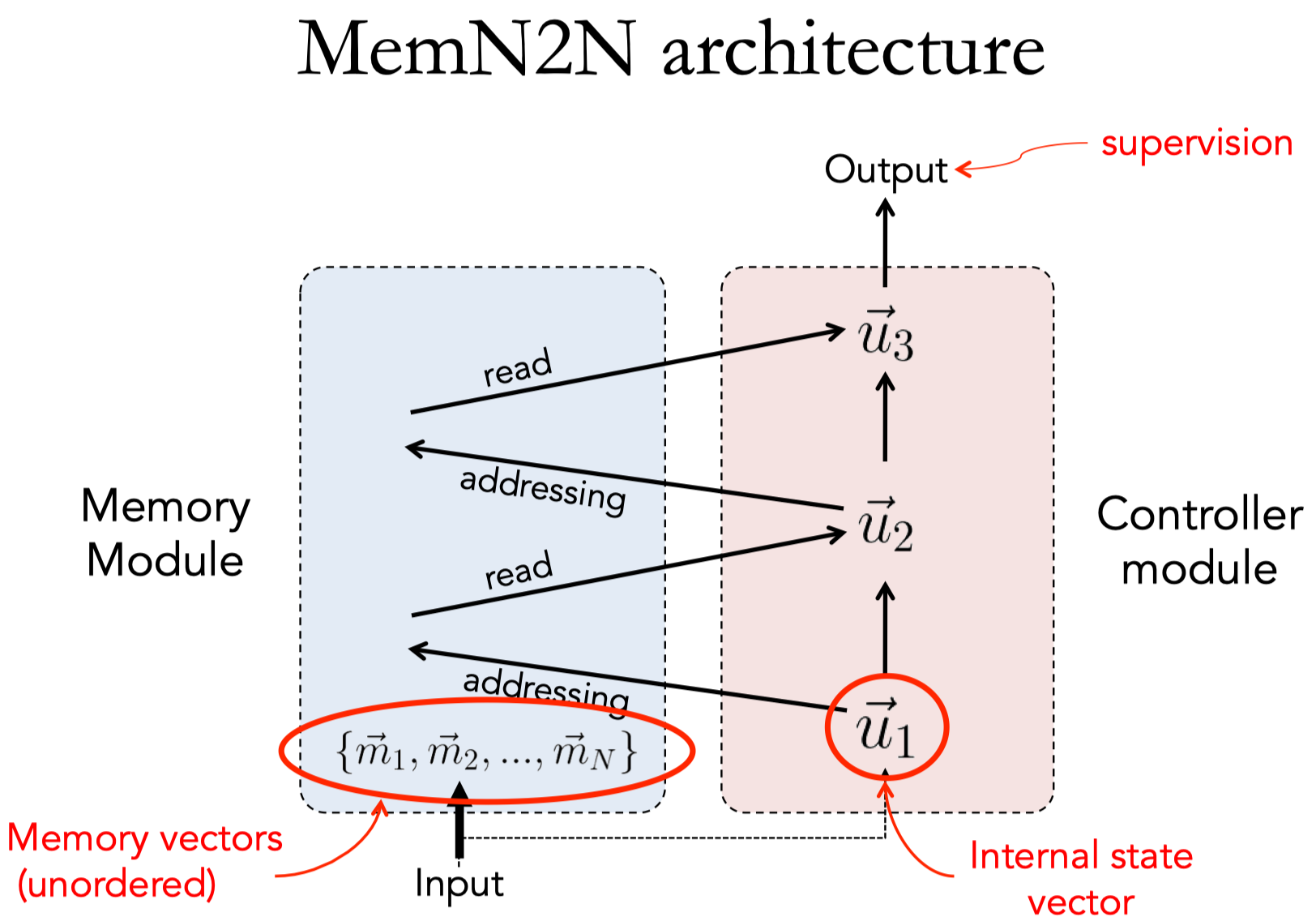
Memory Networks 是一种框架,在这个框架内部的每个module都可以根据特定任务的需要用不同的方式来实现(task-specific)。
本篇主要以 《End-to-End Memory Networks》 (2015, MemN2N) 对 Memory Network 的框架进行介绍。
Architecture
- 记忆网络的核心是记忆模块,可以看做是一个知识存储器。
- 在学习的过程中,首先需要对这个存储器的内容进行插入或更新,然后在测试的时候依靠这个存储器中的信息对于答案进行推理判断,具体包含以下四个主要模块:
- I:输入特征映射
- 将输入转换为内部特征的表示?
- 将输入映射到特征空间
- G:泛化
- 得到新的输入时,对过去的记忆进行更新;
- 称为泛化的原因是:在整个过程中网络能够根据未来的某些特定需要压缩、泛化本身的记忆;
- O:输出特征映射
- 根据当前的输入和记忆状态得到输出,输出的是内部特征表示的形式(以内部特征表示作为输出)
- R:响应
- 将上一步中的输出转换为指定的响应格式;
- I:输入特征映射
- 具体过程:对于一个特定的输入:one-hop
- 1、将转换为内部特征表示的形式;
- 2、根据输入更新记忆;
- 3、根据输入和记忆计算输出特征;
- 4、解码得到响应的结果;
- MemN2N 的模型结构图,左侧是单层结构,右侧是多层(3层)结构
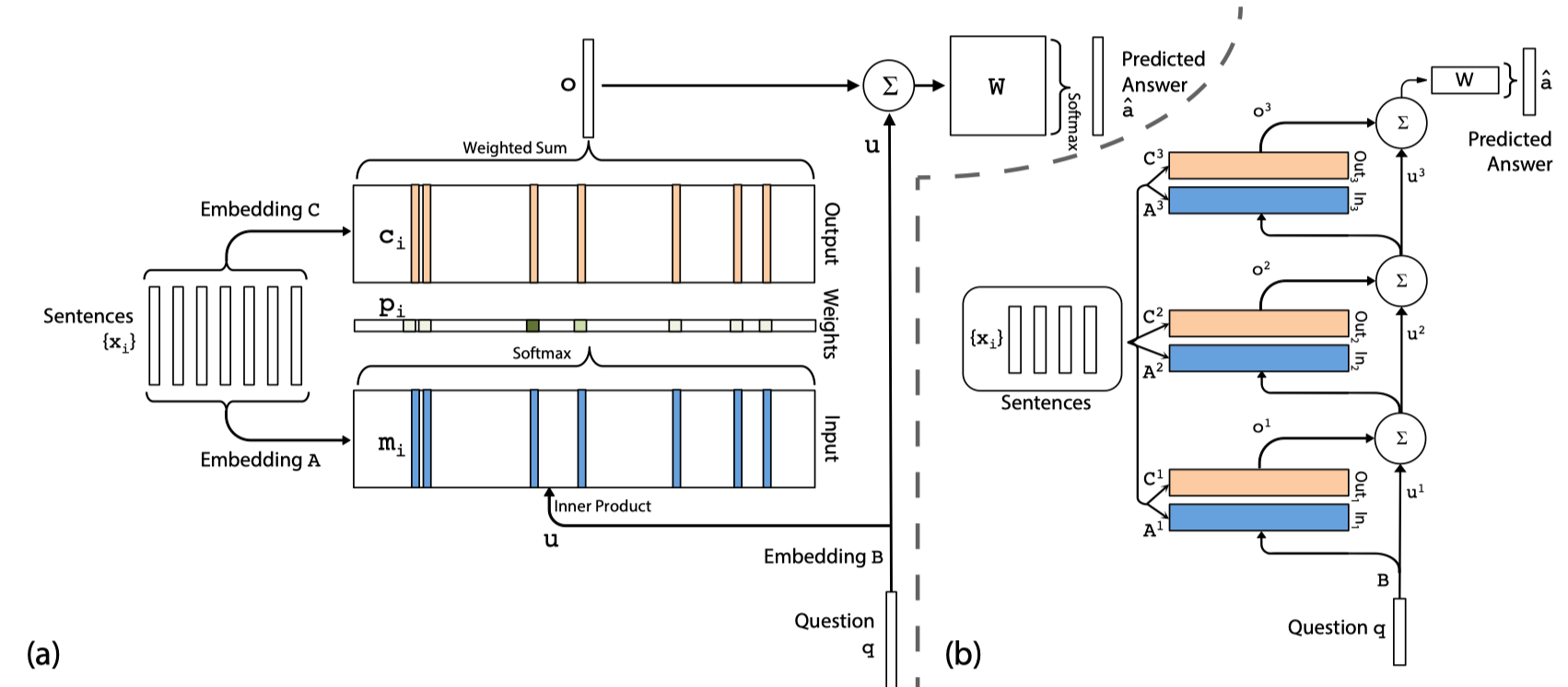
- Multi-hop的计算过程:
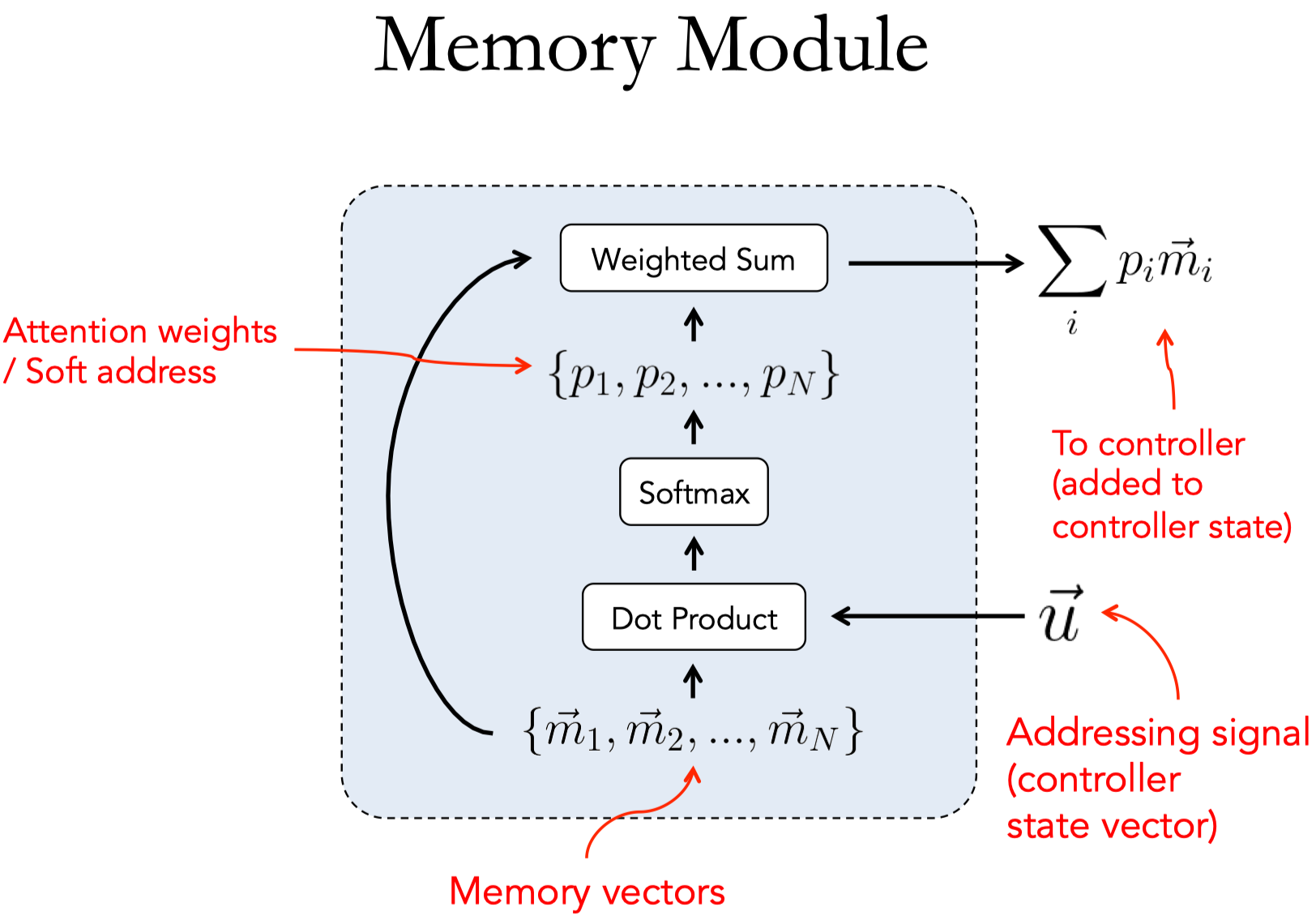
- Memory Module:
Approach Details
- 模型的输入输出:
- 输入:inputs $x_1,…,x_n$ (会被存储到memory中,$x_i$是一个句子) 和 query $q$,词典大小为 $|V|$
- 输出:answer $a$
Single Layer
- input memory representation,将输入映射到特征/memory空间
- 将 $x_i$ 通过 input embedding $A \in \mathbb{R}^{d\times |V|}$ 映射为 memory vector $m_i$
- 将 $q$ 通过 question embedding $B \in \mathbb{R}^{d\times |V|}$ 映射为 internal state $u$
- 计算每个 memory 和 query 之间的attention,得到匹配程度:
- $p_i = softmax(u^T m_i)$
- 有多少个 memory vector 就有多少个 $p$
- output memroy representation:
- 再将 $x_i$ 通过 output embedding $C \in \mathbb{R}^{d\times |V|}$ 映射为相应的 output vector $c_i$
- 计算 response context vector $o$:
- $o = \sum_i p_i c_i$
- generating final prediction:
- 使用 $o$ 和 $u$ 一起预测答案标签(可以是一个词)
- $\hat{a} = softmax(W(o+u))$
- 模型中的主要训练参数为:$A$、$B$、$C$、$W$
Multiple Layers
多层的结构就是对memory进行多次寻址(addressing/attention),每次关注不同的memory,主要的几点不同是:
- 第一层之后的每层/每个hop的 query vector 是前一层的 response context vector 和 query vector 的结合,可以用不同的结合方式计算:
- $u^{k+1} = u^k + o^k$
- 每层之间的embedding矩阵$A^k$和$C^k$不是共享的,具体有两种 权重初始化方式,参考下面的weight typing。
Weight Typing
每个embedding A 和 embedding C 都是与词典大小相等的词向量矩阵,在multiple layers的结构中引入这两个参数矩阵会带来很大的参数开销
- Adjacent方式
- 使第$k+1$层的input embedding $A^{k+1}$ 等于 第$k$ 层的output embedding $C^{k}$:$A{k+1} = C^k$
- 还是增加其他的约束:
- (a) 用最后一层的output embedding $C^{K}$ 去对 answer prediction中的参数矩阵 $W$ 进行赋值:$W^T = C^K$
- (b) 使 question embedding 等于 第一层的input embedding $A^1$:$B = A^1$
- Layer-wise(RNN-like)方式
- 不同的层之间使用相同的embedding参数,在层间加入一个线性映射 $H$ 来更新 $u$:$u^{k+1} = H u^k + o^k$
- 在这种方式下,整体模型可以看成一个传统的rnn,将rnn的输出分为 internal 和 external 两类,$u$ 是rnn的hidden state
Related Works
- Memory Networks
- Ask Me Anything: Dynamic Memory Networks for Natural Language Processing