Neural Natural Language Inference Models Enhanced with External Knowledge
ACL,2018.
Qian Chen, et al.
offical code link: here.
Motivation
作者针对NLI任务提出了一个问题:
- 是否可以从数据中学习NLI所需要的所有知识?
- 如果不能,如何使外部知识帮助神经网络模型?如何构建NLI模型利用外部知识?
本文的工作是作者基于其ESIM模型之上完成的
Model Framework
- 模型整体结构分为四部分:
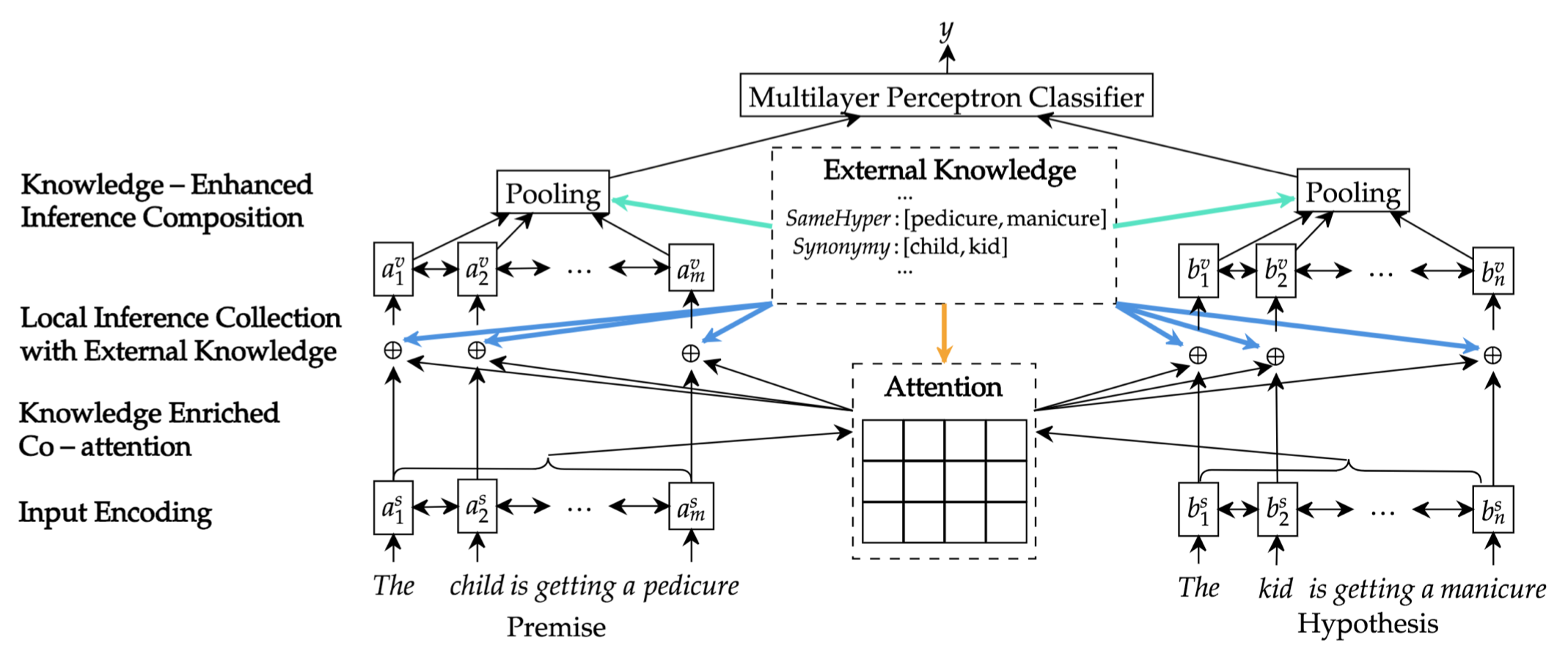
- 1、representing
- 2、collecting local inference information
- 3、aggregating and composing local information
- 4、make global decision at sentence level
- 其中,将外部知识加入到了: co-attention、local inference collection、inference composition 模块中
External Knowledge
首先确定需要哪些知识来帮助NLI任务
- external, inference-related knowledge
- intuitively Knowledge: synonymy(同义)、antonymy(反义)、hypernymy(上位)、hyponymy(下位)
- 上下位的关系可以帮助捕捉 entailment 信息
- 反义和co-hyponymy(共享相同上位词)的关系可以更好的建模 contradiction 关系
- 这篇文章主要是引入了基础的词汇级的语义知识
- 建模词$w_i$和$w_j$知识为 $r_{ij}$
- 重点是:如何构建 $r_ij$
M1.Encoding Premise and Hypothesis
- premise: $a=(a_1,…,a_m)$
- hypothesis: $b=(b_1,…,b_n)$
- 通过BiLSTM进行编码,得到context-dependent 隐藏状态:
- $a_i^s = Encoder(E(a),i)$
- $b_j^s = Encoder(E(b),j)$
M2.Knowledge-Enriched Co-Attention
- 知识关系特征:$r_{ij} \in \mathbb{R}^{d_r}$
- Co-attention:
- $e_{ij} = (a^s_i)^T b_j^s + F(r_{ij})$
- $F(r_{ij}) = \lambda \mathbb{1}(r_{ij})$
- $\mathbb{1}(r_{ij})$ 判断 $r_{ij}$ 是否为0向量
- 得到的 co-attention 矩阵 $e \in \mathbb{R}^{m\times n}$
- 根据co-attention对premise和hypothesis的表示进行更新:
- $\alpha \in \mathbb{R}^{m\times n}$、$\beta \in \mathbb{R}^{m\times n}$
M3.Local inference Collection with External Knowledge
- 通过比较$a_i^s$、$a_i^c$ 和 他们的关系(从外部知识获得),可以获得词级的推理信息
- Knowledge-enriched local inference:
- 最后一项的目的是:收集对齐词之间的关系特征,是从外部知识获得的word-level inference information
- $G$ 是非线性映射,用于降维,relu + shortcut connection
M4.Knowledge-Enhanced Inference Composition
- 决定总体的推理关系:BiLSTM —> mean;max;weighted Pooling,得到定长向量
- Composition = BiLSTM
- $a_i^v = Composition(a^m,i)$
- $b_j^v = Composition(b^m,j)$
- Weighted Pooling
- $H$ 函数是 1层的前馈神经网络,激活函数是relu
- Composition = BiLSTM
- 最后得到定长向量之后,再过一层MLP,激活函数为tanh,和一层 softmax,得到分类结果
Experiment Settings
Representation of External Knowledge
Lexical Semantic Relations
- relations of lexical pairs: 检索范围是wordnet
- synonymy: 如果词对是同义词,使值为1,否则为0
- antonymy: 如果词对是反义词,使值为1,否则为0
- hypernymy: 如果一个词是另一个词的上位词,取值 $1-\frac{n}{8}$,否则为0
- 其中 $n$ 是两个词在层次上的边数
- 忽略边数超过8的
- hyponymy: inverse of the hypernymy feature
- co-hyponymys: 如果两个词有相同的上位词且不是同义词,取值为1,否则为0
- 向量 $r$ 的维度为 $d_r = 5$
- 在 wordnet 中还有额外的一些(15种)关系,但是对结果的提升没有贡献
- relation embeddings
- pretrain based on wordnet
- TransE