Dynamic Integration of Background Knowledge in Neural NLU Systems
ICLR,2018. Reject
Dirk Weissenborn, et.al.
Datasets: SQuAD, TriviaQA, SNLI, MNLI
Motivation
- the requisite background knowledge is indirectly acquired from static corpora.
- background knowledge learned from task supervision and also by pre-training word embeddings.
- 从静态的训练数据中获取背景知识有两点缺陷:
- 1/不是所有的对解决NLU任务重要的背景知识都可以从有限量的训练数据中抽取出来;
- 2/随着时间的变化,对于理解文本有帮助的事实也会发生变化;
This work:(不同于仅依赖于从训练数据中获取静态知识)
- develop a new reading architecture for the dynamic integration of explicit background knowledge in NLU models.
- a new task-agnostic(任务无关) reading module provides refined word representations to a task-specific NLU architecture by processing background knowledge in the form of free-text statements, together with the task-specific inputs.
Model
输入是:待理解的文本,即context,和抽取出的相关知识的assertions.
然后,使用 word embedding refinement 的策略,增量式地读入context和assertions,最初使用上下文无关的词向量仅初始化.
这种 contextually refined word embedding 可以看成是一种动态记忆,用来存储新结合的知识.
External Knowledge as Supplementary Text Inputs
- 结合知识的形式:
- 本文中并不限制外部信息的形式:无结构/结构化知识都可以作为补充信息
- 结合何种知识:
- 从知识源中抽取上下文相关的信息本身就是个复杂的研究,并且依赖于知识库的形式
- 全面抽取所有潜在的assertions,然后依赖于我们的阅读结构来学习抽取相关的信息
- Assertion Retrieval
- 抽取知识是为了获得句子之间的关联
- 抽取出连接头/尾实体在text中,尾/头实体在question中的知识
- 由于抽取出的assertion过多,使用排序分数对assertions进行打分(类似于tf-idf的打分方式,针对的是罕见但是重要的知识,选择top-k个)
Refine Word Embeddings by Reading
将词向量看做一种记忆,不仅包含通用的知识,还包含上下文信息和抽取的知识信息.
本文提出的增量式 refinement 过程编码输入文本,然后使用多个阅读步得到的编码输入来更新词向量矩阵.
过程如图:
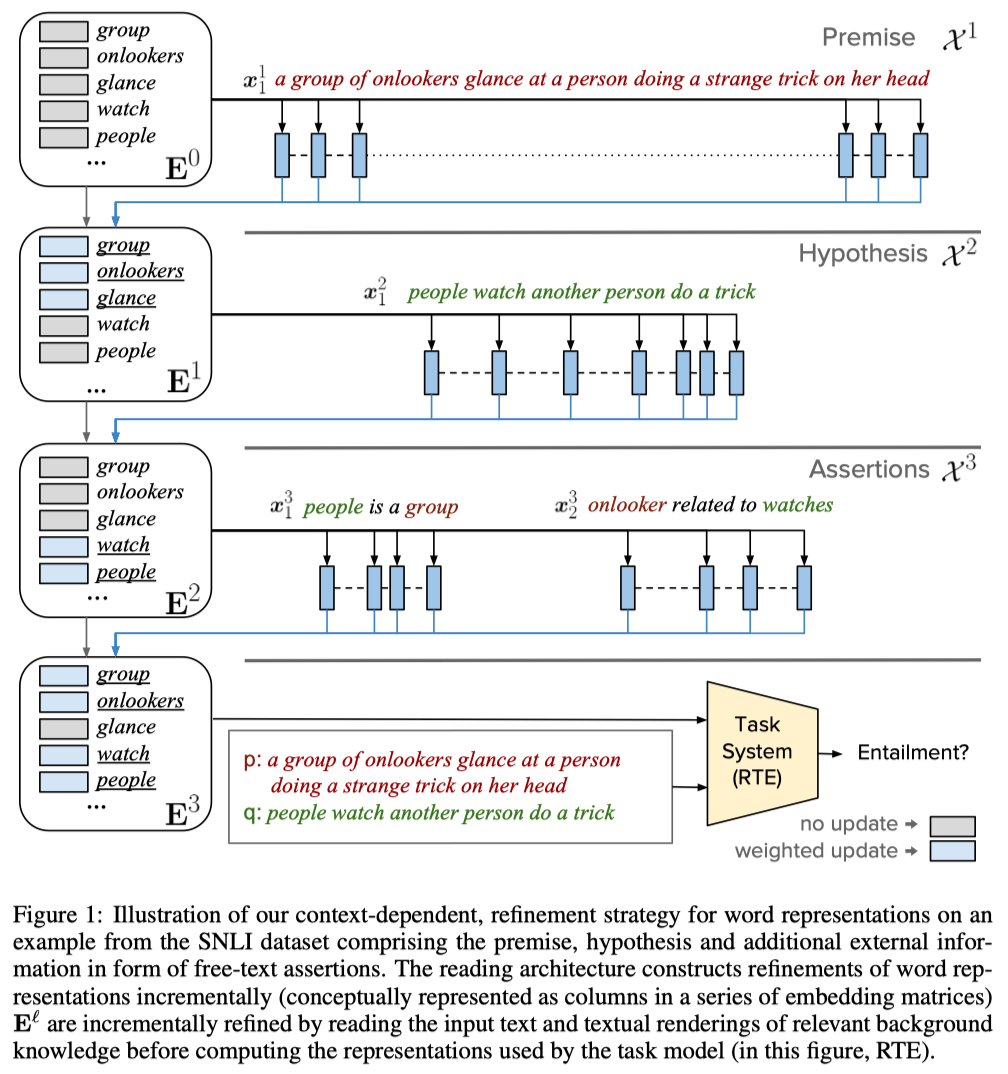
Notations:
- $E^0$: 初始的词向量
- $E^\ell$: 第$\ell$步更新的词向量
- $X^\ell$: 第$\ell$步的上下文信息
- $FC(z)=W z + b, W\in \mathbb{R}^{n \times m}, b\in \mathbb{R}^{n}, z\in \mathbb{R}^m$
1.Unrefined Word Embeddings
这一步的目标是根据预训练词向量$e_w^p \in \mathbb{R}^{n^\prime}$得到初始的non-contextual词表示,计算如下:
- $e_w^{p^\prime} = ReLU(FC(e_w^p))$
- $g_w = \sigma(FC([e_w^{p^\prime} ; e_w^{char}]))$
- $e_w^0 = g_w \cdot e_w^{p^\prime} + (1-g_w) \cdot e_w^{char}$
其中,$e_w^{char}$是通过cnn编码(n convolutional filters w of width 5 followed by a max-pooling operation over time.)得到
2.Contextually Refined Word Representation
在编码输入文本时,
- 给每个词concatenate一个长度为L(即进行refienment处理的次数)的one-hot向量表示对应的位($\ell$)置1,
- 得到输入文本$X_i^{\ell} \in \mathbb{R}^{d\times |x_i^l|}$
- 经过lstm进行context编码: $\hat{X}_i^{\ell} = ReLU(FC(BiLSTM(X_i^{\ell})))$
- 在任务中:$X^1$相当于是Passage(Premise)文本的表示,$X^2$相当于是Question(Hypothesis)的表示,额外的知识assertions是$X^3$
- 在实验中,p\q的顺序对最终的结果没有显著的影响
更新词向量:
- 首先对所有在文本中与此词的lemma相同的词进行一个maxpool:
- $\hat{e}_w^{\ell} = max\{\hat{x}_k^{\ell} | x^{\ell} \in X^{\ell}, lemma(x_k^{\ell}) = lemma(w) \}$
- 然后,用context-independent的表示去计算一个context-sensitive的表示
- 通过门控机制,是模型决定利用多少新读入的信息来改写词向量
- $u_w^{\ell} = \sigma(FC( [e_w^{\ell -1}; \hat{e}_w^{\ell}] ))$
- $e_w^{\ell} = u_w^{\ell} \cdot e_w^{\ell -1} + (1- u_w^{\ell})\cdot \hat{e}_w^{\ell}$
- 关于pooling操作:在具有相同lemma的词上面进行pooling操作
- 有效的联系可以缓解长距离依赖问题
- 更充分的利用输入作为相关背景知识
Experiments
这篇文章的实验是在NLI(SNLI)和DQA(SQuAD)的任务上进行。
对NLI任务上:
- 使用全部的数据进行训练时的提升不是很大
- 但是使用部分数据进行训练时的提升相对较多