本文将介绍 两篇 关于利用常识知识进行可控地文本生成的论文,都是清华大学黄民烈老师组的研究工作:
Commonsense Knowledge Aware Conversation Generation with Graph Attention. IJCAI,2018.
Story Ending Generation with Incremental Encoding and Commonsense Knowledge. AAAI,2019.
相比于文本生成问题,我更关注怎样将常识知识引入到文本的理解,即编码过程。
1.CS Know. to Dialogue with GAT
这篇文章的主要目的是利用大规模的常识知识帮助对话的理解与生产。
在对话任务中,给定一个用户 post:
- 在编码端:采取静态策略
- 从(常识)知识库中抽取出与 post 相关的知识子图
- 在编码端知识子图是静态的,包含与 post 相关的信息
- 用 Graph Attention(GAT) 机制进行编码
- 在解码端:采取动态策略
- 有关注的读取 Knowledge Graph 以及 Knowledge Graph 中的知识三元组
- 文章中强调了一点:与已有的其他模型(分开、独立使用 knowledge triples/entities)不同,此模型将每个 knowledge graph 作为一个整体进行处理,可以编码更多的结构信息以及有关联的语义信息。
模型的整体结构: 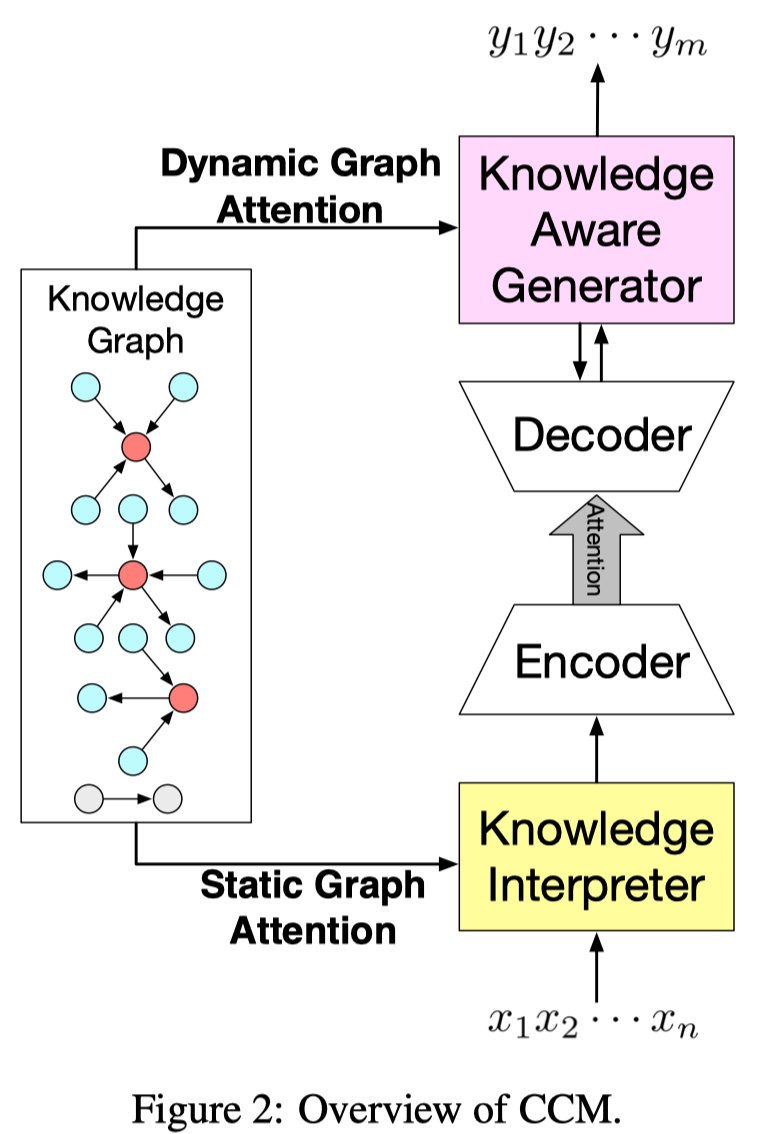
Task Definition and Overview
- user post(input): $X=x_1 x_2 … x_n$
- some commonsense knowledge graphs: $G={g_1, g_2, …, g_{N_G}}$
- desired response(output): $Y=y_1 y_2 … y_m$
- 使用 post 中的每个词作为查询,去常识知识库中 为每个词抽取出一个对应的子图:
- eg: 对于 post $X=x_1 x_2 … x_n$, 其对应的抽取出来的图是 $G={g_1, g_2,…,g_{N_G}}$
- 每个子图由一个三元组集合构成: $g_i = {\tau_1, \tau_2, …, \tau_{N_{g_i}}}$
- 每个三元组(head entity, relation, tail entity): $\tau = (h,r,t)$
- 使用 TransE 来表示 KG 中的实体和关系;
- 最终每个三元组 $\tau$ 表示为:
- $k = (h,r,t) = MLP(TransE(h,r,t))$
- $h/r/t$ 为各自的 TransE Embedding
- 使用 $MLP$ 是为了缩小 知识库 和 无结构对话文本 之间的 表示差距(bridge the representation gap)
- $k = (h,r,t) = MLP(TransE(h,r,t))$
- 对于在知识库中没有检索到匹配的词,使用一个特殊的
Not_A_Fact来表示
Knowledge Interpreter
Knowledge Interpreter overview: 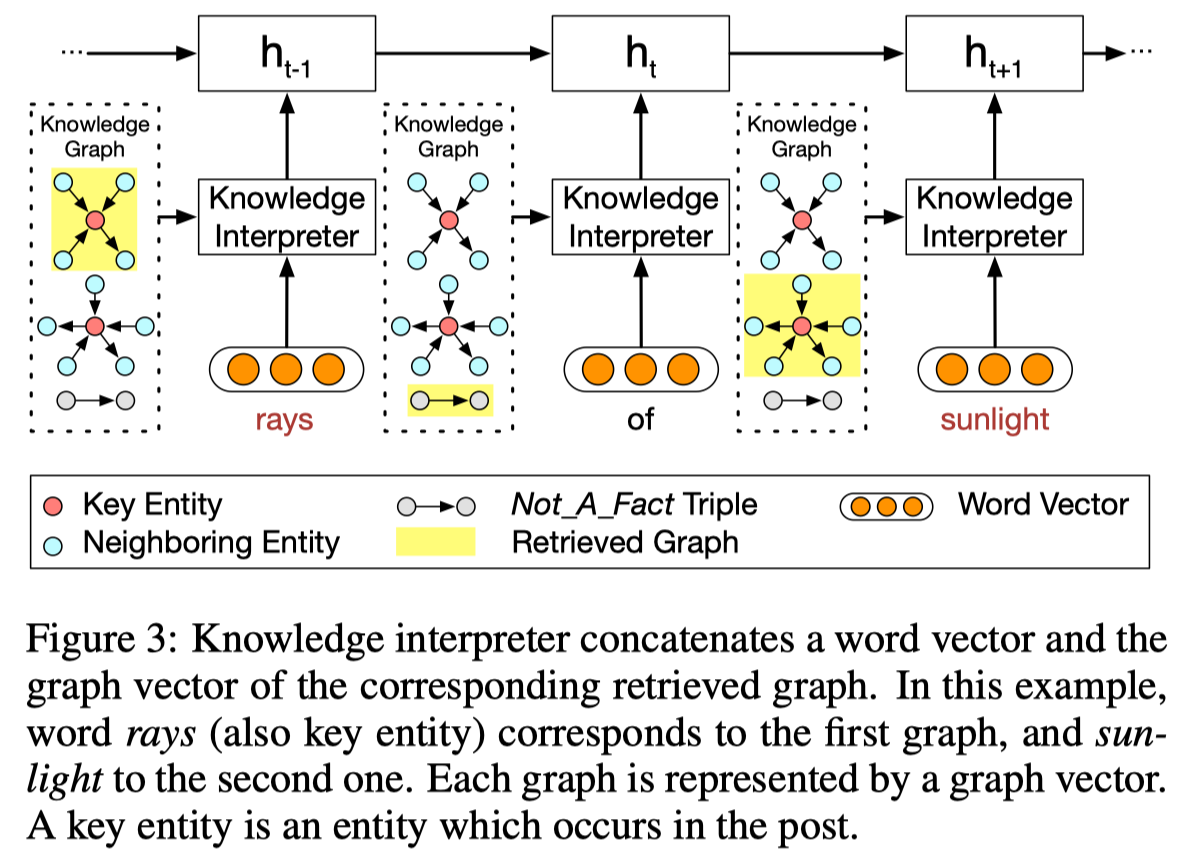
- 知识感知的词表示: $e(x_t) = [w(x_t);g_i]$
- Knowledge Interpreter 的主要目的是用每个词对应的知识子图向量来增强词表示
- 使用 post 中的每个词 $w_t$ 作为 key entity (红色点)去抽取出一个子图 $g_i$ (上图中黄色的部分)
- knowledge interpreter 的输出为静态图注意力机制计算得到的 graph vector $g_i$
- Static Graph Attention
- 使用功能 GAT 的好处是:不仅可以编码结构语义信息还可以考虑到图中节点间的关系
- SGA 的输入: knowledge triple vectors
- SGA 的输出: knowledge graph vector
- 其中, $(h_n, r_n, t_n) = k_n$
- (Note: 在原始的GAT中没有引入relation向量计算attention的score)
2.CS Know. to Story Ending Generation
这篇文章的主要目的是生成连贯、合理且有逻辑的故事结尾。
- 故事例子:故事与知识的关联
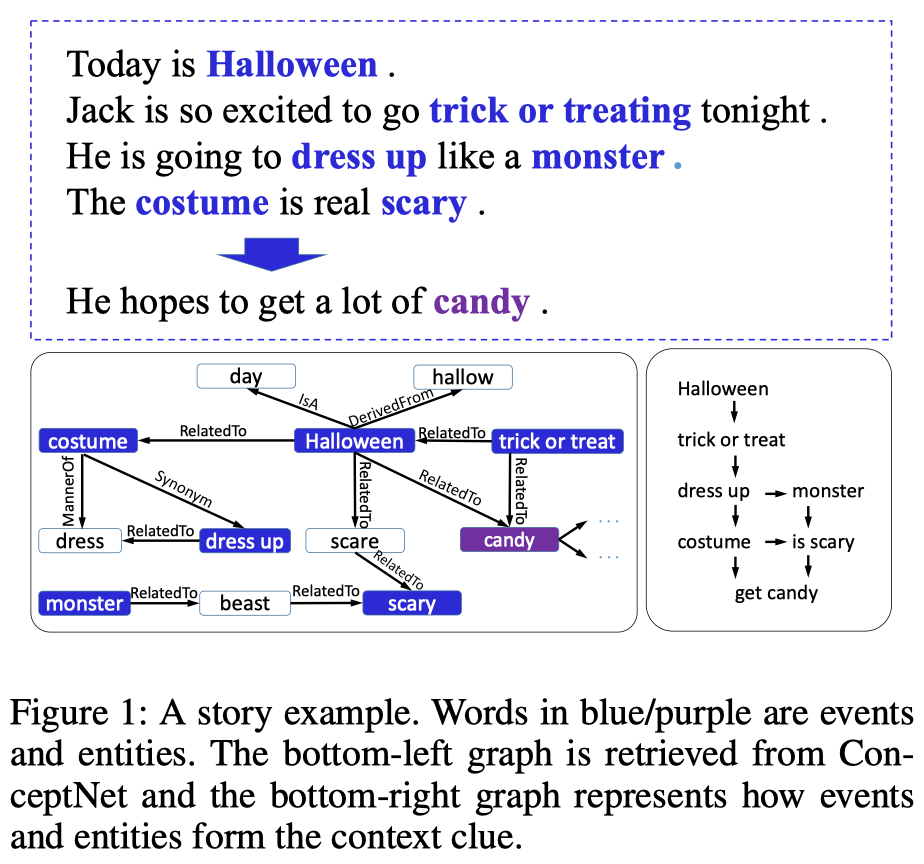
动机:
- 为故事生成一个合理的结尾需要对故事有很强的理解,需要以下两个方面
- Context Clues:故事的逻辑、因果关系以及时序依赖(logic/causality/chronological order)通常跨越多个句子,通过句子中的事件/实体序列来获取;
- Implicit/Commonsense Knowledge:超越文本表明信息的隐含知识
针对以上的需求/目的,本文提出了:
- Incremental Encoding Schema:表示文本线索
- 逐句编码
- Multi-Source Attention:帮助故事理解,充分利用常识知识
- 为每个词抽取一个 one-hop Knowledge graph,计算graph的表示
- 在编码当前句子时,不仅对前一个句子中的每个词的上下文表示进行Attention,还对每个词的KG进行Attention
Overview
模型的整体结构: 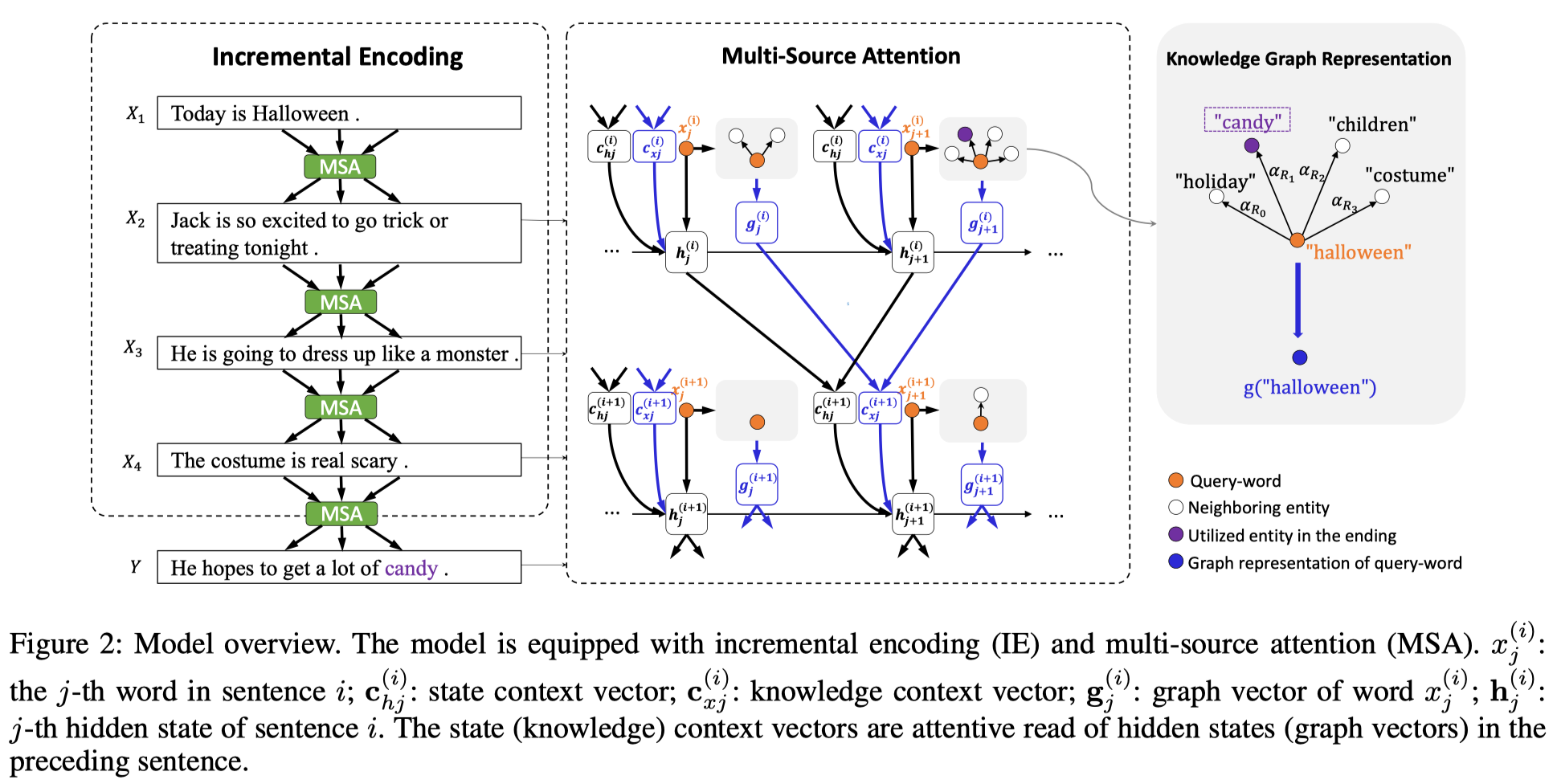
Incremental Encoding Scheme
最直接的对故事进行上下文编码的方法有:
- 将所有的句子进行串联,构成一个长句子,然后用LSTM进行计算
- 使用带有 Hierarchical-Attention 的层次LSTM
- 但是这两种都不能够有效的表示上下文的线索信息,相邻句子中事件/实体的时序顺序(chronological order)和因果关系(causal relationship)
本文提出的增量编码模式:编码当前句子 $X_i$ 中的第j个位置的隐状态计算如下
- $h_j^{(i)} = LSTM(h_{j-1}^{(i)}, e(x_j^{(i)}), c_{lj}^{(i)}), i>2$
- 其中,$e(\cdot)是词向量$, $c_{lj}^{(i)}$ 是关于前一个句子的上下文向量(基于隐状态$h_{j-1}^{(i)}$)
Multi-Source Attention
通过多源Attention来获取上下文向量表示文本线索信息,由两部分组成:
- $c_{lj}^{(i)} = W_l( [c_{hj}^{(i)} ; c_{xj}^{(i)}] ) + b_l$
- $c_{hj}^{(i)}$ 是 state context vector,即前一个句子隐状态的权重和
- $h_k^{(i-1)}$ 前一个句子第k时刻的隐状态
- $c_{xj}^{(i)}$ 是 knowledge context vector, 即前一个句子的知识表示权重和
- $g(x_k^{(i-1)})$ 是前一个句子中第k个词的graph vector
- $h_{j-1}^{(i)}$ 是第i个句子中的第j个位置的隐状态,即当前句子中的前一时刻的隐状态
Knowledge Graph Representation
对知识图编码有两种方式:
- graph attention
- contextual attention (knowledgeable-reader)
针对词$x$抽取(以$x$为头实体)出的图: $G(x) = {R_1,R_2, …,R_{N_x}}$
$R_i$ 为知识三元组 $(h,r,t)$, 用词向量表示h/t, r向量作为参数进行学习;
$N_x$ 为 $x$ 的邻居数量;
Graph Attention 的图表示方式
Contextual Attention 的图表示方式
- $h_{(x)}$ 是词$x$的隐状态
CS Know. Process
对于常识知识的抽取方式以及和数据的融合方式
- CCM中:
- 实体和关系的向量通过transE进行学习,维度均为100
- 去除了由多个词构成的头/尾实体
- 最终的数据量:
- 三元组:120850
- 实体数:21471
- 关系数:44
- StoryEndGen中:
- 只抽取出one-hop的三元组
- 为每个词抽取最多10个三元组;
- 头/尾实体为名词(noun)或动词(verb)
- 最终的数据量:
- 关系数:45
- 三元组:16652
- 两篇论文都是直接给出了处理好的数据,并没有给出数据的预处理过程,github链接分别为: