MOSAIC 是 AI2 (ALLEN Institute for Artificial Intelligence) 研究院中进行机器常识智能研究的小组[1].
现有的研究项目:(Update at July, 2019)
- Commonsense Knowledge Graphs: Exploring semi-structured representations of commonsense.[2]
- Visual Commonsense Reasoning: 视觉常识推理项目[3]
- Mosaic Commonsense Benchmarks: Measuring progress on Machine Common Sense.[4]
对应的主要Papers:
- ATOMIC: An Atlas of Machine Commonsense for If-Then Reasoning. AAAI,2019.
- From Recognition to Cognition: Visual Commonsense Reasoning
- SWAG: A Large-Scale Adversarial Dataset for Grounded Commonsense Inference. EMNLP,2018.
其他Papers:
- Event2Mind: Commonsense Inference on Events, Intents, and Reactions. ACL,2018.
- Modeling Naive Psychology of Characters in Simple Commonsense Stories. ACL,2018.
- Reasoning about Actions and State Changes by Injecting Commonsense Knowledge. EMNLP,2018.
重点关注 Commonsense Knowledge Graphs 这部分的工作
Commonsense Knowledge Graphs
- Event2Mind: Commonsense Inference on Events, Intents, and Reactions. ACL,2018.
- ATOMIC: An Atlas of Machine Commonsense for If-Then Reasoning. AAAI,2019.
Event2Mind
常识推理任务
推理类型:2类(语用推理 pragmatic inference)
intent 意图
- 可以解释为什么施事者导致事件发生,是行动或事件的心理前提
emotional reaction 情绪反应
- 反应定义为解释施事者和参与事件的其他人的心理状态将如何因此改变
- 反应可以被认为是一种行为或事件的心理后置条件
任务目标:给定一个 event phrase,预测 X intent / X reaction / Y reaction
- pre-condition: X intent
- post-condition: X/Y reaction
例子:
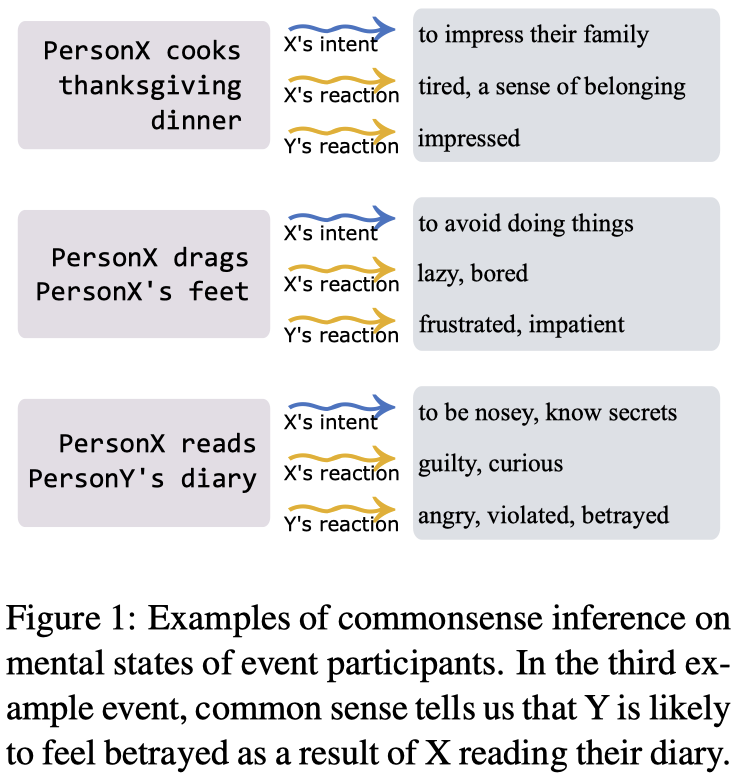
ATOMIC
关于 if-then 推理类型的推理知识库(Knowledge base about inferential knowledge on if-then reasoning types)
- 例子:
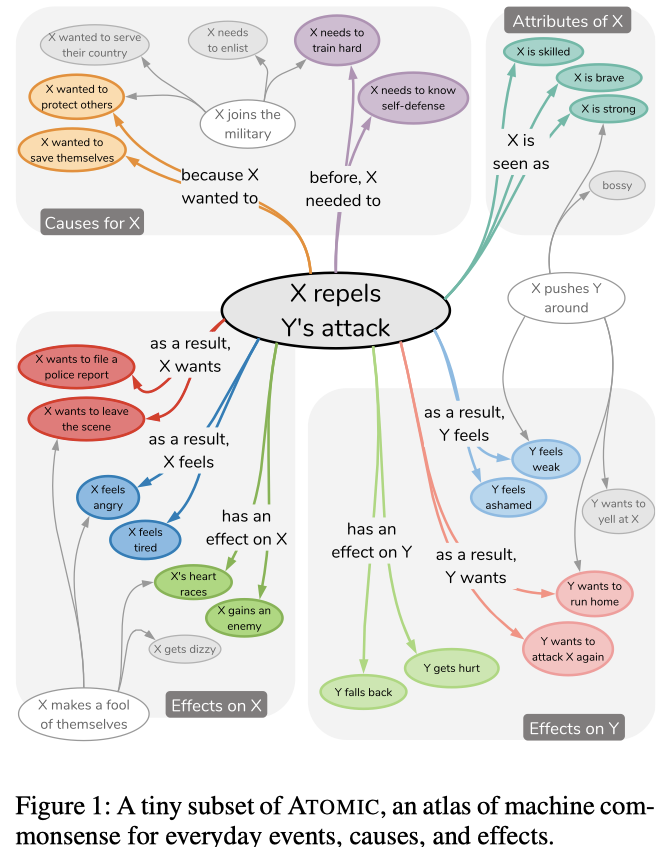
nine if-then relation types to distinguish: (不同上不全面的刻画维度)
- cause vs. effect
- [Xintent,Xneed] vs. [Xwant,Xreaction,Effect on X,Effect on Y,Ywant,Yreaction]
- agents vs. themes:agent(X,who cause the event),themes(Other)
- [Xintent,Xneed,Xwant,Xreaction,Effect on X, Xattribute] vs. [Effect on Y,Ywant, Yreaction]
- voluntary vs. involuntary events
- [Xintent,Xneed,Xwant,Ywant] vs. [Xreaction,Effect on X,Effect on Y,Yreaction,Xattribute]
- actions vs. mental states
- [] vs. []
- dynamic vs. static
- [Xintent,Xneed,Xwant,Xreaction,Effect on X,Effect on Y,Ywant,Yreaction] vs. [Xattribute]
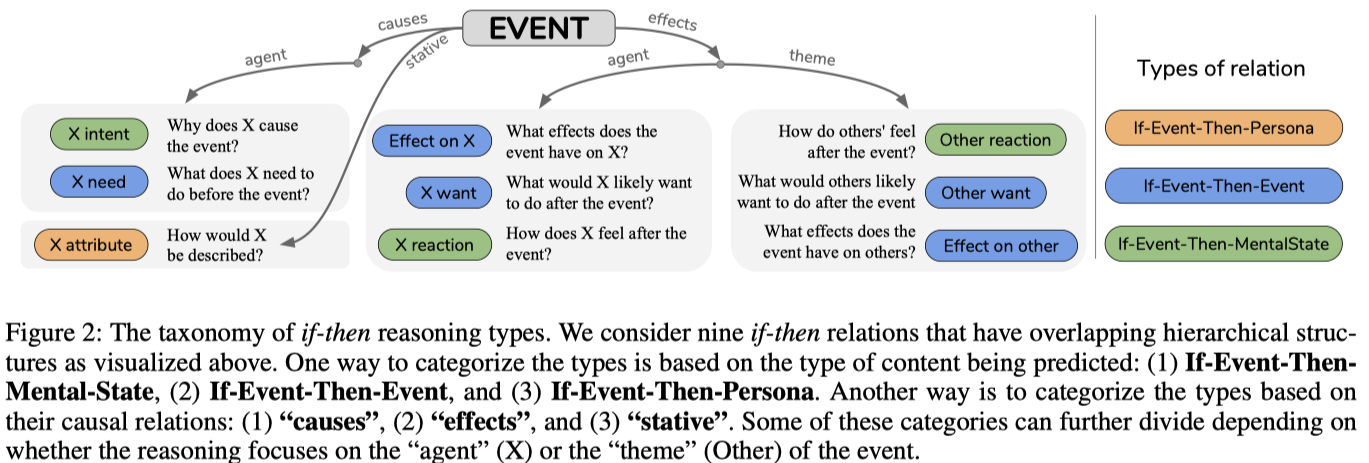
taxonomy of if-then reasoning types:
- based on the content being predicted:
- **if-event-then-mental-state** * mental pre-/post- conditions of an event * 3 relations: **X inent/ X reaction/ Other reaction**
- **if event-then event** * events that constitute probable pre- and postconditions of a given event * 5 relations: **X need/ X want/ Effect on X/ Other want/ Effect on Other**
- **if event-then-person** * a stative relation that describes how the subject of an event is described or perceived * 1 relations: **X attribute**
- based on their causal relations
- causes(因)
- effect(果)
- stative(状态)
- 图例:
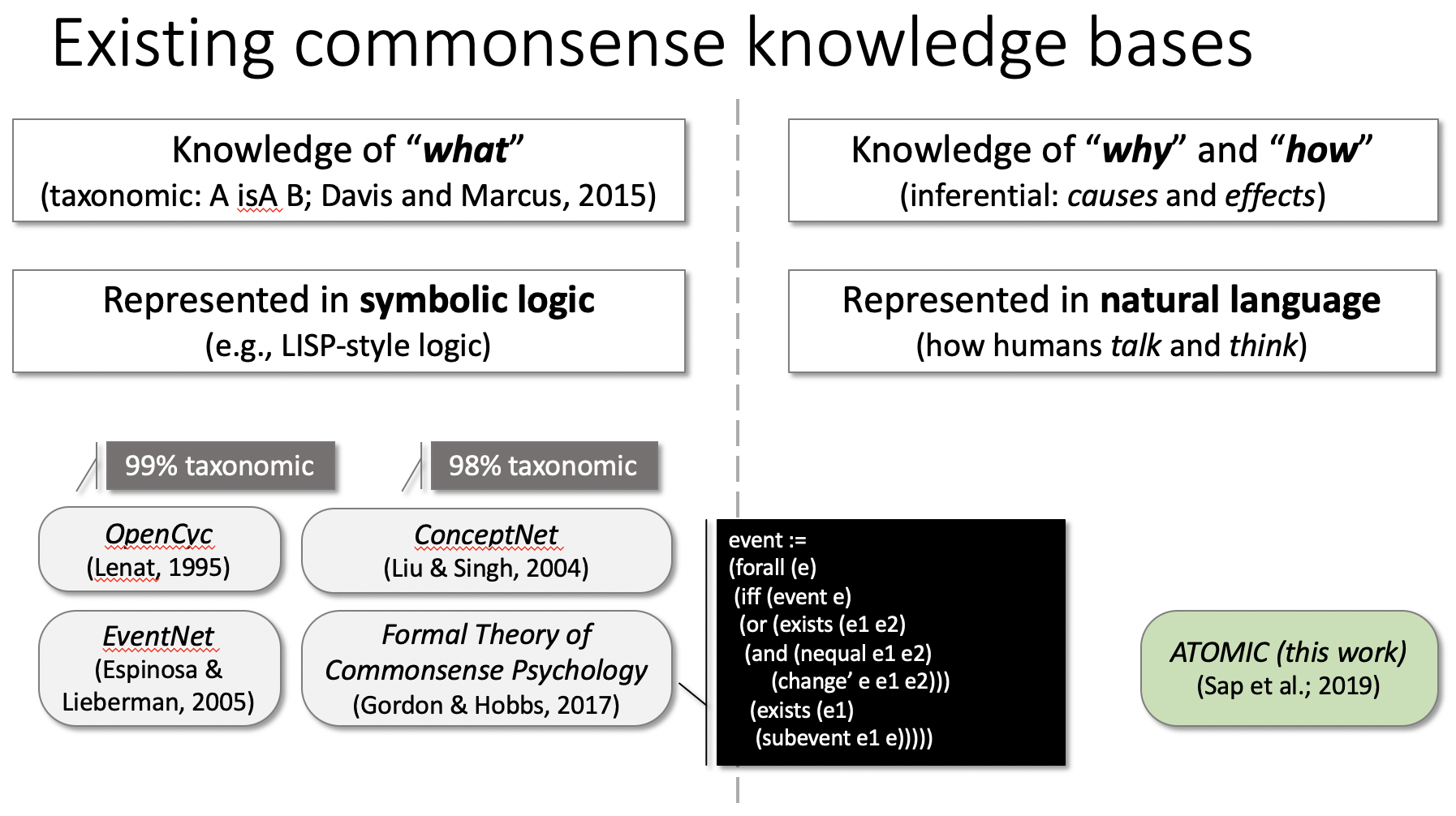
与现有knowledge base的对比:
DARPA Leaderboards
Abductive Natural Language inference (alpha NLI)
- Abductive Natural Language Inference (αNLI) is a new commonsense benchmark dataset designed to test an AI system’s capability to apply abductive reasoning and common sense to form possible explanations for a given set of observations.
- Formulated as a binary-classification task, the goal is to pick the most plausible explanatory hypothesis given two observations from narrative contexts.
- Abduction is the process of inference to the best explanation for a given set of observations
- Humans often use commonsense knowledge to perform abductive inference
- For example, if a person observes wet grass, they’d infer that it probably rained. But, with additional knowledge that it has been sunny for many days, the might infer that the sprinklers were probably on.
- As defined by the philosopher Charles Sanders Peirce(in 1903), abduction is:
- the process of forming explanatory hypotheses given some observations
- Several Datasets have been proposed recently to tackle the task of inference in natural language, but they captures deductive inferences
- i.e. they hypothesis is necessary to have occurred if the premise is true
- Abductive inference a ampliative in nature and the inferences made acts as one of the possible explanations for the given set of observations, which further need to be explored/tested.
Example
Each instance in the dataset takes the form of a simple story. Given the beginning and the ending of a story, the task is to choose a more likely hypothesis between two given choices.
Obs1: Jenny was addicted to sending text messages.
Obs2: Jenny narrowly avoided a car accident.
Hyp1: Since her friend’s texting and driving car accident, Jenny keeps her phone off while driving.
Hyp2: Jenny was looking at her phone while driving so she wasn’t paying attention.
correct: Hyp2
- human performance:92.9%
HellaSwag: Can a Machine Really Finish Your Sentence?
- HellaSWAG is a dataset for studying grounded commonsense inference.
- It consists of 70k multiple choice questions about grounded situations: each question comes from one of two domains — activitynet or wikihow — with four answer choices about what might happen next in the scene. The correct answer is the (real) sentence for the next event; the three incorrect answers are adversarially generated and human verified, so as to fool machines but not humans.
Example
A woman is outside with a bucket and a dog. The dog is running around trying to avoid a bath. She
- a) rinses the bucket off with soap and blow dries the dog’s head.
- b) uses a hose to keep it from getting soapy.
- c) gets the dog wet, then it runs away again.
- d) gets into the bath tub with the dog.
correct: (c)
- human performance:95.6%
Physical IQa: Pyhsical Interaction QA
- for naive physics reasoning focusing on how we interact with everyday objects in everyday situations.
- focuses on affordances of objects, i.e., what actions each physical object affords (e.g., it is possible to use a shoe as a doorstop), and what physical interactions a group of objects afford (e.g., it is possible to place an apple on top of a book, but not the other way around).
- The dataset requires reasoning about both the prototypical use of objects (e.g., shoes are used for walking) and non-prototypical but practically plausible use of objects (e.g., shoes can be used as a doorstop).
- The dataset includes 20,000 QA pairs that are either multiple-choice or true/false questions.
Example
You need to break a window. Which object would you rather use?
- a) a metal stool
- b) a giant bear
- c) a bottle of water
correct: (a)
- human performance:94.9%
Social IQA: Social Interaction QA
- for testing social commonsense intelligence.
- Contrary to many prior benchmarks that focus on physical or taxonomic knowledge, Social IQa focuses on reasoning about people’s actions and their social implications.
- For example, given an action like “Jesse saw a concert” and a question like “Why did Jesse do this?”, humans can easily infer that Jesse wanted “to see their favorite performer” or “to enjoy the music”, and not “to see what’s happening inside” or “to see if it works”.
- The actions in Social IQa span a wide variety of social situations, and answer candidates contain both human-curated answers and adversarially-filtered machine-generated candidates.
Social IQa contains over 37,000 QA pairs for evaluating models’ abilities to reason about the social implications of everyday events and situations.
Types of reasoning:
- Motivation
- What Happens Next
- Emotional Reaction
Example
In the school play, Robin played a hero in the struggle to the death with the angry villain. How would others feel as a result?
- a) sorry for the villain
- b) hopeful that Robin will succeed
- c) like Robin should lose the fight
correct: (b)
- human performance:88.1%