- focus on the strategy of matching processing between
(P, Q, Ans) - target datasets: RACE, MCScripts
Reference papers on multi-choice MRC task, especially toward matching processing.
- Hierarchical Attention Flow for Multiple-Choice Reading Comprehension. AAAI,2018.
- Dynamic Fusion Networks for Machine Reading Comprehension. 2017.
- A Co-Matching Model for Multi-choice Reading Comprehension. ACL,2018.
- Dual Co-Matching Network for Multi-choice Reading Comprehension. 2019.
- Convolutional Spatial Attention Model for Reading Comprehension with Multiple-Choice Questions. AAAI,2019.
- Option Comparison Network for Multiple-choice Reading Comprehension. 2019
- Yuanfudao at SemEval-2018 Task 11: Three-way Attention and Relational Knowledge for Commonsense Machine Comprehension. 2018.
- HFL-RC System at SemEval-2018 Task 11: Hybrid Multi-Aspects Model for Commonsense Reading Comprehension. 2018.
Co-Match Network (HCM)
Motivation
- previous works: 之前的MRC的工作通常是基于句对的序列匹配(Pair-Wise Sequence Matching),有如下情况:
- passage 与 question 和 candidate answer 的串联进行比较;
- passage 先与 question 进行比较,计算出 matching 结果,再使结果与 candidate answer 进行比较;
这样的计算方式不适用于多选型RC任务,具体存在以下几点问题:
- 1、仅将 passage 和 question 进行匹配,得到的结果可能没有意义并且会导致原始 passage 的信息丢失;
- 例如:问题 Which statement of the following is true?
- 若将 question 和 candidate answer 串联成为一个序列,损失了 question 和 candidate answer 的交互信息;
- 1、仅将 passage 和 question 进行匹配,得到的结果可能没有意义并且会导致原始 passage 的信息丢失;
基于此,多选RC任务需要解决匹配序列三元组 (matching sequence triplets)的问题;
- 本文的方法:
- match a question-answer pair to a given passage;
- explicitly treat the question and the candidate answer as two sequences and jointly match them to the given passage;
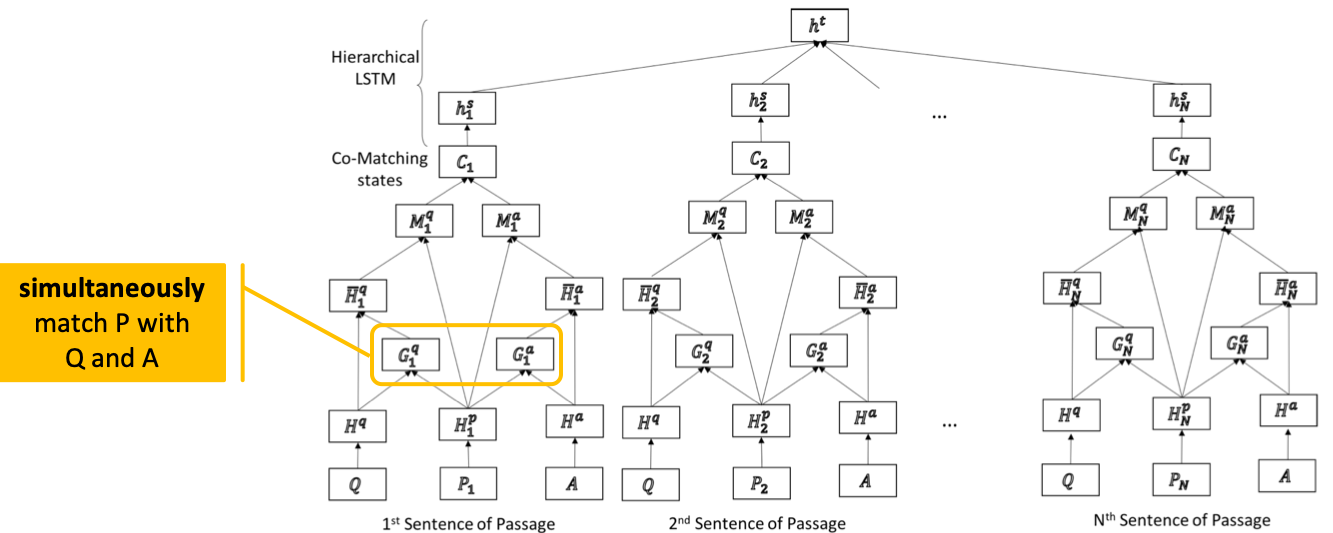
- 对P中的每个位置,都计算两个attention权重,构成两个匹配表示,形成一个co-match状态(同时计算P和Q/A的匹配),然后再用一个层次LSTM框架(2个LSTM)对passage进行编码;
- 层次汇聚信息:
- 在passage中的每个句子内部,信息从word-level汇聚在sentence-level
- 在passage中的句子序列维度上,再从sentence-level汇聚到document-level;
- 可以更好的处理,问题需要的信息分散在passage中不同句子,的情况
- 层次汇聚信息:
- match a question-answer pair to a given passage;
Model Details
Notation:
(one sentence in) Passage: $P\in \mathbb{R}^{d\times P}$
Question: $Q \in \mathbb{R}^{d\times Q}$
(one candidate answer in) Answer: $A \in \mathbb{R}^{d\times A}$
architecture
co-matching
- encoding: the same BiLSTM
- $H^p\in \mathbb{R}^{l\times P}$, 每个句子分别计算
- $H^q\in \mathbb{R}^{l\times Q}$,
- $H^a\in \mathbb{R}^{l\times A}$, 每个候选分别计算
- attention:
- $G^q = softmax( (W^gH^q + b^g \otimes e_Q)^T H^p ) \in \mathbb{R}^{Q\times P}$
- $G^a = softmax( (W^gH^a + b^g \otimes e_Q)^T H^p ) \in \mathbb{R}^{A\times P}$
- aggregation: attentive passage representation
- $\bar{H}^q = H^q G^q \in \mathbb{R}^{l \times P}$
- $\bar{H}^a = H^q G^a \in \mathbb{R}^{l \times P}$
- co-match passage state: concurrently matches a passage state with both the question and the candidate answer. It represent how each P state can be matched with the Q and Candidate A.
- $M^q = ReLU(W^m[\bar{H}^q \ominus H^p; \bar{H}^q \otimes H^p]) + b^m \in \mathbb{R}^{l\times P}$
- $M^a = ReLU(W^m[\bar{H}^a \ominus H^p; \bar{H}^a \otimes H^p]) + b^m \in \mathbb{R}^{l\times P}$
- $W^m \in \mathbb{R}^{l\times 2l}$
- $C = [M^q; M^a] \in \mathbb{R}^{2l \times P}$
- encoding: the same BiLSTM
- hierarchical aggregation
- for each triplet $\{P_n, Q, A\}, n\in [1,N]$, get $C_n$ through co-match
- sentence-level aggregation of the co-matching states:
- sentence sequence representation merge into a single vector
- $h_n^s = MaxPooling(BiLSTM(C_n)) \in \mathbb{R}^l$
- $MaxPooling$: row-wise max pooling
- final triplet matching representation:
- $H^s=[h_1^s, h_2^s,…,h_N^s]$
- $h^t = MaxPooling (BiLSTM (H^s)) \in \mathbb{R}^{l}$
- Output Layer
- for each candidate answer $A_i$, get $h_i^t \in \mathbb{R}^{l} $
- $L(A_i|P,Q) = -log \frac{exp(w^Th_i^t)}{\sum_{j=1}^4 exp(w^T h_j^t)}$
Model Parameters
- word emb dim: 300
- rnn hidden dim: 150
- optimizer: Adamax, lr=0.002
- batch:10
- epochs:30
- dropout:0.2
Dual Co-Matching Network
Motivation
- previous work:
- 只计算了question-aware P表示和 option-aware P表示;
- 一些pretrainLM的做法是将P和Q串联成为一个句子,A单独作为另一个句子;
- 本文:
- model the relationship among passage,question and answer bidirectionally
- 在计算question-aware P表示和 option-aware P表示的同时,计算passage-aware Q表示和passage-aware O表示
Model Details
- Encoding
- $H^p = Bert(P) \in \mathbb{R}^{P\times l}$
- $H^q = Bert(Q) \in \mathbb{R}^{Q\times l}$
- $H^a = Bert(A) \in \mathbb{R}^{A\times l}$
- $l$: Bert hidden state dimension
- Matching Layer
- attention between P and A:
- $W = softmax(H^p(H^a G+b)^T) \in \mathbb{R}^{P\times A}$
- $G \in \mathbb{R}^{l\times l}$
- $M^p = WH^a \in \mathbb{R}^{P\times l}$
- $M^a = W^TH^p \in \mathbb{R}^{A\times l}$
- $W \in \mathbb{R}^{P\times A}$
- $W = softmax(H^p(H^a G+b)^T) \in \mathbb{R}^{P\times A}$
- attention between P and Q in the same method, get:
- $M^q \in\mathbb{R}^{Q\times l}$
- $W^\prime \in \mathbb{R}^{P\times Q}$
- 问题:为什么P和Q进行attention,不计算question-aware的passage表示?
- integration original contextual representation
- $S^a = F([M^a - H^a;M^a \cdot H^a]W_1 + b_1) \in \mathbb{R}^{P \times l}$
- $S^p = F([M^p - H^p;M^p \cdot H^p]W_2 + b_2)\in \mathbb{R}^{A \times l}$
- $F()$ is activation function $ReLU$
- in the question side:
- $S^{p^\prime} \in \mathbb{R}^{P\times l}$
- $S^q \in \mathbb{R}^{Q\times l}$
- attention between P and A:
- Aggregation Layer
- get final representation for each candidate answer
- row-wise max pooling
- $C^p = Pooling(S^p) \in \mathbb{R}^{l}$
- $C^a = Pooling(S^a) \in \mathbb{R}^{l}$
- $C^{p^\prime} = Pooling(S^{p^\prime}) \in \mathbb{R}^{l}$
- $C^q = Pooling(S^q) \in \mathbb{R}^{l}$
- $C = [C^p;C^a;C^{p^\prime};C^q]$
- get final representation for each candidate answer
- Output Layer
- $L(A_i|P,Q)=-log\frac{exp(V^TC_i)}{\sum_{j=1}^N exp(V^TC_j)}$
Model Parameters
No description
Option Comparison Network (OCN)
Motivation
- previous work:
- read each option independently.
- compute a fixed-length representation for each option before comparing them.
- ideas:
- humans typically compare the options at multiple-granularity level before reading the article in detail and make reasoning more efficient.
- 人解决多选RC任务的策略,通常在仔细阅读文章之前会在不同粒度上比较候选答案。
- 通过比较候选答案,可以定位答案选项间的相互关系,在读文章时只关注与选项相互关系有关的文章信息。(更高效?more efficiently and effectively)
- 本文:
- explicitly compare options at word-level to better identify their correlations to help reasoning
- 首先使用一个skimmer network对每个option进行独立编码;
- 然后对每个option,将其与其他的options使用attention进行word-level的比较,来建立option之间的相互比较;
- 最后,带着聚集之后的option间的相关性,重读文章,进行推理和答案选择
- Analysis:
- 这篇文章的主要更新的是option的表示
Model Details
Notation:
Passage: $P=\{w_1^p,…,w_m^p\}$
Question: $Q= \{w_1^q,…,w_n^q\}$
Answer set: $O=\{O_1,…,O_K\}$
Each option: $O_k = \{w_1^o,…,w_{n_k}^o\}$
Overall: 4 stages
- concatenate each (article, question, option) triple into a sequence and use a skimmer to encode them into vector sequences.
- attention-based mechanism is leveraged to compare the options.
- the article is reread with the correlation information gathered in last stage as extra input.
- compute the probabilities for each option.
Option Feature Extraction
- skimmer encoding: 将每个option与P和Q串联构成一个句子,使用BERT进行编码
- $[P^{enc};Q^{enc};O^{enc}_k] = BERT(
- $P^{enc} \in \mathbb{R}^{d\times m}$
- $Q^{enc} \in \mathbb{R}^{d\times n}$
- $O^{enc}_k \in \mathbb{R}^{d\times n_k}$
- $[P^{enc};Q^{enc};O^{enc}_k] = BERT(
- 由于Q和option的关联紧密,将两者串联,作为option的特征
- $O_k^q=[Q^{enc}|O^{enc}_k] \in \mathbb{R}^{d\times n_k^\prime}$
- $n_k^\prime = n+n_k$
- $O_k^q=[Q^{enc}|O^{enc}_k] \in \mathbb{R}^{d\times n_k^\prime}$
- skimmer encoding: 将每个option与P和Q串联构成一个句子,使用BERT进行编码
- Option Correlation Features Extraction
- $Att(\cdot)$的计算方式:假设输入为$U\in \mathbb{R}^{d\times N}$和 $V\in \mathbb{R}^{d\times M}$
- $v \in \mathbb{R}^{3d}$ 是参数
- $s_{ij}=v^T[U_{:i};V_{:j};U_{:i}\circ V_{:j}]$
- $A= Att(U,V;v)=[\frac{exp(s_{ij})}{\sum_i exp(s_{ij})}]_{ij} \in \mathbb{R}^{N\times M}$
- option correlation feature extraction 分3步进行
- option $O_k$ 与其他options进行one-by-one比较,收集 pair-wise correlation信息
- $\bar{O}_k^{(l)}=O^q_l Att(O^q_l,O_k^q;v_o)$
- $\tilde{O}_k^{(l)}=[O_k^q-\bar{O}_k^{(l)};O_k^q \circ \bar{O}_k^{(l)}] \in \mathbb{R}^{2d\times n_k^\prime}$
- option $O_k$ 与其他options进行one-by-one比较,收集 pair-wise correlation信息
- gather pair-wise correlation information
- $\tilde{O}_k^c=tanh(W_c [O_k^q;\{\tilde{O}_k^{(l)}\}_{l\neq k} ])$
- $W_c \in \mathbb{R}^{d\times (d+2d(|O|-1))}$
- $\tilde{O}_k^c=tanh(W_c [O_k^q;\{\tilde{O}_k^{(l)}\}_{l\neq k} ])$
- gather pair-wise correlation information
- element-wise gating 机制控制option feature和option-wise correlation information的融合,以产生option correlation features $O_k^c$
- $g_k \in \mathbb{R}^{d\times n_k^\prime}$
- $g_{k,:i}=\sigma (W_g [Q_{K,:i}^q; \tilde{O}_{k,:i}^c; \tilde{O}]+b_g)$
- $g_{k,:i}$ 表示 g 向量的第i列
- $\tilde{O}$ 的计算:关于 Q 的attention pooling
- $A_q = softmax(v_a^T Q^{enc})^T, v_a \in \mathbb{R}^d$
- $\tilde{O}=Q^{enc}A^q \in \mathbb{R}^{d}$
- option correlation features: $O_k^c\in \mathbb{R}^{d\times n_k^\prime}$
- $O_{k,:i}^c = g_{k,:i} \circ O_{k,:i}^q + (1-g_{k,:i}) \circ \tilde{O}_{k,:i}^c$
- Note: $O_k^c$ 不被压缩成fixed-length向量,文中的解释为-这样可以使我们的模型更灵活的使用correlation信息。
- $g_k \in \mathbb{R}^{d\times n_k^\prime}$
- element-wise gating 机制控制option feature和option-wise correlation information的融合,以产生option correlation features $O_k^c$
- $Att(\cdot)$的计算方式:假设输入为$U\in \mathbb{R}^{d\times N}$和 $V\in \mathbb{R}^{d\times M}$
- Article ReReading
- co-attention + self-attention
- 对于每个option $O_k$ 计算 co-attention:
- $A_k^c = Att(O_k^c,P^{enc};v_p) \in \mathbb{R}^{n_k^\prime \times m}$
- $A_k^p = Att(P^{enc},O_k^c;v_p) \in \mathbb{R}^{m\times n_k^\prime}$
- $\hat{O}_k^p = [P^{enc};O_k^c A_k^c]A_k^p \in \mathbb{R}^{2d\times n_k^\prime}$
- fused with correlation information
- $\tilde{O}_k^p = ReLU(W_p[O_k^c;\hat{O}_k^p]+b_p) \in \mathbb{R}^{d\times n_k^\prime}$
- self-attention to get full-info option representation $O_k^f\in \mathbb{R}^{d\times n_k^\prime}$
- $\tilde{O}_k^s = \tilde{O}_k^p Att(\tilde{O}_k^p, \tilde{O}_k^p;v_r)$
- $\tilde{O}_k^f = [\tilde{O}_k^p;\tilde{O}_k^s;\tilde{O}_k^p-\tilde{O}_k^s;\tilde{O}_k^p \circ \tilde{O}_k^s]$
- $O_k^f = ReLU(W_f\tilde{O}_k^f +b_f)$
- Answer prediciton
- score $s_k = v_s^T MaxPooling(O_k^f)$
- MaxPooling: row-wise
- $v_s \in \mathbb{R}^d$
- probability:
- $P(K|Q,P,O)=\frac{exp(s_k)}{\sum_i exp(s_i)}$
- loss:
- $J(\theta)=-\frac{1}{N}\sum_i log(P(\hat{k}_i | Q_i,P_i,O_i)) + \lambda||\theta||_2^2$
- score $s_k = v_s^T MaxPooling(O_k^f)$
Model Parameters
- for BERT base:
- batch:12
- epochs:3
- lr: $3\times 10^{-5}$
- for BERT large:
- batch:24
- epochs:5
- lr: $1.5\times 10^{-5}$
- $\lambda$: 0.01
- lengths:
- P: 400
- Q: 30
- A: 16