Multi-Granular Sequence Encoding via Dilated Compositional Units for Reading Comprehension
EMNLP 2018
Yi Tay et al.
多粒度/尺度序列编码; 膨胀组合单元
Motivation
- Sequence encoder是MRC中的重要部件: helps to model compositionality of words, capturing rich and complex linguistic and syntactic structure in language
- Sequence encoder的问题:
- 文档较长,文档数多时计算开销大;
- 限制获取长距离上下文;
- 限制了多句和文档内部的推理;
- 本文工作: 采取组合式编码方式
- 主要思路是将多个尺度的信息组合在一起进行编码,利用多尺度 n 元语法信息来实现语义融合,得到更好的文档表达,用于后续的推理和Attention操作.
- 设计了一种 dilated compositions 机制来建模多个尺度之间的关系,相当于通过门控的方式决定要保留多少信息
- 多尺度 包括:word-level、phrase-level、sentence-level、paragraph-level etc.
- 一种 divide-and-conquer 的序列编码方式
- 本文贡献:
- 提出了一个 compositional encoder DCU (Dilated Compositional Units), DCU 既可以进行独立编码,也可以以RNN-style的方式进行更有表示能力的编码;
- DCU 可以加速序列编码速度,并且保持相邻词之间的交互关系;
- 建模长句子时,模型可以获得前方更多的信息,是对所有上下文的全局概览;
- 相当于一个门控单元对不同粒度的关系进行建模,有利于捕获文档内部细粒度关系;
Model
- DCU用于MRC时的整体结构,左侧为DCU Encoder,右侧为DCU分别用于span prediction model和Multiple choice model的结构:
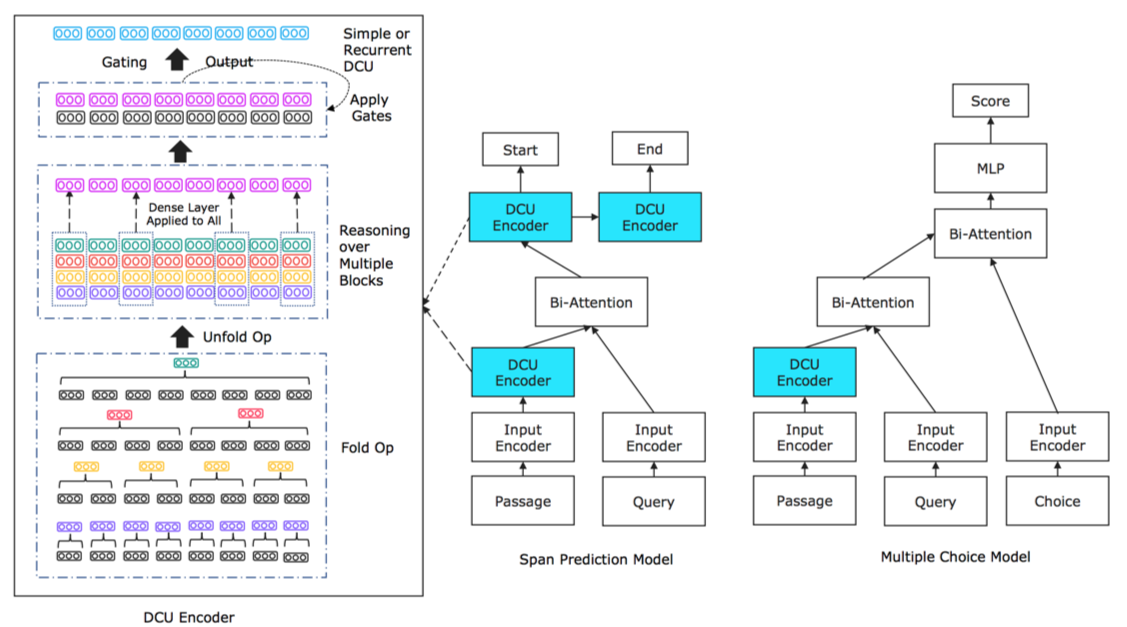
本节只介绍 DCU 的操作和 encoding 操作,不对整体的mrc模型进行介绍
Dilated Compositional Mechanism
Notations:
- Input Sequence: $S=[w_1, w_2, …, w_l]$
- Range list: $R={r_1, r_2, …, r_k}$
- $k$ 表示进行 $k$ 次 fold/unfold 操作
1.Fold
对于每个 $r_j$:
- 将$S$中的每 $r_j$ 个词进行串接(concat, neural bag-of-words 表示), 原输入长度缩减为 $l/r_j$
- 对于新得到的、包含 $l/r_j$ 个 tokens/blocks 的序列中的每个表示进行如下计算:
- $\bar{w}_t = \sigma_r(W_a(w_t)) + b_a$
- $W_a \in \mathbb{R}^{d\times d}, b\in \mathbb{R}^d$
- Fold 的操作次数等于 range list 的大小
- 对于 range list 中不同的 $r$ 值, 参数 $W_a$ 和 $b_a$ 不共享
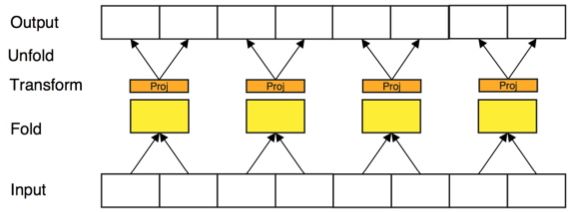
2.Unfold
将transformed之后的序列展开为原长
- 下图中为 $r_j=2$ 时的 Fold-Unfold 操作:
3.Multi-Granular Reasoning
多尺度推理
- 将不同尺度的unfold之后的token表示进行串接,然后通过两层前馈神经网络得到一个门向量
- $g_t = F_2(F_1([w_1^t,w_2^t,…,w_t^k]))$
- $F(\cdot) = ReLU(Wx+b)$
- $g_t$ 相当于一个从多尺度中学习的门控向量,尺度值最低的那些词会拥有相同的 $g_t$ 值
Encoding Operation
1.Simple Encoding
- $z_t = tanh(W_p w_t) + b_p$
- $y_t = \sigma(g_t) \ast w_t + (1-\sigma(g_t))z_t$
2.Recurrent Encoding
DCU 相当于循环神经网络中的 cell
- $c_t = g_t \odot c_{t-1} + (1-g_t)\odot z_t$
- $o_t = W_o(w_t) + b_o$
- $h_t = o_t \odot c_t$
问题:
此处有一点疑问是,为什么通过DCU得到的门控向量 $g_t$ 没有参与到后续的编码过程, 而只是作为了控制初始 $w_t$ 词向量的门控输入
Experiment
Implementation Details
- Multi-Choice 模型:
- 数据输入: include the standard EM (exact match) binary feature to each word. In this case, we use a three-way EM adaptation, i.e., EM(P, Q), EM(Q, A) and EM(P, A). The projected embeddings are then passed into a single layered highway network
- 输出(答案选择层): 将每个候选答案的答案向量转化为标量
- $a_j^f=softmax(W_2(\sigma_r(W_1([a_j])+b_1)+b_2))$
- range valuse: ${1,2,4,10,25}$
- 最大序列长度 (RACE/SearchQA/NarrativeQA): $500/200/1100$
Results
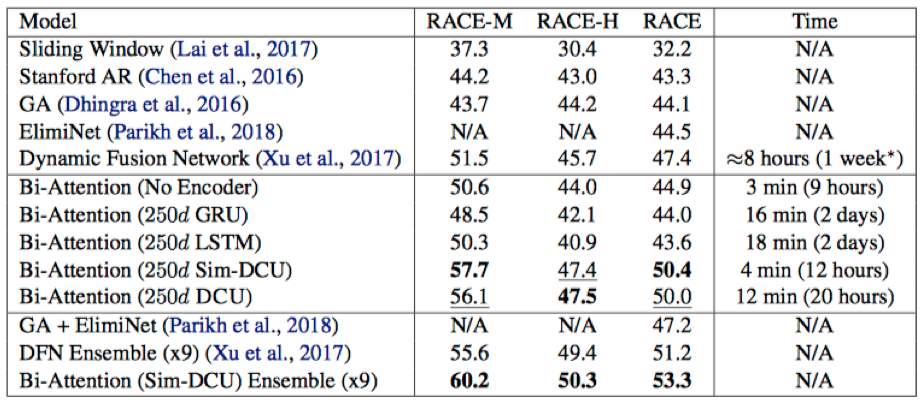
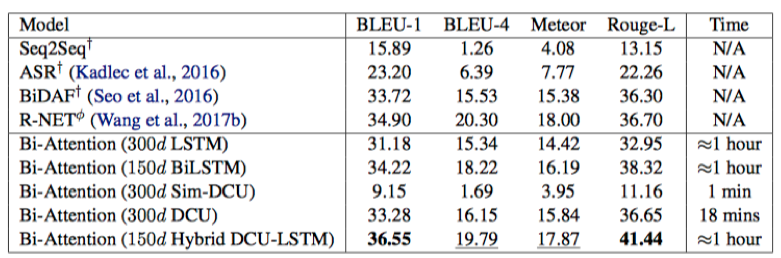
只关注了一下RACE和NarrativeQA上的结果,在没有使用RNN-based编码器的情况下,取得了不错的效果,在论文完成时(2018.03)是RACE上的top-1
RACE
NarrativeQA
Summary & Analysis
- 对于长文本的编码问题是MRC中的重点问题之一【—>表示问题】
- 长文本和多篇文本
- 本文提供了一种跨尺度的交互,或是融合跨尺度的信息的有效方式