTE_Knowledge_Resources
2.1.4 Plausible Inference
似然推理:require hypothetical, intermediate or uncertain conclusions defined as plausible inference.
这类数据集关注的是everyday events和interactions,包含各种的实际的常识关系。
- 代表数据集:COPA、CBT、ROCStories、JOCI、CLOTH、SWAG、ReCoRD
2.1.5 Psychological Reasoning
心理推理:关于情绪(情感)和意图的推理,需要社会心理学的常识知识
- 代表数据集:Triangle-COPA、Story Commonsense、Event2Mind
- StoryCommonsenserashkin-2018a:要求预测Motivation和Emotions,以及Maslow (human need)、Reiss (human motives)、Plutchik (emotions)
- link:http://uwnlp.github.io/storycommonsense
- Theories of Motivation (Maslow and Reiss) and Emotional Reaction (Plutchik):
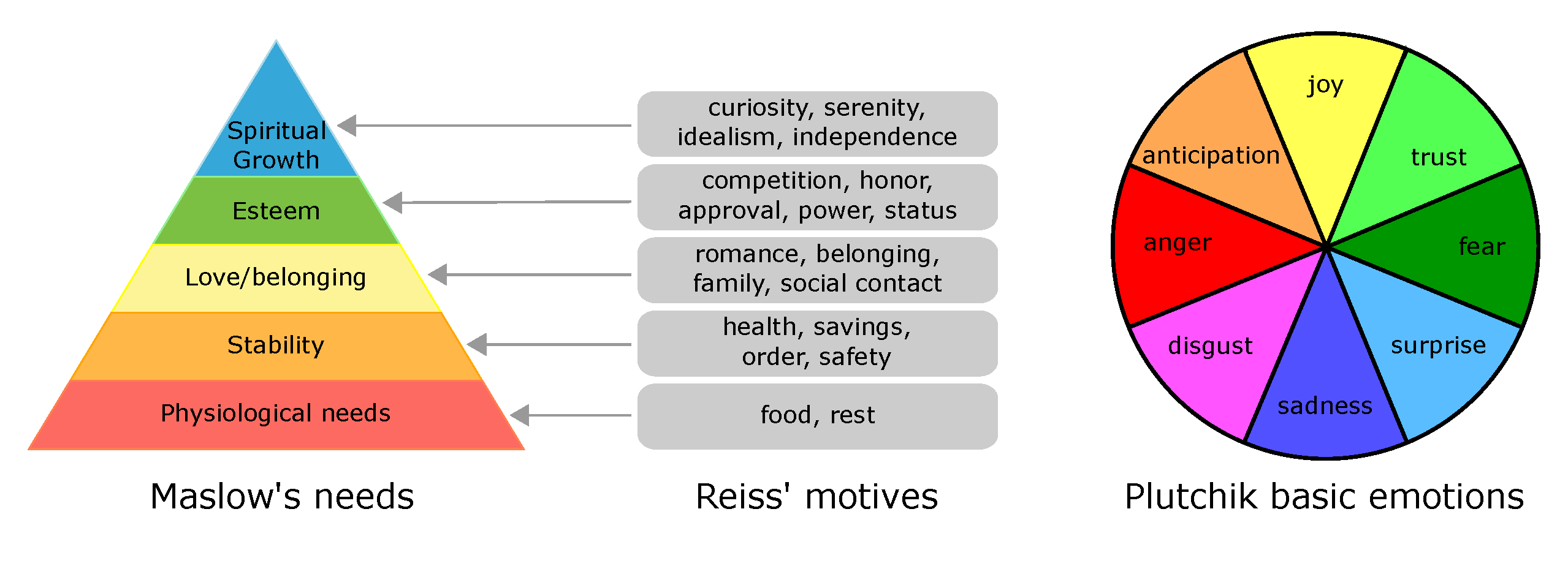
- Event2Mindrashkin-2018b:推理关于事件的intentions和reactions,每个事件都有1到2个参与者,三个任务:预测主要参与者的意图和反应,并预测其他人的反应
- StoryCommonsenserashkin-2018a:要求预测Motivation和Emotions,以及Maslow (human need)、Reiss (human motives)、Plutchik (emotions)
2.1.6 Multiple Tasks
consist of several focused language processing or reasoning tasks so that reading comprehension skills can be learned one by one in a consistent format
- 代表数据集:bAbI、IIE、GLUE、DNC
- IIE:Inference is Everything,RTE的形式
- DNC poliak:Diverse Natural Language Inference Collection,包含9个NLI任务需要7中不同类型的推理
- recast from:
- Event Factuality, recast from UW (Lee, Artzi, Choi, & Zettlemoyer, 2015), MEANTIME (Minard, Speranza, Urizar, Altuna, van Erp, Schoen, & van Son, 2016), and (Rudinger, White, & Van Durme, 2018b)
- Named Entity Recognition, recast from the Groningen Meaning Bank (Bos, Basile, Evang, Venhuizen, & Bjerva, 2017) and the ConLL-2003 shared task (Tjong Kim Sang & De Meulder, 2003)
- Gendered Anaphora Resolution, recast from the Winogender dataset (Rudinger et al., 2018a)
- Lexicosyntactic Inference, recast from MegaVeridicality (White & Rawlins, 2018), VerbNet (Schuler, 2005), and VerbCorner (Hartshorne, Bonial, & Palmer, 2013)
- Figurative Language, recast from puns by Yang, Lavie, Dyer, and Hovy (2015) and Miller, Hempelmann, and Gurevych (2017)
- Relation Extraction, partially from FACC1 (Gabrilovich, Ringgaard, & Subramanya, 2013)
- Subjectivity, recast from Kotzias, Denil, De Freitas, and Smyth (2015)
- link:http://github.com/decompositional-semantics-initiative/DNC
- recast from:
2.2 Criteria and Consideration for Creating Benchmarks
2.2.1 Task Format
决定任务形式对于Benchmarks的创建是重要的一步,现有的任务形式有三类:
- Classification Task:有三种形式
- Textual Entailment Task
- Cloze Task
- Traditional Multiple-Choice Task
- Open-ended Task:开放式任务
- Span
- Subset of category labels:Story Commonsense
- Purely open-ended:Event2Mind、bAbI
Generative
2.2.2 Evaluation Schemes
评测形式
现有的评测结果都是直接给出是否通过(pass or fail grade),没有任何反馈
理想的评测形式应该考虑有信息的指标,可以比较不同的方法,比较机器和人之间性能表现的差异
- Evaluation Metrics:Precision、Recall、F-Measure、Exact-Match、Recall@k、BLEU、ROUGE
- Comparison of Approaches
- Human Performance Measurement
2.2.3 Data Biases
数据分布的平衡
- Label Distribution Bias
- Question Type Bias
- Superficial Correlation Bias:gender bias
2.2.4 Collection Methods
[Not Focus]
- Manual versus Automatic Generation
- Automatic Generation versus Text Mining
- Crowsourcing Considerations
3.Knowledge Resources
3.1 Overview of Knowledge Resources for NLU
为了理解自然语言,通常需要语言学知识来却确定文本的句法、语义结构,再进一步使用通识、常识知识来增强对结构的理解,以达到更全面的理解
3.1.1 Linguistic Knowledge Resources
带标记的句法、语义、篇章结构资源
- Annotated Linguistic Corpora
- Penn TreeBank:POS tags & syntactic structures based on context-free grammar
- PropBank:predicate-argument structures
- Penn Discourse TreeBank
- Abstract Meaning Representation (AMR)
- Lexical Resources
- WordNet
- VerbNet:hierarchical English Verb lexicon
- FrameNet:frame semantics for a set of verbs
3.1.2 Common Knowledge Resources
Common knowledge refers to specific facts about the world that are often explicitly stated.
与Commonsense Knowledge的不同是cambria-2011:CS Know. required to achieve a deep understanding of both the low- and high-level concepts found in language.
- Yet Another Great Ontology (YAGO): with common knowledge facts extracted from Wikipedia, converting WordNet from a primarily linguistic resource to a common knowledge base.
- DBpedia: Wikipedia-based knowledge base originally consisting of structured knowledge from more than 1.95 million Wikipedia articles.
- WikiTaxonomy: consists of about 105,000 well-evaluated semantic links between categories in Wikipedia articles. Categories and relationships are labeled using the connectivity of the conceptual network formed by the categories.
- Freebase
- NELL
- Probase
3.1.3 Commonsense Knowledge Resources
Commonsense knowledge, on the other hand, is considered obvious to most humans, and not so likely to be explicitly stated
Cambria, E., Song, Y., Wang, H., & Hussain, A. (2011). Isanette: A Common and Common Sense Knowledge Base for Opinion Mining. In 2011 IEEE 11th International Conference on Data Mining Workshops, pp. 315–322, Vancouver, BC, Canada. IEEE.
- Cyc
- ConceptNet
- AnalogySpace
- is an algorithm for reducing the dimensionality of commonsense knowledge so that knowledge bases can be more efficiently and accurately reasoned over.
- SenticNet: intended for sentiment analysis
- IsaCore: a set of “is a” relationships and confidences.
- COGBASE
- WebChild
- LocatedNear
- Atlas of Machine Commonsense (ATOMIC)
- about 300,000 nodes corresponding to short textual descriptions of events, and about 877,000 “if-event-then” triples representing if-then relationships between everyday events.
3.2 Approaches to Creating Knowledge Resources
The goal is to create general knowledge bases to provide inductive bias for a variety of learning and reasoning tasks
- Manual Encoding
- Text Mining
- Crowdsourcing
4.Learning and Inference Approaches
4.1 Symbolic and Statistical Approaches
4.2 Neural Approaches
- common components in neural models:
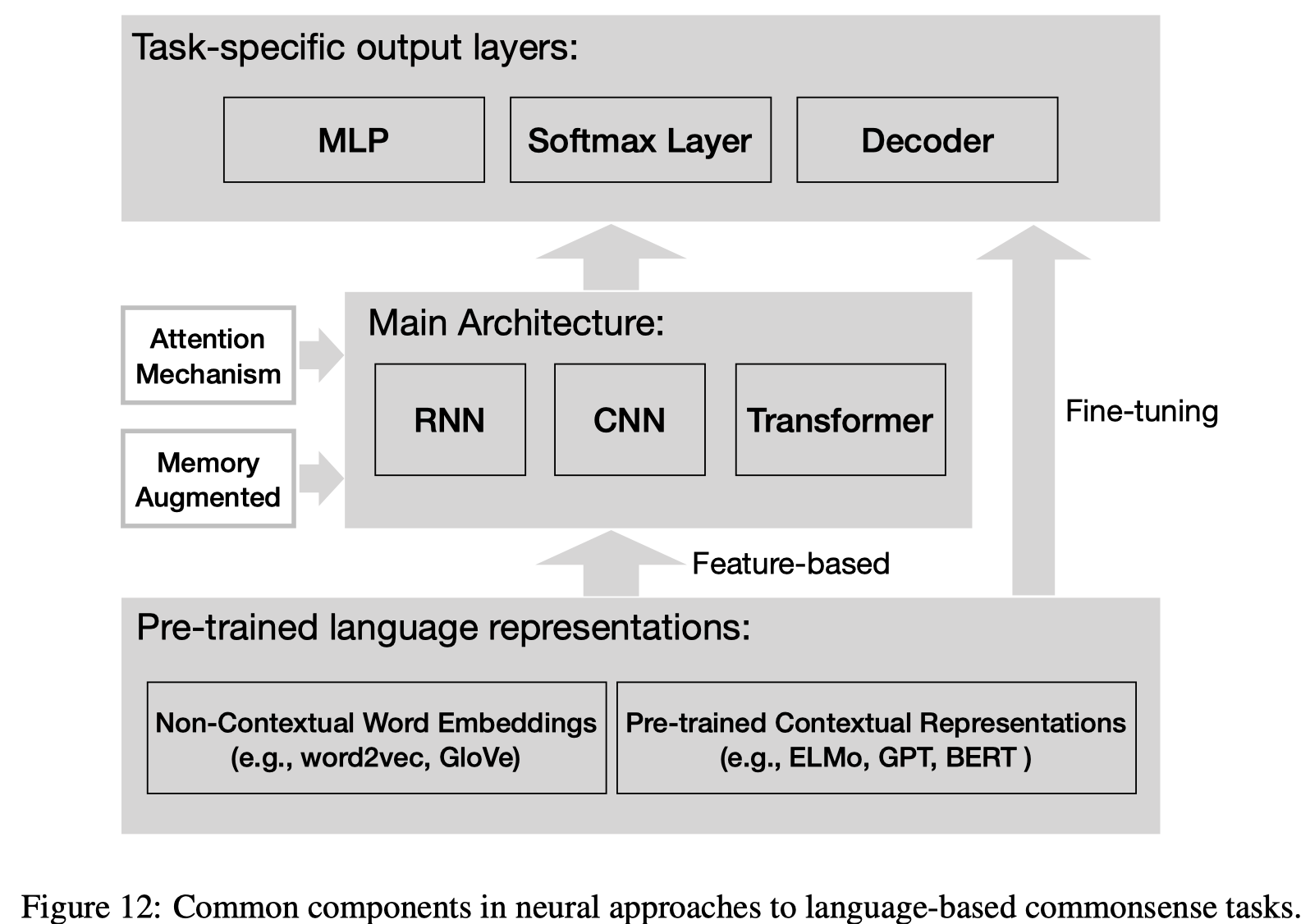
4.2.1 Memory Augmentation
针对需要理解状态变化或是具有多个支撑事实来进行文本理解的任务
Memory Network
- add a long-term memory component to track the world state and context
- MemNet can efficiently leverage a wider context in making inferences
- outperform primarily RNN and LSTM based models
Recurrent Entity Networks (ENTENT)
Henaff, M., Weston, J., Szlam, A., Bordes, A., & LeCun, Y. (2017).
Tracking the World State with Recurrent Entity Networks. In Proceedings of the 5th International Conference on Learning Representations.
ICLR,2017.
- composed of several dynamic memory cell
- each cell learns to represent the state or properties concerning entities mentioned in the input.
- each cell is a Gated-RNN, only updates its content when new information relevant to the particular entity is received
- run in parallel, allow multiple locations of memory to be updated at the same time.
- unlike MemNet:
- MemNet only preform reasoning when the entire supporting text and the question are processed and loaded to the memory.
- when given a supporting text with multiple questions:
- ENTENT do not need to process the input text multiple times to answer these question.
- MemNet need to re-process the whole input for each question.
- drawbacks
- perform well in bAbI, but not in ProPara
- maintain memory registers for entities, it has no separate embedding for individual states of entities over time
- do not explicitly update coreferences in memory
KG-MRC
Das, R., Munkhdalai, T., Yuan, X., Trischler, A., & McCallum, A.
Building Dynamic Knowledge Graphs from Text using Machine Reading Comprehension.
ICLR, 2019
Knowledge Graph Machine Reading Comprehension
- maintain a dynamic memory
- memory is in the form of knowledge graphs generated after every sentence of procedural text.
- generated knowledge graphs:
- are bipartite, connecting entities in the paragraph with their locations (currently, only capture the location relation)
- connections between entities and locations are updated to generate a new graph after each sentence
- KG-MRC learns some commonsense constraints automatically.
- recurrent graph representations help.
4.2.2 Attention Mechanism
- automatically provides an alignment between inputs and outputs
- have limitations when the alignment between inputs and outputs is not straightforward.
- sequentail attention
- self-attention
- multi-head
- comparison score function
4.2.3 Pre-Trained Models and Representations
- ELMO
- GPT
- BERT
- still far from human:
SciTail、ReCoRD、OpenBookQA
- still far from human:
- When to fine-tune
- sentence pair tasks
4.3 Incorporating External Knowledge
- WordNet in Textual Entailment
- ConceptNet in Commonsense Task
- Main Problems:
- how to incorporate external knowledge in modern neural approaches
- how to acquire relevant external knowledge
5.Other Related Benchmarks
- language-related tasks
- visual benchmarks
- perception
6.Discussion and Conclusion
two types of commonsense knowledge are considered fundamental for human reasoning and decision making:
- intuitive psychology:心理
- intuitive physics:物理
Challenges
- relation with humans: understanding how much Commonsense Knowledge is developed and acquire in humans and how they related to human Language Production and Comprehension may shed light on computational models for NLP
- difficult to identify and formalize Commonsense Knowledge
- disconnect between Commonsense Knowledge resources and approaches to tackle these benchmarks
- One likely reason is that these knowledge bases do not cover the kind of knowledge that is required to solve those tasks
- To address this problem, several methods have been proposed for leveraging incomplete knowledge bases
- Eg1 AnalogySpace:uses principle component analysis to make analogies to smooth missing commonsense axioms
- Eg2 Memory Comparison Networks:allow machines to generalize over existing temporal relations in Knowledge Sources in order to acquire new relations
- jointly develop benchmark tasks and construct knowledge bases
- Event2Mind & ATOMIC
- CommonsenseQA & ConceptNet
- One likely reason is that these knowledge bases do not cover the kind of knowledge that is required to solve those tasks
- only learning superficial artifacts from the dataset
- obscure statistical biases — high preformance, but not actual reasoning
davis. Commonsense reasoning and commonsense knowledge in artificial intelligence. Commun. ACM, 58(9), 92–103. ↩
rashkin-2018a. Modeling Naive Psychology of Characters in Simple Commonsense Stories. ACL,2018. ↩
rashkin-2018b. Event2Mind: Commonsense Inference on Events, Intents, and Reactions. ACL,2018. ↩
poliak. Collecting Diverse Natural Language Inference Problems for Sentence Representation Evaluation. EMNLP, 2018. ↩
cambria-2011. Isanette: A Common and Common Sense Knowledge Base for Opinion Mining. In 2011 IEEE 11th International Conference on Data Mining Workshops, pp. 315–322, Vancouver, BC, Canada. IEEE. ↩