Commonsense for Generative Multi-Hop Question Answering Tasks
EMNLP 2018
Lisa Bauer et al. UNC.
Multi-Hop reasoning; generative-mrc; commmonsense knowledge
Datasets: NarrativeQA; QAngaroo-WikiHop
Source code: https://github.com/yicheng-w/CommonSenseMultiHopQA
Motivation
- Multi-Hop Generative Task (e.g. NarrativeQA) requires models to reasong, gather and synthesize disjoint pieces of information within the context to generate an answer.
- This type of multi-step reasoning requires understanding implicit relations (external, background commonsense knowledge).
- Related work:
- some fact-based datasets (e.g. SQuAD) do not need to place heavy emphasis on multi-step reasoning capabilities.
- some multi-hop datasets (e.g. QAngaroo) prompt a strong focus on multi-hop reasoning in very long texts.
- QAngaroo is an extractive dataset where answers are guaranteed to be spans within the context, thus, it more focuse on fact finding and linking.
- This work:
- a. a strong generative baseline, Multi-Hop Pointer-Generator Model, uses a multi-attention to perform multiple hops of reasoning and a pointer-generator decoder to synthesize the answer.
- b. a novel system for selecting grounded multi-hop relational commonsense information from ConceptNet via a pointwise mutual information and term-frequency based scoring function.
- c. a selectively gated attention mechanism to insert selected commonsense paths between the hops of document-context reasoning.
- multi-hop commonsense paths: multiple connected edges within ConceptNet graph that give us information beyond a single relationship triple.
- different aspects of the commonsense relationship path at each hop to bridge different inference gaps in the multi-hop task.
Model
- Model Overview:
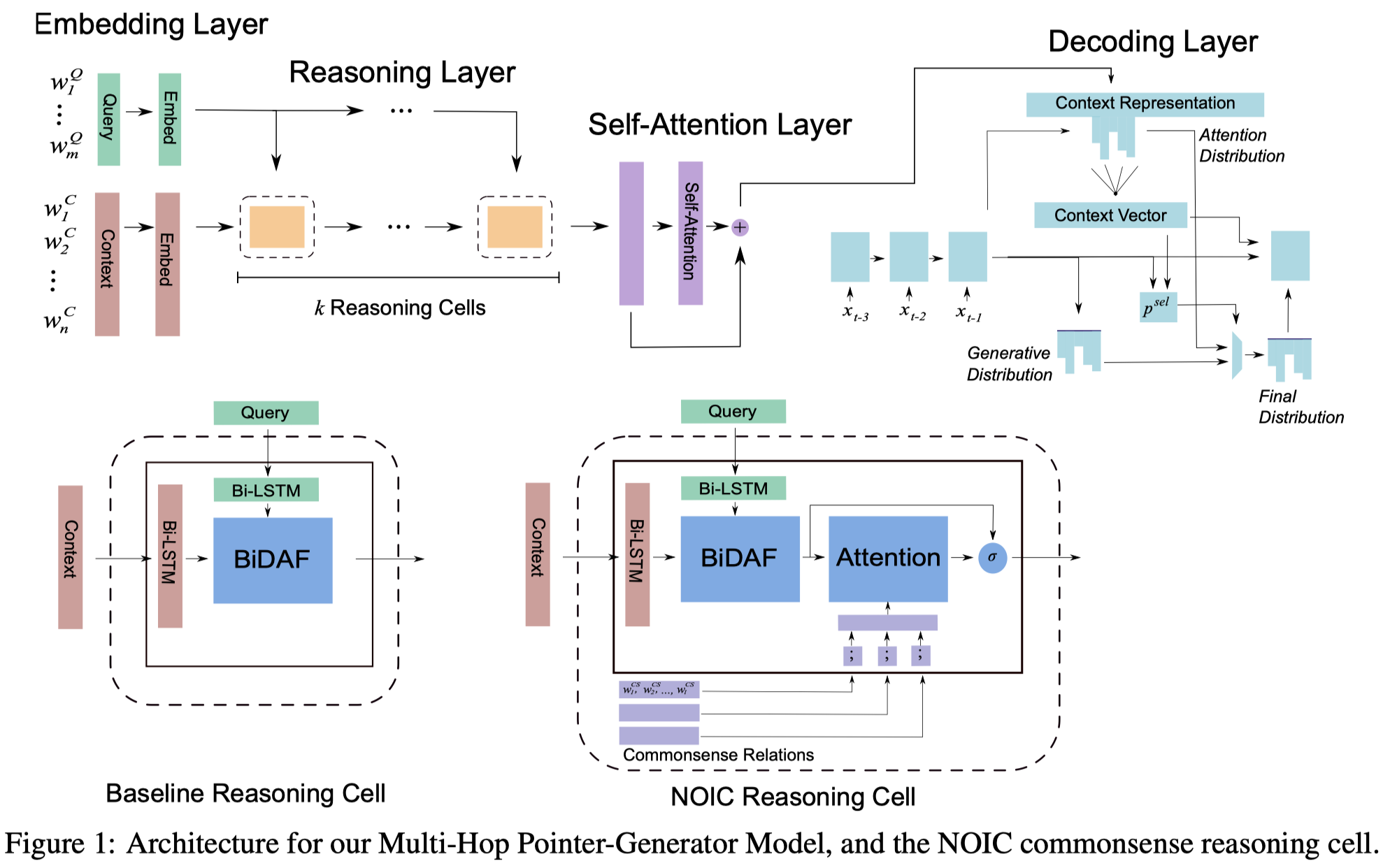
1.Multi-Hop Pointer-Generator Baseline
模型的输入:
- context: $X^C={w_1^C, w_2^C,…,w_n^C}$
- query: $X^Q = {w_q^Q, w_2^Q,…,w_m^Q}$
模型的输出:
- answer tokens: $X^a = {w_1^a,w_2^a,…,w_p^a}$
1.1.Embedding Layer
pretrained word embeddings with ELMO: $e_i^Q$/$e_i^C$ $\in \mathbb{R}^{d+1024}$
1.2.Reasoning Layer
$k$ 个 reasoning cell 增量式地更新 context representation.
第 $t$ 个reasoning cell的计算过程:
- 输入: 前一时刻的输出 $\lbrace c_i^{t-1} \rbrace _{i=1}^n$ 和 query 的向量 $\lbrace e_i^Q \rbrace _{i=1}^m$
- a.通过 cell-specific Bi-LSTM 计算一个 step-specific 的 context 和 query 的编码
- $u^t=BiLSTM(c^{t-1})$; $v_t=BiLSTM(e^Q)$
- b.通过bi-attention 计算 context 中的相关方面 来模拟一个hop的推理:
- context-to-query attention:
- $S_{ij}^t = W_1^t u_i^t + W_2^t v_j^t + W_3^t (u_i^t \odot v_j^t)$
- query-to-context attention vector:
- $m_i^t = \max_{1 \leq j\leq m} S_{ij}^t$
- 更新的context representation:
- $c_i^t = [u_i^t; (c_q)_i^t; u_i^t \odot (c_q)_i^t; q_c^t \odot (c_q)_i^t]$
- $c^0 = e^C$
- 最后一时刻的输出是 $c^k$
- context-to-query attention:
1.3.Self-Attention Layer
- 帮助模型处理long context中的长期依赖
- 输入是 reasoning 层最后一时刻的输出 经过 一个BiLSTM之后的表示 $c^{SA}$
- 计算流程:
- $S_{ij}^{SA} = W_4 c_i^{SA} + W_5 c_j^{SA} + W_6(c_i^{SA}\odot c_j^{SA})$
- $p_{ij}^{SA} = exp(S_{ij}^{SA}) / \left( \sum_{k=1}^n exp(S_{ij}^{SA}) \right)$
- $c^\prime = \sum_{j=1}^n p_{ij}^{SA} c_j^{SA}$
- $c^{\prime\prime} = BiLSTM([c^\prime;c^{SA};c^\prime \odot c^{SA}])$
- $c = c^k + c^{\prime\prime}$
1.4.Pointer-Generator Decoding Layer
输入:
- $x_t$, 前一时刻解码出的词向量表示
- $s_{t-1}$, 前一时刻的隐藏层状态
- $a_{t-1}$, 上下文向量
计算:
- 当前时刻的隐藏层状态:
- $s_t = LSTM([x_t; a_{t-1}], s_{t-1})$
- 计算在生成词典上的概率分布:
- $P_{gen} = softmax(W_{gen}s_t + b_{gen})$
- 计算 attention (使用 Bahdanau 的attention计算过程):
- 计算选择生成还是复制的概率:
- $\mathbf{o} = \sigma(W_a \mathbf{a}_t + W_x x_{t} + W_s s_t + b_{ptr})$
- $\mathbf{p}^{sel} = softmax(\mathbf{o}) \in \mathbb{R}^2$
- 最终 $t$ 时刻输出的分布为:
- 当前时刻的隐藏层状态:
2.Commonsense Selection and Representation
为什么需要常识知识:知识关系有时候没有直接在文本中指出
由于语义网络/知识图谱的规模较大,包含很多无关信息,需要设计有效的选择算法来确定需要的信息 (有用的知识且可以在context-query对中落地(grounded:在context-query中出现) )
常识知识选择策略:包含两方面
- 1.通过树结构,收集潜在的相关知识,目的是选择出具有high recall的候选推理路径;
- 2.通过三步打分策略对候选路径进行排序和过滤,以确保加入信息的质量和多样性;
- Initial Node Scoring, Cumulative Node Scoring, Path Selection
图: Commonsense selection approach
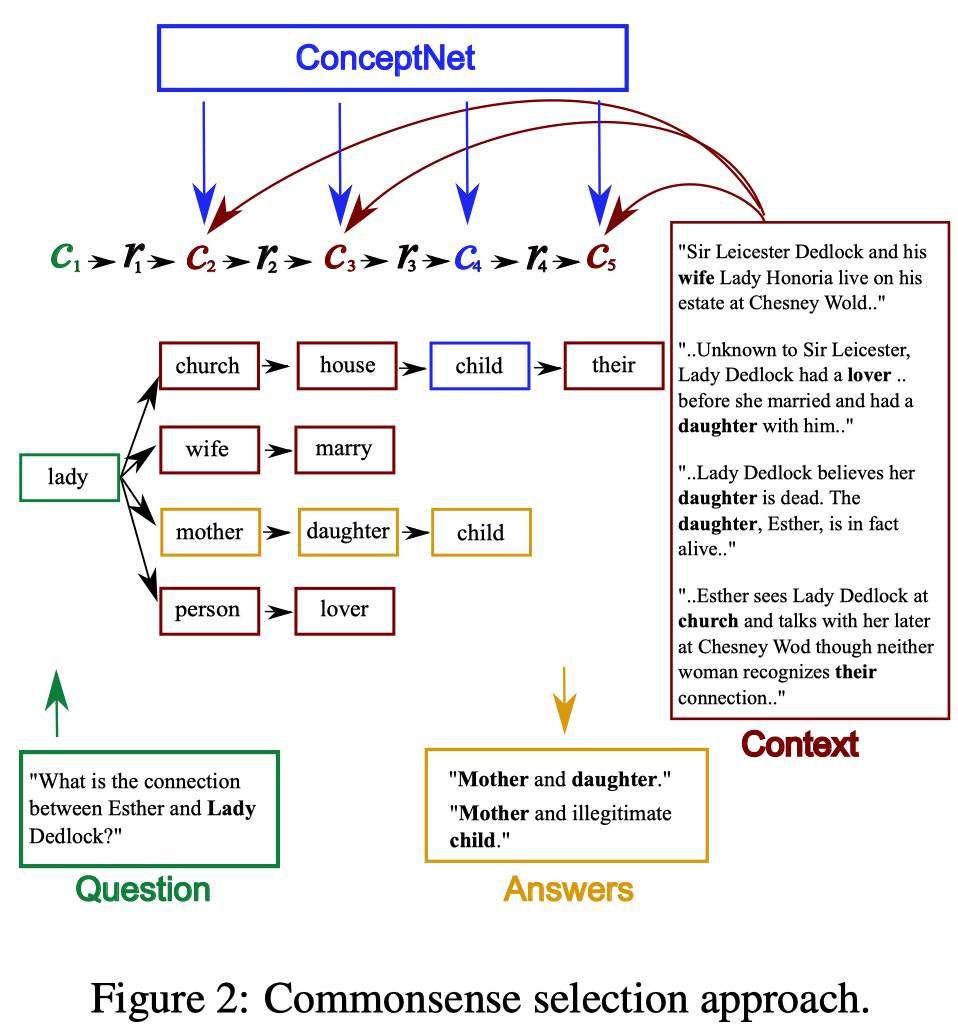
2.1.Tree Construction
树的根节点为query中的一个词, 通过一些分支操作来构建多步推理路径.针对问题中的一个词/concept $c_1$, 进行如下操作:
- Direct Interaction:方向交互
- 从ConceptNet中选择与$c_1$和文本上下文中concept( $c_2 \in C$ )有直接链接的关系$r_1$(多个)
- 例如图中的第一列
- Multi-Hop
- 继续在ConceptNet中选择文本中另外的concept($c_3 \in C$)与$c_2$有链接的关系$r_2$
- Outside Knowledge
- 无文本上下文的约束,寻找收集外部知识
- 在ConceptNet中通过关系$r_3$寻找$c_3$的邻居(one-hop)得到 $c_4 \in nbh(c_3)$
- Context-Grounding
- 再次利用context进行约束, 来确保3中额外的知识是对任务有帮助的
- 即, 使$c_3$通过$c_4$可找到的二阶邻居$c_5 \in C$是在文本中出现的
- 这构建路径的过程中,有几点疑问:
- a. 如果针对一个query中的concept无法查找到这么长的路径如何处理?
2.2.Rank and Filter
在构建树的过程中, 会收集大量的潜在相关路径, 相应地会引入很多噪声以及与问题无关的路径, 所以需要对2.1中收集到的知识路径进行排序过滤掉噪音.
- Initial Node Scoring:
- 初始化节点分数
- 选择有节点可以提供对context的理解的重要信息的路径
- 使用 tf 来估计context中concept的重要度和显著度:
- $score(c) = \frac{count(c)}{|C|}, c \in \lbrace c_2,c_3,c_5 \rbrace$
- 对于outside Knowledge选择出来的节点$c_4$, 希望它与推理路径中的$c_1$到$c_3$保持逻辑一致性
- 利用点互信息
- 由于PMI对low-frequency敏感, 改进为 normalized PMI
- $score(c_4) = PMI(c_4, c_{1-3}) / (-log\mathbb{P}(c_4,c_{1-3}))$
- 由于每个连接分支代表了one-hop,所以不同层级的hops或者是拥有不同父节点的nodes无法与其他节点相比较, 最终对每个节点的打分进行归一化:
- 在同级(siblings)节点中进行归一化
- $n-socre(c) = softmax_{siblings(c)}(score(c))$
- Cumulative Node Scoring
- 累积节点打分
- 选择多跳的Commonsense路径中有相关信息的,根据节点以其子节点的相关性和显著性对节点进行再次打分
- 采取bottom-up的累积计算方式
- 对于叶子节点(leaf node):
- $c-socre = n-score$
- 对于非叶子节点
- $c-score(c_l) = n-socre(c_l) + f(c_l)$
- $f(c_l)$是该节点的$c-socre$打分top-2的子节点的$c-score$平均分值
- Path Selection
- 路径选择
- 采取top-down breath-first(广度优先)的方式选择路径
- 从根节点(回顾: query中的一个concept)开始, 递归的选择其两个具有最高累计得分的子节点, 直到选择到叶子节点.
- 选择路径数: $2^4=16 paths$
- 路径直接以token序列的方式传给模型
3.Commonsense Model Incorporation
有选择性的结合需要的知识,使用常识知识来弥补推理步之间的gaps.
提出 Necessary and Optional Information Cell (NOIC) 一种 selectively gated 注意力机制。
输入:以词序列的形式表示给定的 list of commonsense logic paths:
- $X^{CS} = {w_1^{CS}, w_2^{CS},…,w_l^{CS}}$
- $w_l^{CS}$表示构成一条路径的token序列
- 使用词向量表示: $e_{ij}^{CS}\in \mathbb{R}^d$
NOIC 是基于 Baseline Reasoning Cell 的扩展:
- 在第 $t$ 个推理步, 得到 baseline reasoning cell 的输出之后, 为Commonsense信息计算cell-specific表示:
- 将Commonsense paths上的所有向量串接, 每条路径得到一个表示向量$u_i^{CS}$
- 通过映射进行降维, 使维度与 $c_i^t$ 的维度相等
- $v_i^{CS} = ReLU(W u_i^{CS} + b)$
- 利用attention机制使Commonsense与context之间进行交互:
- 最后, 将Commonsense-aware的context表示和baseline reasoning cell的结果进行组合得到NOIC的输出
- 通过这种方式做到在每一个推理步对知识进行有选择的结合
- 在第 $t$ 个推理步, 得到 baseline reasoning cell 的输出之后, 为Commonsense信息计算cell-specific表示:
Experiments
Results
Ablations
- Model Ablations
- Commonsense Ablations
- Commonsense Selection
Summary & Analysis
TBA